前の10件 | -
beagleboard を触ろう - CPU キャッシュ [組み込みソフト]
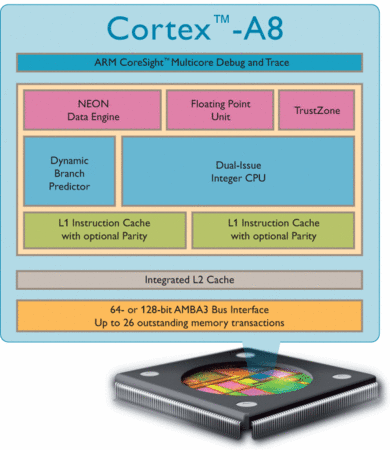
Cortex-A8 は、L1 命令キャッシュ、L1 データキャッシュ、命令/データ 共用 の L2 キャッシュを持っています。
それぞれのキャッシュサイズは、コプロセッサー cp15 の Cache Size Identification Register を読み出すことにより、知ることができます。
cp15 のレジスタには、mrc, mcr 命令でアクセスすることができます。
Cache Size Identification Register からは、キャッシュに関するサイズ以外の属性も読み出すことが出来ます。
beagleboard で実際に読み出してみると、以下のようになりました:
※
WT = Write Through サポート
WB = Write Back サポート
RA = Read Allocation サポート
WA = Write Allocation サポート
キャッシュサイズは、セット数 * ウェイ数 * ラインサイズ により算出されます。
例えば L1 命令キャッシュの場合、64 * 4 * 64 = 16384 バイトです。
キャッシュを有効にする方法は、命令キャッシュとデータキャッシュ・統一キャッシュで異なります。
基本的には、Control Register の I ビット、C ビット、Auxiliary Control Register の L2EN ビットが有効/無効を決定するのですが。
命令キャッシュは、I ビットを立てるだけで有効化することができます。
しかし、データキャッシュ・統一キャッシュは、C ビット/L2EN ビットを立てるだけでは有効化できません。
C ビット/L2EN ビットを立てるとともに、MMU も有効にしてやる必要があります。
キャッシュの有効・無効は、次のようなルールに従います:
MMU 稼働の場合
- L1 命令キャッシュは、SCTRL.I ビットの 1/0 によって有効/無効が決まる
- L1 データキャッシュは、SCTRL.C ビットの 1/0 によって有効/無効が決まる
- L2 統一キャッシュは、SCTRL.C ビットが 1 かつ Auxiliary SCTRL.L2EN ビットが 1 の場合は有効、それ以外の組み合わせの場合は無効
MMU 非稼働の場合
- L1 命令キャッシュは、SCTRL.I ビットの 1/0 によって有効/無効が決まる
- L1 データキャッシュは、SCTRL.C ビットの 1/0 によらず、無効になる
- L2 統一キャッシュは、SCTRL.C ビットおよび Auxiliary SCTRL.L2EN ビットの 1/0 によらず、無効になる
※SCTRL = Control Register, Auxiliary SCTRL = Auxiliary Control Register は、コプロセッサー cp15 のレジスタです。
L1 命令キャッシュは、簡単に有効にすることができますが、L1 データキャッシュ、L2 統一キャッシュは MMU を有効化しないと有効にできないので、多少面倒です。
なお、L2 を統一キャッシュと言っているのは、命令データとロード・ストアデータの両方を持つからです。
※
x-loader で、キャッシュはどうなっているかというと、、、
x-loader では、MMU を有効にしていませんので、L1 データキャッシュおよび L2 統一キャッシュは無効です。
L1 命令キャッシュは、有効にしています。
同時に、分岐予測も有効にしています。
MMU を有効にするには、ページテーブルが必要です。
一番簡単なページテーブルは、すべて 16MB のスーパーセクションで構成し、仮想アドレス=物理アドレスとなるようにする構成でしょう。
これだと、4GB のアドレス空間をカバーするのに必要なページテーブルのサイズは、1KB で済みます。
さて、それではこれから、キャッシュの有効化方法、無効化方法について、触れていきます。
きっちりやろうとすると、意外とめんどくさいです。
キャッシュ有効化方法
キャッシュを有効化するには、基本的にはキャッシュ有効化ビットを立てればいいのですが、その前にキャッシュを空にしておく必要があります。
さもないと、キャッシュ中のゴミが、キャッシュ有効後にメインメモリに排出されてしまいます。
キャッシュを空にする動作は invalidate と言いますが、invalidate をどのように行うかがキャッシュ有効化時の考慮点です。
そもそも、L1 キャッシュ、L2 キャッシュともに invalidate する必要があるのかどうか?という点から考えてみる必要があります。
そのために、まず、リセット時にキャッシュがどうなるか、知らなければなりません。
ARM ARM の「B2.2.2 キャッシュの動作 → リセット時のキャッシュの動作」を見てみると、
・すべてのキャッシュはリセット時に非稼働になります。
・実装では、特定のキャッシュ初期化ルーチンを使用して、キャッシュを稼働させる前にその記憶域アレイを無効にすることが必要な場合があります。必要な初期化ルーチンの詳細な形式は実装定義ですが、このルーチンはデバイスのドキュメントの一部として明示的に文書化する必要があります。
とあります。
「デバイスのドキュメント」に相当すると思われる Cortex-A8 TRM を見てみると、L1 キャッシュに関しては、特に初期化に関しての記述はありません。
また、L2 キャッシュに関しても、Auxiliary Control Register の L2EN ビットを立ててから、Control Register の C ビットを立てよ、との記述があるくらいです (8.3 Enabling and disabling the L2 cache controller)。
そこで、さらに OMAP35x TRM を見てみると、
・L2 キャッシュを使用するには、事前に L2 キャッシュのデータをすべて invalidate しなくてはならない
・BootROM コードに、L2 キャッシュを invalidate するサービスを用意しておくので、パワーオンリセット後、もしくはリセット後に呼びなさい
・そのサービスは、r12 レジスタに 1 をセットした状態で SMI 命令を発行すると呼び出すことができる
とあります (25.4.1 Booting Overview の Caution)。
SMI は、セキュアモニタ命令であり、BootROM コードで実装されている L2 キャッシュの invalidate サービスが、モニターモードで実装されているため、SMI 命令を実行する必要があります。
実際には、SMI 命令ではなく、SMC 命令を使用します。
実装コードは、以下のようなアセンブリコードになります:
SMC 命令は、ARM ARM には、「SMC (以前の SMI)」 と記載されています。
SMC 命令は、即値引数を一つ取ります。
この即値引数に関しては、同じく ARM ARM に、「SMC 例外ハンドラ (セキュアモニタコード) で、要求されているサービスを特定するために使用できますが、この方法は非推奨です」とあります。
BootROM コードの L2 キャッシュ invalidate サービスは、r12=1 によってサービスを特定しているので、SMC に与える即値引数は何でもよいはずなので、とりあえず 0 を指定しておけばよいと思います。
.arch_extension sec は、コンパイルエラーを避けるために入れてあります。
これがないと、"Error: selected processor does not support ARM mode `smc #0" というコンパイルエラーが出てしまいます。
L2 キャッシュに関しては、このように BootROM の invalidate サービスを利用して invalidate してやればよいでしょう。
ちなみに、、、
xloader でも、あまり意味があるとは思えませんが、初期化時に L2 キャッシュの invalidate をしています。
以下のようなコードです。
0xE1600070 が、"smc #0" に相当するマシン語なんですね。
話を戻しまして、、、
L2 キャッシュの invalidate が必要なことは分かりました。
ただ、L1 キャッシュの invalidate が必要かどうかは、よく分かりません。
パワーオンリセット時は、L1 キャッシュは空でしょうから invalidate は必要ないでしょうが、パワーオンリセットでないリセット時は、リセットによってキャッシュが空になるかどうかは、ARM ARM にも Cortex-A8 TRM にも記述がないように思えます。(ただし、見落している可能性もあり。)
念のため、L1 キャッシュも invalidate しておいた方が確実と思います。
それでは、L1 命令キャッシュ、L1 データキャッシュ、L2 統一キャッシュをどのような手順で有効化するかというと、
・L1 命令キャッシュをすべて invalidate する
・L1 データキャッシュをすべて invalidate する
・L2 統一キャッシュをすべて invalidate する
・Control Register の I ビットを立てて L1 命令キャッシュを有効化する
・MMU を有効化する
- ページテーブルを構成する
- Translation Table Base Register にページテーブル先頭アドレスを設定する
- Control Register の M ビットを立てて MMU を有効化する
・Auxiliary Control Register の L2EN ビットを立てる
・Control Register の C ビットを立てて、L1 データキャッシュ、L2 統一キャッシュを有効化する
という方法でいいと思います。
分岐予測を有効にする場合は、更に以下を行います:
・分岐予測器を invalidate する
・Control Register の Z ビットを立てて分岐予測を有効化する
分岐予測器を invalidate するのは、ARM ARM に、「MMU の稼動または非稼動時に分岐予測器を無効化せよ」と書いてあるので (B2.2.6 分岐予測器 分岐予測器の保守操作とメモリオーダモデル)、それに従っています。
ところが、ずっと後で触れますが、Cortex-A8 においては、分岐予測器の invalidate は不要かもしれません。
キャッシュ無効化方法
キャッシュを無効にする場合、単にキャッシュ有効化ビットを落とせばいいわけではありません。
キャッシュを無効にすると同時に、キャッシュを clean しておく必要があります。
キャッシュ clean とは、キャッシュからメインメモリに排出させる動作のことを意味します。
キャッシュ clean を行わずにキャッシュを無効化すると、それまで書き込んできたデータの一部がキャッシュに残ってしまい、メインメモリが不完全な状態になってしまいます。
それでは、キャッシュ無効化とキャッシュ clean の順番はどうすればいいでしょうか。
キャッシュを無効化した後に、キャッシュを clean すればいいでしょうか。
それとも、キャッシュを clean した後にキャッシュを無効化すればいいでしょうか。
Cortex-A8 TRM には、キャッシュを無効化する前にキャッシュを clean および invalidate せよ、と書いてあります (7.2.3 Cache disabled behavior)。
キャッシュを無効化した後でも、キャッシュ保守命令(キャッシュ invalidate とか clean とか、キャッシュに作用する命令のこと)は有効であるとも書かれている (同じく 7.2.3 Cache disabled behavior) ので、逆順にしてもいいような気もしますが、TRM の記述に敢えて逆らう必要もないでしょう。
invalidate が必要な理由は、後でキャッシュを有効にするときに、キャッシュに残っているゴミデータがメインメモリに排出されてしまうことを防ぐためです。
もっとも、有効化する前にキャッシュ invalidate を行うようになっているならば、ここで invalidate する必要はありません。
キャッシュを clean および invalidate し始めてからキャッシュ有効化ビットを落とすまでの間、メモリには書き込みアクセスをしないようにしなければなりません。
さもないと、clean および invalidate した後のキャッシュに、メモリへの書き込みが滞留してしまう可能性があり、そうなると、その書き込みがメインメモリに届かなくなってしまいます。
これを防ぐには、キャッシュの clean および invalidate, キャッシュの無効化をするコードを、すべてアセンブリコードで書く必要があります。
例えば、C 言語で次のようにやるのはダメです:
clean_and_invalidate_cache();
disable_cache();
C 言語の呼び出しには、スタックの push/pop がつきものですので、clean_and_invalidate_cache() で全キャッシュを clean および invalidate した後、clean_and_invalidate_cache() から戻り、disable_cache() を呼び出した時に、disable_cache() の先頭でスタックへ push してしまうので、このスタックへの push 分がキャッシュに滞留してしまうのです。
また、clean_and_invalidate_cache() や disable_cache() で使われる関数オート変数への書き込みも、キャッシュに滞留してしまう可能性があります。
スタックへの push とか関数オート変数分くらい失われてもいいよ、というのであれば、以下のようにすれば大丈夫です。
clean_and_invalidate_cache();
disable_cache();
invalidate_cache();
これにより、clean_and_invdalidate_cache(), disable_cache() 内で行われるスタックへの push とかオート変数への書き込み以外は、すべてメインメモリに排出された上で、キャッシュが空になります。
最後に invalidate_cache() を呼び出しているのは、clean_and_invdalidate_cache(), disable_cache() 呼び出しでキャッシュに滞留してしまったデータ(スタックへの push 分とかオート変数への書き込み分とか)が、ゴミとして残らないようにするためです。
(Cortex-A8 TRM には、キャッシュ無効時でもキャッシュ保守命令は実行されると書いてあります。 7.2.3 Cache disabled behavior)
キャッシュの clean や invalidate は、近い方から行う方がいいのでしょうか、遠い方から行う方がいいのでしょうか。
言い換えると、L1 キャッシュを clean, invalidate してから、その後で L2 キャッシュを clean, invalidate すべきなのか、それとも逆なのか。
これは、やり方によって、状況が変わります。
例えば、以下の方法では、clean & invalidate は、L1 キャッシュから L2 キャッシュへと行わなければなりません。
1. L1 データキャッシュを clean & invalidate
2. L2 キャッシュを clean & invalidate
3. Control Register の C ビットを落として L1 データキャッシュを無効化 (同時に L2 キャッシュも無効化される)
L2 キャッシュが有効な間は、L1 キャッシュの clean によるキャッシュデータの排出は、L2 キャッシュに行きます (Cortex-A8 TRM 8.3 Enabling and disabling the L2 cache controller の Note 参照) ので、1 と 2 の順番を入れ替えてしまうと、L2 キャッシュにデータが滞留してしまいます。
しかし、以下のように、clean & invalidate を、L2 キャッシュから行っても問題ないケースもあります。
1. L2 キャッシュを clean & invalidate
2. Auxiliary Control Register の L2EN ビットを落として L2 キャッシュを無効化
3. L1 データキャッシュを clean & invalidate
4. Control Register の C ビットを落として L1 データキャッシュを無効化
L2 キャッシュが無効になると、L1 キャッシュの clean によるキャッシュデータの排出は、メインメモリに行きますので (同じく Cortex-A8 TRM 8.3 Enabling and disabling the L2 cache controller の Note 参照)、3 の clean は、メインメモリに行くことになり、L2 キャッシュにデータが滞留してしまうことはないのです。
なお、L1 とか L2 とかを意識しなければならないのは、キャッシュレベル、セット、ウェイを指定して clean, invalidate する場合だけです。
アドレスを指定して clean, invalidate を行う場合には、上のようなことは意識する必要はありません。 (ただし、PoC まで clean, invalidate する必要があります。PoC については、後で触れます。)
以上で、キャッシュの有効化・無効化の説明はおしまいです。
有効、無効にするだけなのに、意外とめんどくさいです。
キャッシュ保守命令
キャッシュ保守命令について、もう少し見ていきましょう。
Cortex-A8 TRM に、キャッシュ保守命令の説明が載っています。
キャッシュ保守命令とは、clean, invalidate, clean and invalidate をキャッシュに対して行う命令です。clean は L1 データキャッシュ、L2 統一キャッシュに対して行うことが出来ますが、L1 命令キャッシュに対しては行うことはできません。
invalidate は、L1 命令キャッシュ、L1 データキャッシュ、L2 統一キャッシュに対して行うことができます。
キャッシュ保守命令は、cp15 コプロセッサーに対する命令という形で発行します。
cp15 コプロセッサーに対する命令は、MCR/MRC 命令を使います。
(実装上は、アセンブリ言語で記述する必要があります。)
例えば、以下は命令キャッシュと分岐予測器のキャッシュをすべて invalidate する命令です。
MCR p15, 0, <Rd>, c7, c5, 0
<Rd> には、汎用レジスタを指定します。
保守命令の対象キャッシュを、<Rd> で指定したレジスタの値で決定します。
上例では、'c5, 0' が「すべての命令キャッシュと分岐予測器のキャッシュ」を対象にしていることを意味するので、<Rd> は特定のキャッシュを指定する必要はなく、任意の値で良さそうに思えますが、実際には、値を 0 にしておかないといけません。(Cortex-A8 TRM Table 3-73 Register c7 cache and prefetch buffer maintenance operations)
<Rd> の次の c7 は、キャッシュ保守系列の命令であることを表します。
最後の 'c5, 0' が、保守命令の種類を表します。
その種類によって、<Rd> に設定する値のフォーマットが変わってきます。
以下は、Cortex-A8 TRM から抜粋したキャッシュ保守命令一覧です。
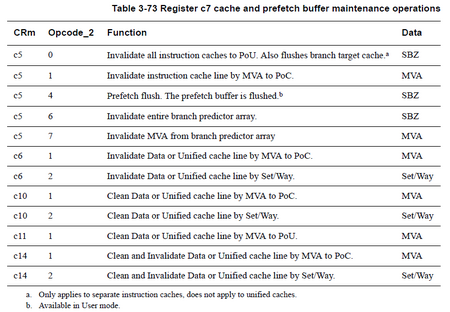
CRm と Opcode_2 が、上例でいうところの 'c5, 0' に相当します。
Data が <Rd> に相当します。
キャッシュ保守命令は、どのキャッシュを対象にするかについて、2 種類の指定方法を用意しています。
一つは、キャッシュレベル、セット番号、ウェイ番号を指定する方法で、もう一つは、MVA (= Modified Virtual Address) を指定する方法です。
MVA は、FCSE (= Fast Context Switch Extension) を使わなければ、仮想アドレスと一致するような、アドレス値です。
(多分、普通は FCSE を使わない、Linux でも多分使っていない)
MVA を指定するキャッシュ保守命令を実行すると、指定された MVA に対応するキャッシュラインに対して作用します。
仮に、指定された MVA に対応するキャッシュラインが存在しない場合は、空振りに終わるものと思います。
MVA を指定するキャッシュ保守命令には、PoC とか PoU とかいう言葉がついて回ります。
PoC まで命令キャッシュを invalidate するとか、PoU までデータキャッシュ/統一キャッシュを clean するとか、そんな感じです。
PoC = Point of Coherency, PoU = Point of Unification の略なのですが、その意味はというと、ARM ARM を見ても、今一つピンときません。
そこで、より明確に書きます。
PoC とは、具体的にはメインメモリを指します。
・PoC まで命令キャッシュを invalidate するということは、MVA に対応する L1 命令キャッシュ/L2 統一キャッシュを invalidate することを意味します。
・PoC までデータキャッシュ/統一キャッシュを clean するということは、MVA に対応する L1 データキャッシュ/L2 統一キャッシュを clean するということを意味します。
・また、PoC までデータキャッシュ/統一キャッシュを invalidate すると、MVA に対応する L1 データキャッシュ/L2 統一キャッシュが invalidate されます。
PoU とは、具体的には L2 統一キャッシュを指すと思います。
・PoU まで命令キャッシュを invalidate するということは、MVA に対応する L1 命令キャッシュを invalidate することを意味します。
・PoU までデータキャッシュ/統一キャッシュを clean するということは、MVA に対応する L1 データキャッシュを clean することを意味します。
・また、PoU までデータキャッシュ/統一キャッシュを invalidate すると、MVA に対応する L1 データキャッシュが invalidate されます。
※PoU までの invalidate/clean は、L2 統一キャッシュに作用しない。
PoC、PoU をさらに理解するにあたって、メモリにアクセスするエージェントの観点から見てみると、
1. 命令キャッシュ
2. データキャッシュ
3. 変換テーブルウォーク機構
4. その他、外部デバイス (DMA とか)
PoC まで命令キャッシュを invalidate し、かつ PoC までデータキャッシュ/統一キャッシュを clean すると、上記登場人物がすべて同じ値を見ることができるようになります。
PoU まで命令キャッシュを invalidate し、データキャッシュ/統一キャッシュを clean すると、「4. その他、外部デバイス」以外の 3者が、同じ値を見ることができるようになります。
ところで、、、
MCR p15, 0, <Rd>, c7, c5, 1 という命令は、"Invalidate instruction cache line by MVA" という意味の命令なのですが、これが PoU まで作用するのか、PoC まで作用するのか、Cortex-A8 TRM を見る限りでは判然としません。
"Table 3.73. Register c7 cache and prefetch buffer maintenance operations" には "Invalidate instruction cache line by MVA to PoC" と書いてあるのですが、"Table 16-13 Nonpipelined CP15 instructions" には、"Invalidate I$ Line by MVA to PoU" と書いてあります。
うーん・・・。
ウェブで Cortex-A15 の TRM を見てみると、MCR p15, 0, <Rd>, c7, c5, 1 は "Invalidate instruction caches by MVA to PoU" となっていますし、ARM ARM の「表 B3-32 CP15 c7 のキャッシュおよび分岐予測器の保守操作」を見てみても、「PoU まで、MVA によって命令キャッシュラインを無効化します」と書いてありますので、Cortex-A8 TRM の "Table 3.73. Register c7 cache and prefetch buffer maintenance operations" の "Invalidate instruction cache line by MVA to PoC" が、多分間違いですね。
PoU が正解と思います。
・・・
キャッシュの保守は、どのような時に実行する必要があるのでしょうか。
命令キャッシュ、データキャッシュ、統一キャッシュそれぞれについて見てみましょう。
命令キャッシュの invalidate が必要な時(ARM ARM B3.4.1 命令キャッシュの要件より)
a1. 命令アドレスへの新しいデータの書き込み
a2. 変換テーブルへの新しいアドレスマッピングの書き込み (注)
a3. ASID に影響を与えない TTBR0, TTBR1, TTBCR レジスタの変更 (注)
a4. SCTRL への書き込みによる MMU の許可または禁止 (注)
ARM7 アーキテクチャのオプション拡張機能の IVIPT 拡張機能(命令キャッシュの仮想インデクス物理タグ付き拡張機能)が実装されていれば、(注) がついている項目は、不要です。
Cortex-A8 は、IVIPT が実装されているので、(注) を付けた a2 - a4 は不要ということになります。
分岐予測器の invalidate が必要な時(ARM ARM B2.2.6 分岐予測器 分岐予測器の保守操作とメモリオーダモデルより)
b1. MMU の稼動または非稼動
b2. 命令位置への新しいデータの書き込み (注)
b3. 変換テーブルへの新しいマッピングの書き込み (注)
Cortex-A8 TRM を見ると、"Processor does not require flushing BTB on VA change." とあります (Table 3-21 Memory Model Feature Register 1 bit functions より)。
BTB は、Branch Target Buffer のことです。
また、"The BTB does not have to be invalidated on a context switch, self-modifying code, or any other change in the VA-to-PA mapping." ともあります。(5.6 Operating system and predictor context より)
これを見る限り、Cortex-A8 では、(注) を付けた b2 や、b3 を行ったとしても、分岐予測器の invalidate は必要ないということですね。
「b1. MMU の稼動または非稼動時」については何も書かれていないのですが、これも必要ないのかもしれません。
Cortex-A8 においては、分岐予測器の invalidate 命令、
MCR p15, 0, <Rd>, c7, c5, 6
MCR p15, 0, <Rd>, c7, c5, 7
は、デフォルトでは NOP と等価であるということが Cortex-A8 TRM に書いてあります。(3.1 About the system control coprosessor)
Auxiliary Control Register の IBE ビットを立てれば、これらの命令は分岐予測器の invalidate 命令として機能するようになります。
ですが、かといって、MMU の稼働または非稼働の時だけ IBE ビットを立てて invalidate を行わなければいけないとすると、不自然な気がします。
なので、MMU の稼動または非稼動時にも、分岐予測器の invalidate は不要なのではないかと・・・。
ただ、IBE ビットを立てない限り NOP と等価なわけですし、しかもサイクルペナルティを伴わない NOP とのことですし、Cortex-A8 に限定せず、ARM v7 アーキテクチャ全般で使用できるコードにしておいた方がいいと思いますので、b1, b2, b3 を行った際には、分岐予測器の invalidate 命令、MCR p15, 0, <Rd>, c7, c5, 6 / MCR p15, 0, <Rd>, c7, c5, 7 を入れておいた方がいいと思います。
データキャッシュの clean/invalidate が必要な時
ARM ARM には特に記載なし
それでは具体例として、コード領域を書き換えたときに必要なキャッシュ保守について、見てみましょう。
必要なのは、
- 命令キャッシュの invalidate
- 分岐予測器の invalidate
- データキャッシュの clean
です。
命令キャッシュの invalidate, 分岐予測器の invalidate は、上記命令キャッシュ・分岐予測器の invalidate 要件より、必要であることが分かります。
分岐予測器の invalidate は、Cortex-A8 では必要ありません。
必要ないのですが、先述したように ARM v7 アーキテクチャ全般で使えるコードにするために、入れておいた方がいいと思います。
データキャッシュの clean は、書き換えたコードデータが、データキャッシュに滞留することを防ぐために必要です。
データキャッシュの clean を行う際、書き換えた範囲だけ、PoU まで clean すれば OK です。
PoC まで clean しても特に問題ありませんが、PoU までで十分です。
実際の実装では、上記キャッシュ保守操作に併せて、メモリバリアを使う必要があります。
メモリバリアについては、別途説明をします。
それぞれのキャッシュサイズは、コプロセッサー cp15 の Cache Size Identification Register を読み出すことにより、知ることができます。
cp15 のレジスタには、mrc, mcr 命令でアクセスすることができます。
Cache Size Identification Register からは、キャッシュに関するサイズ以外の属性も読み出すことが出来ます。
beagleboard で実際に読み出してみると、以下のようになりました:
| WT | WB | RA | WA | セット数 | ウェイ数 | ラインサイズ | キャッシュサイズ | |
| L1命令キャッシュ | N | N | Y | N | 64 | 4 | 64 | 16384 |
| L1データキャッシュ | Y | Y | Y | N | 64 | 4 | 64 | 16384 |
| L2キャッシュ | Y | Y | Y | Y | 512 | 8 | 64 | 262144 |
WT = Write Through サポート
WB = Write Back サポート
RA = Read Allocation サポート
WA = Write Allocation サポート
キャッシュサイズは、セット数 * ウェイ数 * ラインサイズ により算出されます。
例えば L1 命令キャッシュの場合、64 * 4 * 64 = 16384 バイトです。
キャッシュを有効にする方法は、命令キャッシュとデータキャッシュ・統一キャッシュで異なります。
基本的には、Control Register の I ビット、C ビット、Auxiliary Control Register の L2EN ビットが有効/無効を決定するのですが。
命令キャッシュは、I ビットを立てるだけで有効化することができます。
しかし、データキャッシュ・統一キャッシュは、C ビット/L2EN ビットを立てるだけでは有効化できません。
C ビット/L2EN ビットを立てるとともに、MMU も有効にしてやる必要があります。
キャッシュの有効・無効は、次のようなルールに従います:
MMU 稼働の場合
- L1 命令キャッシュは、SCTRL.I ビットの 1/0 によって有効/無効が決まる
- L1 データキャッシュは、SCTRL.C ビットの 1/0 によって有効/無効が決まる
- L2 統一キャッシュは、SCTRL.C ビットが 1 かつ Auxiliary SCTRL.L2EN ビットが 1 の場合は有効、それ以外の組み合わせの場合は無効
MMU 非稼働の場合
- L1 命令キャッシュは、SCTRL.I ビットの 1/0 によって有効/無効が決まる
- L1 データキャッシュは、SCTRL.C ビットの 1/0 によらず、無効になる
- L2 統一キャッシュは、SCTRL.C ビットおよび Auxiliary SCTRL.L2EN ビットの 1/0 によらず、無効になる
※SCTRL = Control Register, Auxiliary SCTRL = Auxiliary Control Register は、コプロセッサー cp15 のレジスタです。
L1 命令キャッシュは、簡単に有効にすることができますが、L1 データキャッシュ、L2 統一キャッシュは MMU を有効化しないと有効にできないので、多少面倒です。
なお、L2 を統一キャッシュと言っているのは、命令データとロード・ストアデータの両方を持つからです。
※
x-loader で、キャッシュはどうなっているかというと、、、
x-loader では、MMU を有効にしていませんので、L1 データキャッシュおよび L2 統一キャッシュは無効です。
L1 命令キャッシュは、有効にしています。
同時に、分岐予測も有効にしています。
MMU を有効にするには、ページテーブルが必要です。
一番簡単なページテーブルは、すべて 16MB のスーパーセクションで構成し、仮想アドレス=物理アドレスとなるようにする構成でしょう。
これだと、4GB のアドレス空間をカバーするのに必要なページテーブルのサイズは、1KB で済みます。
さて、それではこれから、キャッシュの有効化方法、無効化方法について、触れていきます。
きっちりやろうとすると、意外とめんどくさいです。
キャッシュ有効化方法
キャッシュを有効化するには、基本的にはキャッシュ有効化ビットを立てればいいのですが、その前にキャッシュを空にしておく必要があります。
さもないと、キャッシュ中のゴミが、キャッシュ有効後にメインメモリに排出されてしまいます。
キャッシュを空にする動作は invalidate と言いますが、invalidate をどのように行うかがキャッシュ有効化時の考慮点です。
そもそも、L1 キャッシュ、L2 キャッシュともに invalidate する必要があるのかどうか?という点から考えてみる必要があります。
そのために、まず、リセット時にキャッシュがどうなるか、知らなければなりません。
ARM ARM の「B2.2.2 キャッシュの動作 → リセット時のキャッシュの動作」を見てみると、
・すべてのキャッシュはリセット時に非稼働になります。
・実装では、特定のキャッシュ初期化ルーチンを使用して、キャッシュを稼働させる前にその記憶域アレイを無効にすることが必要な場合があります。必要な初期化ルーチンの詳細な形式は実装定義ですが、このルーチンはデバイスのドキュメントの一部として明示的に文書化する必要があります。
とあります。
「デバイスのドキュメント」に相当すると思われる Cortex-A8 TRM を見てみると、L1 キャッシュに関しては、特に初期化に関しての記述はありません。
また、L2 キャッシュに関しても、Auxiliary Control Register の L2EN ビットを立ててから、Control Register の C ビットを立てよ、との記述があるくらいです (8.3 Enabling and disabling the L2 cache controller)。
そこで、さらに OMAP35x TRM を見てみると、
・L2 キャッシュを使用するには、事前に L2 キャッシュのデータをすべて invalidate しなくてはならない
・BootROM コードに、L2 キャッシュを invalidate するサービスを用意しておくので、パワーオンリセット後、もしくはリセット後に呼びなさい
・そのサービスは、r12 レジスタに 1 をセットした状態で SMI 命令を発行すると呼び出すことができる
とあります (25.4.1 Booting Overview の Caution)。
SMI は、セキュアモニタ命令であり、BootROM コードで実装されている L2 キャッシュの invalidate サービスが、モニターモードで実装されているため、SMI 命令を実行する必要があります。
実際には、SMI 命令ではなく、SMC 命令を使用します。
実装コードは、以下のようなアセンブリコードになります:
__asm__ volatile(".arch_extension sec\n\t"
"mov r12,#1\n\t"
"smc #0\n":::"r12");
SMC 命令は、ARM ARM には、「SMC (以前の SMI)」 と記載されています。
SMC 命令は、即値引数を一つ取ります。
この即値引数に関しては、同じく ARM ARM に、「SMC 例外ハンドラ (セキュアモニタコード) で、要求されているサービスを特定するために使用できますが、この方法は非推奨です」とあります。
BootROM コードの L2 キャッシュ invalidate サービスは、r12=1 によってサービスを特定しているので、SMC に与える即値引数は何でもよいはずなので、とりあえず 0 を指定しておけばよいと思います。
.arch_extension sec は、コンパイルエラーを避けるために入れてあります。
これがないと、"Error: selected processor does not support ARM mode `smc #0" というコンパイルエラーが出てしまいます。
L2 キャッシュに関しては、このように BootROM の invalidate サービスを利用して invalidate してやればよいでしょう。
ちなみに、、、
xloader でも、あまり意味があるとは思えませんが、初期化時に L2 キャッシュの invalidate をしています。
以下のようなコードです。
231: mov r12, #0x1 @ set up to invalide L2
232: smi: .word 0xE1600070 @ Call SMI monitor
0xE1600070 が、"smc #0" に相当するマシン語なんですね。
話を戻しまして、、、
L2 キャッシュの invalidate が必要なことは分かりました。
ただ、L1 キャッシュの invalidate が必要かどうかは、よく分かりません。
パワーオンリセット時は、L1 キャッシュは空でしょうから invalidate は必要ないでしょうが、パワーオンリセットでないリセット時は、リセットによってキャッシュが空になるかどうかは、ARM ARM にも Cortex-A8 TRM にも記述がないように思えます。(ただし、見落している可能性もあり。)
念のため、L1 キャッシュも invalidate しておいた方が確実と思います。
それでは、L1 命令キャッシュ、L1 データキャッシュ、L2 統一キャッシュをどのような手順で有効化するかというと、
・L1 命令キャッシュをすべて invalidate する
・L1 データキャッシュをすべて invalidate する
・L2 統一キャッシュをすべて invalidate する
・Control Register の I ビットを立てて L1 命令キャッシュを有効化する
・MMU を有効化する
- ページテーブルを構成する
- Translation Table Base Register にページテーブル先頭アドレスを設定する
- Control Register の M ビットを立てて MMU を有効化する
・Auxiliary Control Register の L2EN ビットを立てる
・Control Register の C ビットを立てて、L1 データキャッシュ、L2 統一キャッシュを有効化する
という方法でいいと思います。
分岐予測を有効にする場合は、更に以下を行います:
・分岐予測器を invalidate する
・Control Register の Z ビットを立てて分岐予測を有効化する
分岐予測器を invalidate するのは、ARM ARM に、「MMU の稼動または非稼動時に分岐予測器を無効化せよ」と書いてあるので (B2.2.6 分岐予測器 分岐予測器の保守操作とメモリオーダモデル)、それに従っています。
ところが、ずっと後で触れますが、Cortex-A8 においては、分岐予測器の invalidate は不要かもしれません。
キャッシュ無効化方法
キャッシュを無効にする場合、単にキャッシュ有効化ビットを落とせばいいわけではありません。
キャッシュを無効にすると同時に、キャッシュを clean しておく必要があります。
キャッシュ clean とは、キャッシュからメインメモリに排出させる動作のことを意味します。
キャッシュ clean を行わずにキャッシュを無効化すると、それまで書き込んできたデータの一部がキャッシュに残ってしまい、メインメモリが不完全な状態になってしまいます。
それでは、キャッシュ無効化とキャッシュ clean の順番はどうすればいいでしょうか。
キャッシュを無効化した後に、キャッシュを clean すればいいでしょうか。
それとも、キャッシュを clean した後にキャッシュを無効化すればいいでしょうか。
Cortex-A8 TRM には、キャッシュを無効化する前にキャッシュを clean および invalidate せよ、と書いてあります (7.2.3 Cache disabled behavior)。
キャッシュを無効化した後でも、キャッシュ保守命令(キャッシュ invalidate とか clean とか、キャッシュに作用する命令のこと)は有効であるとも書かれている (同じく 7.2.3 Cache disabled behavior) ので、逆順にしてもいいような気もしますが、TRM の記述に敢えて逆らう必要もないでしょう。
invalidate が必要な理由は、後でキャッシュを有効にするときに、キャッシュに残っているゴミデータがメインメモリに排出されてしまうことを防ぐためです。
もっとも、有効化する前にキャッシュ invalidate を行うようになっているならば、ここで invalidate する必要はありません。
キャッシュを clean および invalidate し始めてからキャッシュ有効化ビットを落とすまでの間、メモリには書き込みアクセスをしないようにしなければなりません。
さもないと、clean および invalidate した後のキャッシュに、メモリへの書き込みが滞留してしまう可能性があり、そうなると、その書き込みがメインメモリに届かなくなってしまいます。
これを防ぐには、キャッシュの clean および invalidate, キャッシュの無効化をするコードを、すべてアセンブリコードで書く必要があります。
例えば、C 言語で次のようにやるのはダメです:
clean_and_invalidate_cache();
disable_cache();
C 言語の呼び出しには、スタックの push/pop がつきものですので、clean_and_invalidate_cache() で全キャッシュを clean および invalidate した後、clean_and_invalidate_cache() から戻り、disable_cache() を呼び出した時に、disable_cache() の先頭でスタックへ push してしまうので、このスタックへの push 分がキャッシュに滞留してしまうのです。
また、clean_and_invalidate_cache() や disable_cache() で使われる関数オート変数への書き込みも、キャッシュに滞留してしまう可能性があります。
スタックへの push とか関数オート変数分くらい失われてもいいよ、というのであれば、以下のようにすれば大丈夫です。
clean_and_invalidate_cache();
disable_cache();
invalidate_cache();
これにより、clean_and_invdalidate_cache(), disable_cache() 内で行われるスタックへの push とかオート変数への書き込み以外は、すべてメインメモリに排出された上で、キャッシュが空になります。
最後に invalidate_cache() を呼び出しているのは、clean_and_invdalidate_cache(), disable_cache() 呼び出しでキャッシュに滞留してしまったデータ(スタックへの push 分とかオート変数への書き込み分とか)が、ゴミとして残らないようにするためです。
(Cortex-A8 TRM には、キャッシュ無効時でもキャッシュ保守命令は実行されると書いてあります。 7.2.3 Cache disabled behavior)
キャッシュの clean や invalidate は、近い方から行う方がいいのでしょうか、遠い方から行う方がいいのでしょうか。
言い換えると、L1 キャッシュを clean, invalidate してから、その後で L2 キャッシュを clean, invalidate すべきなのか、それとも逆なのか。
これは、やり方によって、状況が変わります。
例えば、以下の方法では、clean & invalidate は、L1 キャッシュから L2 キャッシュへと行わなければなりません。
1. L1 データキャッシュを clean & invalidate
2. L2 キャッシュを clean & invalidate
3. Control Register の C ビットを落として L1 データキャッシュを無効化 (同時に L2 キャッシュも無効化される)
L2 キャッシュが有効な間は、L1 キャッシュの clean によるキャッシュデータの排出は、L2 キャッシュに行きます (Cortex-A8 TRM 8.3 Enabling and disabling the L2 cache controller の Note 参照) ので、1 と 2 の順番を入れ替えてしまうと、L2 キャッシュにデータが滞留してしまいます。
しかし、以下のように、clean & invalidate を、L2 キャッシュから行っても問題ないケースもあります。
1. L2 キャッシュを clean & invalidate
2. Auxiliary Control Register の L2EN ビットを落として L2 キャッシュを無効化
3. L1 データキャッシュを clean & invalidate
4. Control Register の C ビットを落として L1 データキャッシュを無効化
L2 キャッシュが無効になると、L1 キャッシュの clean によるキャッシュデータの排出は、メインメモリに行きますので (同じく Cortex-A8 TRM 8.3 Enabling and disabling the L2 cache controller の Note 参照)、3 の clean は、メインメモリに行くことになり、L2 キャッシュにデータが滞留してしまうことはないのです。
なお、L1 とか L2 とかを意識しなければならないのは、キャッシュレベル、セット、ウェイを指定して clean, invalidate する場合だけです。
アドレスを指定して clean, invalidate を行う場合には、上のようなことは意識する必要はありません。 (ただし、PoC まで clean, invalidate する必要があります。PoC については、後で触れます。)
以上で、キャッシュの有効化・無効化の説明はおしまいです。
有効、無効にするだけなのに、意外とめんどくさいです。
キャッシュ保守命令
キャッシュ保守命令について、もう少し見ていきましょう。
Cortex-A8 TRM に、キャッシュ保守命令の説明が載っています。
キャッシュ保守命令とは、clean, invalidate, clean and invalidate をキャッシュに対して行う命令です。clean は L1 データキャッシュ、L2 統一キャッシュに対して行うことが出来ますが、L1 命令キャッシュに対しては行うことはできません。
invalidate は、L1 命令キャッシュ、L1 データキャッシュ、L2 統一キャッシュに対して行うことができます。
キャッシュ保守命令は、cp15 コプロセッサーに対する命令という形で発行します。
cp15 コプロセッサーに対する命令は、MCR/MRC 命令を使います。
(実装上は、アセンブリ言語で記述する必要があります。)
例えば、以下は命令キャッシュと分岐予測器のキャッシュをすべて invalidate する命令です。
MCR p15, 0, <Rd>, c7, c5, 0
<Rd> には、汎用レジスタを指定します。
保守命令の対象キャッシュを、<Rd> で指定したレジスタの値で決定します。
上例では、'c5, 0' が「すべての命令キャッシュと分岐予測器のキャッシュ」を対象にしていることを意味するので、<Rd> は特定のキャッシュを指定する必要はなく、任意の値で良さそうに思えますが、実際には、値を 0 にしておかないといけません。(Cortex-A8 TRM Table 3-73 Register c7 cache and prefetch buffer maintenance operations)
<Rd> の次の c7 は、キャッシュ保守系列の命令であることを表します。
最後の 'c5, 0' が、保守命令の種類を表します。
その種類によって、<Rd> に設定する値のフォーマットが変わってきます。
以下は、Cortex-A8 TRM から抜粋したキャッシュ保守命令一覧です。
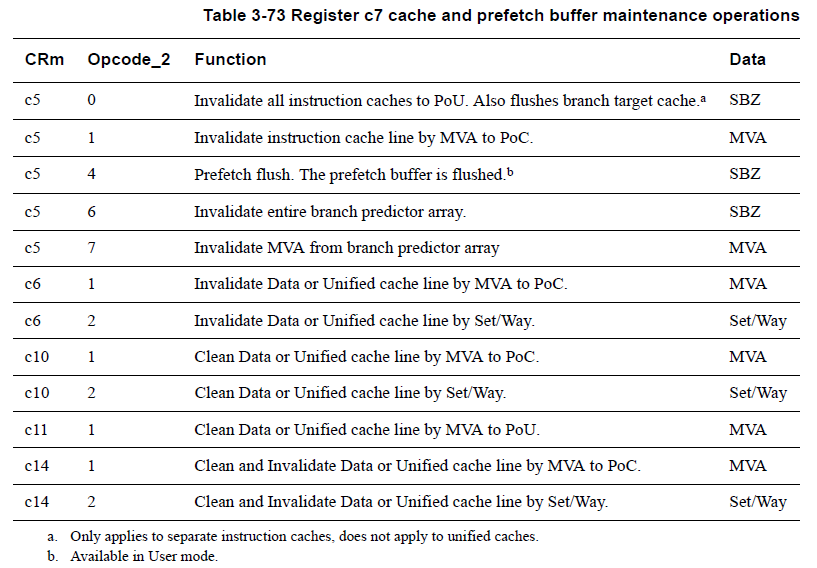
CRm と Opcode_2 が、上例でいうところの 'c5, 0' に相当します。
Data が <Rd> に相当します。
キャッシュ保守命令は、どのキャッシュを対象にするかについて、2 種類の指定方法を用意しています。
一つは、キャッシュレベル、セット番号、ウェイ番号を指定する方法で、もう一つは、MVA (= Modified Virtual Address) を指定する方法です。
MVA は、FCSE (= Fast Context Switch Extension) を使わなければ、仮想アドレスと一致するような、アドレス値です。
(多分、普通は FCSE を使わない、Linux でも多分使っていない)
MVA を指定するキャッシュ保守命令を実行すると、指定された MVA に対応するキャッシュラインに対して作用します。
仮に、指定された MVA に対応するキャッシュラインが存在しない場合は、空振りに終わるものと思います。
MVA を指定するキャッシュ保守命令には、PoC とか PoU とかいう言葉がついて回ります。
PoC まで命令キャッシュを invalidate するとか、PoU までデータキャッシュ/統一キャッシュを clean するとか、そんな感じです。
PoC = Point of Coherency, PoU = Point of Unification の略なのですが、その意味はというと、ARM ARM を見ても、今一つピンときません。
そこで、より明確に書きます。
PoC とは、具体的にはメインメモリを指します。
・PoC まで命令キャッシュを invalidate するということは、MVA に対応する L1 命令キャッシュ/L2 統一キャッシュを invalidate することを意味します。
・PoC までデータキャッシュ/統一キャッシュを clean するということは、MVA に対応する L1 データキャッシュ/L2 統一キャッシュを clean するということを意味します。
・また、PoC までデータキャッシュ/統一キャッシュを invalidate すると、MVA に対応する L1 データキャッシュ/L2 統一キャッシュが invalidate されます。
PoU とは、具体的には L2 統一キャッシュを指すと思います。
・PoU まで命令キャッシュを invalidate するということは、MVA に対応する L1 命令キャッシュを invalidate することを意味します。
・PoU までデータキャッシュ/統一キャッシュを clean するということは、MVA に対応する L1 データキャッシュを clean することを意味します。
・また、PoU までデータキャッシュ/統一キャッシュを invalidate すると、MVA に対応する L1 データキャッシュが invalidate されます。
※PoU までの invalidate/clean は、L2 統一キャッシュに作用しない。
PoC、PoU をさらに理解するにあたって、メモリにアクセスするエージェントの観点から見てみると、
1. 命令キャッシュ
2. データキャッシュ
3. 変換テーブルウォーク機構
4. その他、外部デバイス (DMA とか)
PoC まで命令キャッシュを invalidate し、かつ PoC までデータキャッシュ/統一キャッシュを clean すると、上記登場人物がすべて同じ値を見ることができるようになります。
PoU まで命令キャッシュを invalidate し、データキャッシュ/統一キャッシュを clean すると、「4. その他、外部デバイス」以外の 3者が、同じ値を見ることができるようになります。
ところで、、、
MCR p15, 0, <Rd>, c7, c5, 1 という命令は、"Invalidate instruction cache line by MVA" という意味の命令なのですが、これが PoU まで作用するのか、PoC まで作用するのか、Cortex-A8 TRM を見る限りでは判然としません。
"Table 3.73. Register c7 cache and prefetch buffer maintenance operations" には "Invalidate instruction cache line by MVA to PoC" と書いてあるのですが、"Table 16-13 Nonpipelined CP15 instructions" には、"Invalidate I$ Line by MVA to PoU" と書いてあります。
うーん・・・。
ウェブで Cortex-A15 の TRM を見てみると、MCR p15, 0, <Rd>, c7, c5, 1 は "Invalidate instruction caches by MVA to PoU" となっていますし、ARM ARM の「表 B3-32 CP15 c7 のキャッシュおよび分岐予測器の保守操作」を見てみても、「PoU まで、MVA によって命令キャッシュラインを無効化します」と書いてありますので、Cortex-A8 TRM の "Table 3.73. Register c7 cache and prefetch buffer maintenance operations" の "Invalidate instruction cache line by MVA to PoC" が、多分間違いですね。
PoU が正解と思います。
・・・
キャッシュの保守は、どのような時に実行する必要があるのでしょうか。
命令キャッシュ、データキャッシュ、統一キャッシュそれぞれについて見てみましょう。
命令キャッシュの invalidate が必要な時(ARM ARM B3.4.1 命令キャッシュの要件より)
a1. 命令アドレスへの新しいデータの書き込み
a2. 変換テーブルへの新しいアドレスマッピングの書き込み (注)
a3. ASID に影響を与えない TTBR0, TTBR1, TTBCR レジスタの変更 (注)
a4. SCTRL への書き込みによる MMU の許可または禁止 (注)
ARM7 アーキテクチャのオプション拡張機能の IVIPT 拡張機能(命令キャッシュの仮想インデクス物理タグ付き拡張機能)が実装されていれば、(注) がついている項目は、不要です。
Cortex-A8 は、IVIPT が実装されているので、(注) を付けた a2 - a4 は不要ということになります。
分岐予測器の invalidate が必要な時(ARM ARM B2.2.6 分岐予測器 分岐予測器の保守操作とメモリオーダモデルより)
b1. MMU の稼動または非稼動
b2. 命令位置への新しいデータの書き込み (注)
b3. 変換テーブルへの新しいマッピングの書き込み (注)
Cortex-A8 TRM を見ると、"Processor does not require flushing BTB on VA change." とあります (Table 3-21 Memory Model Feature Register 1 bit functions より)。
BTB は、Branch Target Buffer のことです。
また、"The BTB does not have to be invalidated on a context switch, self-modifying code, or any other change in the VA-to-PA mapping." ともあります。(5.6 Operating system and predictor context より)
これを見る限り、Cortex-A8 では、(注) を付けた b2 や、b3 を行ったとしても、分岐予測器の invalidate は必要ないということですね。
「b1. MMU の稼動または非稼動時」については何も書かれていないのですが、これも必要ないのかもしれません。
Cortex-A8 においては、分岐予測器の invalidate 命令、
MCR p15, 0, <Rd>, c7, c5, 6
MCR p15, 0, <Rd>, c7, c5, 7
は、デフォルトでは NOP と等価であるということが Cortex-A8 TRM に書いてあります。(3.1 About the system control coprosessor)
Auxiliary Control Register の IBE ビットを立てれば、これらの命令は分岐予測器の invalidate 命令として機能するようになります。
ですが、かといって、MMU の稼働または非稼働の時だけ IBE ビットを立てて invalidate を行わなければいけないとすると、不自然な気がします。
なので、MMU の稼動または非稼動時にも、分岐予測器の invalidate は不要なのではないかと・・・。
ただ、IBE ビットを立てない限り NOP と等価なわけですし、しかもサイクルペナルティを伴わない NOP とのことですし、Cortex-A8 に限定せず、ARM v7 アーキテクチャ全般で使用できるコードにしておいた方がいいと思いますので、b1, b2, b3 を行った際には、分岐予測器の invalidate 命令、MCR p15, 0, <Rd>, c7, c5, 6 / MCR p15, 0, <Rd>, c7, c5, 7 を入れておいた方がいいと思います。
データキャッシュの clean/invalidate が必要な時
ARM ARM には特に記載なし
それでは具体例として、コード領域を書き換えたときに必要なキャッシュ保守について、見てみましょう。
必要なのは、
- 命令キャッシュの invalidate
- 分岐予測器の invalidate
- データキャッシュの clean
です。
命令キャッシュの invalidate, 分岐予測器の invalidate は、上記命令キャッシュ・分岐予測器の invalidate 要件より、必要であることが分かります。
分岐予測器の invalidate は、Cortex-A8 では必要ありません。
必要ないのですが、先述したように ARM v7 アーキテクチャ全般で使えるコードにするために、入れておいた方がいいと思います。
データキャッシュの clean は、書き換えたコードデータが、データキャッシュに滞留することを防ぐために必要です。
データキャッシュの clean を行う際、書き換えた範囲だけ、PoU まで clean すれば OK です。
PoC まで clean しても特に問題ありませんが、PoU までで十分です。
実際の実装では、上記キャッシュ保守操作に併せて、メモリバリアを使う必要があります。
メモリバリアについては、別途説明をします。
beagleboard を触ろう - Windows 開発環境 [組み込みソフト]
x-loader は、cygwin 環境でもビルドすることができます。
やっぱり、Windows だと何かと便利なので、cygwin 上での開発環境を作ってしまいましょう。
http://www.codesourcery.com/sgpp/lite/arm/portal/subscription?@template=lite
から、Windows 用バイナリを取得します。
このページの、Target OS が GNU/Linux の All versions... をクリックすると、
https://sourcery.mentor.com/sgpp/lite/arm/portal/subscription3057
に行きます。
Sourcery G++ Lite の最新版を取得しましょう。
私が見たときは、Sourcery G++ Lite 2011.03-41 が最新でした。
そこをクリックすると、
https://sourcery.mentor.com/sgpp/lite/arm/portal/release1803
に行きます。
ここで、IA32 Windows INSTALLER をクリックして、インストーライメージを保存・実行もしくは直接実行します。
デフォルトでは C:\Program Files 以下にインストールされてしまいますが、cygwin 環境では空白文字入りのファイル名は不便なので、インストール先を変更します。
私は、C:\cygwin\opt\sourcery にしました。
インストールが完了したら、パスを通します。
PATH 環境変数に、C:\cygwin\opt\sourcery\bin を追加です。
それではビルドですが、ソースコードを取ってきて、以下を cygwin から実行です。
・export CYGPATH=c:/cygwin/bin/cygpath.exe
・tar zxf xloader_xxx.tar.gz
・cd xloader
・make omap3530beagle_config
・make
・./signGP.exe x-load.bin
・cp x-load.bin.ift MLO
・MLO を SD カードにコピー
cygwin でビルドできるようにするために、config.mk を 1箇所だけ変更してあります:
gccincdir := $(shell $(CC) -print-file-name=include)
⇒ gccincdir := $(shell $(CC) -print-file-name=include | sed -e "s/^c:/\/cygdrive\/c/")
これをやっておかないと、make の際にエラーが出てしまいます。
make 実行時に .depend が作られますが、↑の修正をやらないと、.depend は、以下のようになってしまいます。
:
omap3530beagle.o: omap3530beagle.c \
/cygdrive/c/work/beagleboard/xloader/include/common.h \
/cygdrive/c/work/beagleboard/xloader/include/config.h \
/cygdrive/c/work/beagleboard/xloader/include/configs/omap3530beagle.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/arch/cpu.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/arch/omap3430.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/arch/sizes.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/types.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/config.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/posix_types.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/stddef.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/posix_types.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/types.h \
c:/cygwin/opt/sourcery/bin/../lib/gcc/arm-none-linux-gnueabi/4.5.2/include/stdarg.h \
:
c:/cygwin/opt/sourcery/... の行が不正で、make がエラーになってしまいます。
c:/cygwin/opt/sourcery/... → /cygdrive/c/cygwin/opt/sourcery/...
と変更するための修正が、sed -e "s/^c:/\/cygdrive\/c/" の追加です。
cygwin を C ドライブ以外にインストールされている方は、sed -e... 以下を適当に変更してください。
・・・
これで、cygwin 上でビルドできるようになりました。
ソースコードのページ
やっぱり、Windows だと何かと便利なので、cygwin 上での開発環境を作ってしまいましょう。
http://www.codesourcery.com/sgpp/lite/arm/portal/subscription?@template=lite
から、Windows 用バイナリを取得します。
このページの、Target OS が GNU/Linux の All versions... をクリックすると、
https://sourcery.mentor.com/sgpp/lite/arm/portal/subscription3057
に行きます。
Sourcery G++ Lite の最新版を取得しましょう。
私が見たときは、Sourcery G++ Lite 2011.03-41 が最新でした。
そこをクリックすると、
https://sourcery.mentor.com/sgpp/lite/arm/portal/release1803
に行きます。
ここで、IA32 Windows INSTALLER をクリックして、インストーライメージを保存・実行もしくは直接実行します。
デフォルトでは C:\Program Files 以下にインストールされてしまいますが、cygwin 環境では空白文字入りのファイル名は不便なので、インストール先を変更します。
私は、C:\cygwin\opt\sourcery にしました。
インストールが完了したら、パスを通します。
PATH 環境変数に、C:\cygwin\opt\sourcery\bin を追加です。
それではビルドですが、ソースコードを取ってきて、以下を cygwin から実行です。
・export CYGPATH=c:/cygwin/bin/cygpath.exe
・tar zxf xloader_xxx.tar.gz
・cd xloader
・make omap3530beagle_config
・make
・./signGP.exe x-load.bin
・cp x-load.bin.ift MLO
・MLO を SD カードにコピー
cygwin でビルドできるようにするために、config.mk を 1箇所だけ変更してあります:
gccincdir := $(shell $(CC) -print-file-name=include)
⇒ gccincdir := $(shell $(CC) -print-file-name=include | sed -e "s/^c:/\/cygdrive\/c/")
これをやっておかないと、make の際にエラーが出てしまいます。
make 実行時に .depend が作られますが、↑の修正をやらないと、.depend は、以下のようになってしまいます。
:
omap3530beagle.o: omap3530beagle.c \
/cygdrive/c/work/beagleboard/xloader/include/common.h \
/cygdrive/c/work/beagleboard/xloader/include/config.h \
/cygdrive/c/work/beagleboard/xloader/include/configs/omap3530beagle.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/arch/cpu.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/arch/omap3430.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/arch/sizes.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/types.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/config.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/posix_types.h \
/cygdrive/c/work/beagleboard/xloader/include/linux/stddef.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/posix_types.h \
/cygdrive/c/work/beagleboard/xloader/include/asm/types.h \
c:/cygwin/opt/sourcery/bin/../lib/gcc/arm-none-linux-gnueabi/4.5.2/include/stdarg.h \
:
c:/cygwin/opt/sourcery/... の行が不正で、make がエラーになってしまいます。
c:/cygwin/opt/sourcery/... → /cygdrive/c/cygwin/opt/sourcery/...
と変更するための修正が、sed -e "s/^c:/\/cygdrive\/c/" の追加です。
cygwin を C ドライブ以外にインストールされている方は、sed -e... 以下を適当に変更してください。
・・・
これで、cygwin 上でビルドできるようになりました。
ソースコードのページ
beagleboard を触ろう - ソースコード [組み込みソフト]
これまでの記事では、文章と絵とソースコードが少々という構成でしたが、ソースコード全体がありませんでした。
エッセンスだけ抽出して、できるだけ簡潔に、という記事を目指していたので、ソースコードなんて要らないだろうと思っていたのですが、、、
ひょっとしたら、自分の手元で動かして確かめてみたいという方がおられないとも限らないので、公開することにします。
公開するといっても、x-loader にちょろちょろと手を入れているだけのソースコードですが (^^;
これです↓
ソースコードのページ
ビルド方法については、「開発環境のインストール」「x-loader ビルド」「Windows 開発環境」の回の記事を参照してください。
CodeSourcery をインストールしてあれば、
・tar-ball を展開
・xloader ディレクトリができるので、そこに移動
・make omap3530beagle_config
・make
・./signGP x-load.bin
・cp x-load.bin.ift MLO
・MLO を SD カードにコピー
で OK です。
私がいつも使っている SD カードは、「angstrom ブート」の記事中の方法で作ったもので、FAT32 と ext3 が混在したものなのですが、多分、全体を FAT32 でフォーマットしたものでも大丈夫です。
MLO を、FAT32 領域にコピーしてください。
USER ボタンを押下しながら電源を入れると、beagleboard は SD カードから MLO (=x-loader) をロードして実行します。
PC 側のシリアル端末は、なんでもいいと思いますが、私は TeraTerm を使っています。
ボーレートは、115200 bps にしてください。
無事 x-loader が実行されると、コマンドプロンプトらしき '>' マークが表示されます。
このプロンプトでは、次のコマンドを受け付けます:
i : UART 割り込みテスト
d : UART DMA テスト
t : タイマーテスト
l : LED テスト
b : ボタンテスト
s : SDRAM テスト
n : NAND テスト
sd: SD カードテスト
m : DSS テスト
各テストの内容は、以下です。
UART 割り込みテスト
「UART 割り込みモード」の回に作ったものです。
UART3 を割り込みモードに設定し、'q' が入力されるまでループします。
1 秒おきに "uart_interrupt_test" という文字列をシリアルコンソールに表示します。
'q' 以外を入力すると、"OK" という文字列をシリアルコンソールに表示します。
'q' を入力するとコマンドプロンプトに戻ります。
UART DMA テスト
「UART DMA モード」の回に作ったものです。
UART3 を DMA モードに設定し、シリアルコンソールから 8 文字入力されるまで、ビジーループします。
UART3 に入力された 8 文字は、DMA によって dma_buf 上に転送されます。
転送された 8 文字をシリアルコンソールに出力した後、コマンドプロンプトに戻ります。
タイマーテスト
「タイマーとコンテキストスイッチ」の回に作ったものです。
タスクを 2 つ追加し、3 秒おきにコンテキストスイッチを行います。
'q' を入力するとコマンドプロンプトに戻ります。
ただし、'q' を入力しても、即座にはコマンドプロンプトには戻りません。
メインタスクに実行権が移った時、'q' が入力されたかどうかがチェックされます。
LED テスト
「LED とボタン」の回に作ったものです。
LED を点滅させます。
'q' を入力するとコマンドプロンプトに戻ります。
ボタンテスト
「LED とボタン」の回に作ったものです。
USER ボタンを押下すると、シリアルコンソールに "button pressed", "button released" を表示します。
'q' を入力するとコマンドプロンプトに戻ります。
SDRAM テスト
SDRAM の読み書きを全領域にわたって行います。
テストが完了すると、サイクルカウンターの値をシリアルコンソールに出力してコマンドプロンプトに戻ります。
NAND テスト
「メモリ」の回に作ったものです。
NAND テストは、以下の 4 つのテストから成ります:
ns: NAND ステータステスト
NAND ステータスを取得します。
ステータス取得後、コマンドプロンプトに戻ります。
nr: NAND 読み出しテスト
オフセット 0x07FE0000 から 1 ページ読み出します。
これは、最も高位にあるページです。
読み出し先は、0x88000000 という SDRAM 上の適当なアドレスです。
読み出し完了後、読み出した値を表示して、コマンドプロンプトに戻ります。
ne: NAND 消去テスト
オフセット 0x07FE0000 からの 1 ページを消去します。
消去完了後、コマンドプロンプトに戻ります。
np: NAND プログラムテスト
2 つの引数、off と len を取ります(引き数 off は 1 桁の値のみ・・・)。
np 6 10 のように入力して引数を渡します。
オフセット 0x07FE0000 + off に 0x88000000 に書かれているデータを長さ len 分だけ書き込みます。
書き込み完了後、コマンドプロンプトに戻ります。
SD カードテスト
「FAT ファイルシステム」の回に作ったものです。
1 つの引き数 blknr を取ります。
sd 10 のように入力して引数を渡します。
SD カードから、ブロック番号 blknr から 1 ブロック分読み出します。
読み出した値をシリアルコンソールに出力した後、コマンドプロンプトに戻ります。
DSS テスト
「LCD 表示」「LCD 表示 (2)」の回に作ったものです。
このテストを試すには、HDMI-DVI 変換ケーブルで beagleboard と液晶ディスプレイを接続しておく必要があります。
DSS テストは、32 個のサブコマンドがあります。
'm' の後に、空白文字を 1 つ挟んで、サブコマンド番号を入力します。
m 0:
640 x 480 @ 60Hz で DSS を初期化します。
m 1:
640 x 480 @ 75Hz で DSS を初期化します。
m 2:
800 x 600 @ 60Hz で DSS を初期化します。
m 3:
1024 x 768 @ 60Hz で DSS を初期化します。
m 4:
1280 x 1024 @ 60Hz で DSS を初期化します。
m 5:
fuji.bgr を SD カードから読み出して、Video1 画面に表示します。
fuji.bgr は、640 x 512 サイズ、RGB24 フォーマット (データ並び順は BGR) の画像データです。
m 6:
Video1 画面を無効化します。
m 7:
Video2 画面を無効化します。
m 8:
Graphics 画面を無効化します。
m 9:
asa.bgr, cake.bgr, shin.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
asa.bgr, cake.bgr, shin.bgr は、いずれも 640 x 512 サイズ、RGB24 フォーマット (データ並び順は BGR) の画像データです。
画像の配置は、1280 x 1024 にちょうど収まるような配置にしています。
m 10:
asa.bgr, cake.bgr, shin.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
コマンド 9 と違って、重なり表示をするようにしています。
ついでに重なったまま動きます。
m 11:
fuji.bgr を SD カードから読み出して、Video1 画面に拡大表示します。
m 12:
fuji.bgr を SD カードから読み出して、Video1 画面に縮小表示します。
※ 1280 x 1024 でこれを実行すると、画面が乱れてしまいますので、1024 x 768 でお試しください。
m 13:
fuji.bgr を SD カードから読み出して、Video1 画面上で徐々に拡大させていきます。
m 14:
asa_a.bgr, cake_a.bgr, shin_a.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
asa_a.bgr, cake_a.bgr, shin_a.bgr は、いずれも 640 x 512 サイズ、ARGB32 フォーマット (データ並び順は BGRA) の画像データです。
アルファブレンドは、すべてのピクセルにおいて、50% (アルファ値としては 0x80) にしています。
画像の配置は、1280 x 1024 にちょうど収まるような配置にしています。
m 15:
asa_a.bgr, cake_a.bgr, shin_a.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
コマンド 14 と違って、重なり表示をするようにしています。
※ 1280 x 1024 でこれを実行すると、画面が乱れてしまいますので、1024 x 768 でお試しください。
m 16:
asa.bgr を SD カードから読み出して、Video2 画面に表示します。
m 17:
asa_a.bgr を SD カードから読み出して、Video2 画面に表示します。
m 18:
asa_a0.bgr を SD カードから読み出して、Video2 画面に表示します。
asa_a0.bgr は 640 x 512 サイズ、ARGB32 フォーマットの画像データ (データ並び順は BGRA) で、アルファブレンドはすべてのピクセルにおいて、100% (アルファ値としては 0x00)にしています。
アルファブレンドを有効にすると、asa_a0.bgr は透過率 100% となって表示されません。
m 19:
asa_aff.bgr を SD カードから読み出して、Video2 画面に表示します。
asa_aff.bgr は 640 x 512 サイズ、ARGB32 フォーマットの画像データ (データ並び順は BGRA) で、アルファブレンドはすべてのピクセルにおいて、0% (アルファ値としては 0xff)にしています。
m 20:
アルファブレンドを有効にし、Video2 画面、Graphics 画面のグローバルアルファブレンドを 0% (アルファ値としては 0xff) にします。
アルファブレンド 0% は、全く透過させないことを意味します。
コマンド 16 - 19 によって表示された画像は、画像データ中のアルファ値によってのみアルファブレンドが決定されます。
m 21:
アルファブレンドを有効にし、Video2 画面、Graphics 画面のグローバルアルファブレンドを 50% (アルファ値としては 0x80) にします。
コマンド 16 - 19 で表示された画像は、グローバルアルファ値と画像データ中のアルファ値の相乗でアルファブレンドが決定されます。
m 22:
アルファブレンドを無効にします。
m 23:
tckgfx.bgr, tckvid1.bgr, tckvid2.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
m 24:
transparency color key を有効にします。
コマンド 23 で表示された画像は、コマンド 24 によって影響を受けます。
m 25:
transparency color key を無効にします。
m 26:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
fuji32.bgr は、640 x 480 サイズ、RGB24 (un-packed in 32-bit container) フォーマット (データ並び順は BGRX) の画像データです。
"un-packed in 32-bit container" と言っているのは、BGR 24ビットの後に、適当な pad データを入れて 32 ビットにしているという意味です。
m 27:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
1行 1行の間隔を空けて配置した画像データを表示できるように、DISPC_VID_ROW_INC レジスタへ正しく値設定できているか確かめるためのテストです。
m 28:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
表示する画像は、VRFB Context 1 の 90 度回転画像です。
m 29:
fuji32.bgr を SD カードから読み出して、Video2 画面に表示します。
表示する画像は、VRFB Context 2 の 180 度回転画像です。
m 30:
fuji32.bgr を SD カードから読み出して、Graphics 画面に表示します。
表示する画像は、VRFB Context 3 の 270 度回転画像です。
m 31:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
表示する画像は、VRFB Context 4 の 0 度回転画像です。
m 32:
VRFB に書き込んだデータが、SDRAM 上でどのように配置されるかを確認するためのテストです。
ソースコードのページ に、DSS テストで使用する画像データも一応用意してあります。
dsspic.zip を取得・展開して、すべて SD カードにコピーしてください。
・・・
今までの記事の中で、これらのソースコードが部分的に登場していますが、記事の中のソースコードと現状のソースコードでは、行番号が違っていたりするかもしれません。
ただ、大幅に変わってしまって、原型をとどめていない、というようなことはないと思います。
あと、シリアルコンソールに大量出力すると、シリアルコンソールの表示がたまに乱れるという問題があります。
これは、多分フロー制御をしていないからですね。
ソフトウェアフロー制御をしないといけないなあ・・・と思いつつ、TeraTerm の再起動で誤魔化してしまっています。
最後、蛇足ですが、ソースコードを閲覧するには、GNU GLOBAL が使いやすくてよいと思います。
個人的には、Meadow 上で GLOBAL を使っていますが、非常に快適です。
Google で GNU GLOBAL で引くと、たくさん情報が出てきます。
まだ試したことがないという方、お勧めです。
エッセンスだけ抽出して、できるだけ簡潔に、という記事を目指していたので、ソースコードなんて要らないだろうと思っていたのですが、、、
ひょっとしたら、自分の手元で動かして確かめてみたいという方がおられないとも限らないので、公開することにします。
公開するといっても、x-loader にちょろちょろと手を入れているだけのソースコードですが (^^;
これです↓
ソースコードのページ
ビルド方法については、「開発環境のインストール」「x-loader ビルド」「Windows 開発環境」の回の記事を参照してください。
CodeSourcery をインストールしてあれば、
・tar-ball を展開
・xloader ディレクトリができるので、そこに移動
・make omap3530beagle_config
・make
・./signGP x-load.bin
・cp x-load.bin.ift MLO
・MLO を SD カードにコピー
で OK です。
私がいつも使っている SD カードは、「angstrom ブート」の記事中の方法で作ったもので、FAT32 と ext3 が混在したものなのですが、多分、全体を FAT32 でフォーマットしたものでも大丈夫です。
MLO を、FAT32 領域にコピーしてください。
USER ボタンを押下しながら電源を入れると、beagleboard は SD カードから MLO (=x-loader) をロードして実行します。
PC 側のシリアル端末は、なんでもいいと思いますが、私は TeraTerm を使っています。
ボーレートは、115200 bps にしてください。
無事 x-loader が実行されると、コマンドプロンプトらしき '>' マークが表示されます。
このプロンプトでは、次のコマンドを受け付けます:
i : UART 割り込みテスト
d : UART DMA テスト
t : タイマーテスト
l : LED テスト
b : ボタンテスト
s : SDRAM テスト
n : NAND テスト
sd: SD カードテスト
m : DSS テスト
各テストの内容は、以下です。
UART 割り込みテスト
「UART 割り込みモード」の回に作ったものです。
UART3 を割り込みモードに設定し、'q' が入力されるまでループします。
1 秒おきに "uart_interrupt_test" という文字列をシリアルコンソールに表示します。
'q' 以外を入力すると、"OK" という文字列をシリアルコンソールに表示します。
'q' を入力するとコマンドプロンプトに戻ります。
UART DMA テスト
「UART DMA モード」の回に作ったものです。
UART3 を DMA モードに設定し、シリアルコンソールから 8 文字入力されるまで、ビジーループします。
UART3 に入力された 8 文字は、DMA によって dma_buf 上に転送されます。
転送された 8 文字をシリアルコンソールに出力した後、コマンドプロンプトに戻ります。
タイマーテスト
「タイマーとコンテキストスイッチ」の回に作ったものです。
タスクを 2 つ追加し、3 秒おきにコンテキストスイッチを行います。
'q' を入力するとコマンドプロンプトに戻ります。
ただし、'q' を入力しても、即座にはコマンドプロンプトには戻りません。
メインタスクに実行権が移った時、'q' が入力されたかどうかがチェックされます。
LED テスト
「LED とボタン」の回に作ったものです。
LED を点滅させます。
'q' を入力するとコマンドプロンプトに戻ります。
ボタンテスト
「LED とボタン」の回に作ったものです。
USER ボタンを押下すると、シリアルコンソールに "button pressed", "button released" を表示します。
'q' を入力するとコマンドプロンプトに戻ります。
SDRAM テスト
SDRAM の読み書きを全領域にわたって行います。
テストが完了すると、サイクルカウンターの値をシリアルコンソールに出力してコマンドプロンプトに戻ります。
NAND テスト
「メモリ」の回に作ったものです。
NAND テストは、以下の 4 つのテストから成ります:
ns: NAND ステータステスト
NAND ステータスを取得します。
ステータス取得後、コマンドプロンプトに戻ります。
nr: NAND 読み出しテスト
オフセット 0x07FE0000 から 1 ページ読み出します。
これは、最も高位にあるページです。
読み出し先は、0x88000000 という SDRAM 上の適当なアドレスです。
読み出し完了後、読み出した値を表示して、コマンドプロンプトに戻ります。
ne: NAND 消去テスト
オフセット 0x07FE0000 からの 1 ページを消去します。
消去完了後、コマンドプロンプトに戻ります。
np: NAND プログラムテスト
2 つの引数、off と len を取ります(引き数 off は 1 桁の値のみ・・・)。
np 6 10 のように入力して引数を渡します。
オフセット 0x07FE0000 + off に 0x88000000 に書かれているデータを長さ len 分だけ書き込みます。
書き込み完了後、コマンドプロンプトに戻ります。
SD カードテスト
「FAT ファイルシステム」の回に作ったものです。
1 つの引き数 blknr を取ります。
sd 10 のように入力して引数を渡します。
SD カードから、ブロック番号 blknr から 1 ブロック分読み出します。
読み出した値をシリアルコンソールに出力した後、コマンドプロンプトに戻ります。
DSS テスト
「LCD 表示」「LCD 表示 (2)」の回に作ったものです。
このテストを試すには、HDMI-DVI 変換ケーブルで beagleboard と液晶ディスプレイを接続しておく必要があります。
DSS テストは、32 個のサブコマンドがあります。
'm' の後に、空白文字を 1 つ挟んで、サブコマンド番号を入力します。
m 0:
640 x 480 @ 60Hz で DSS を初期化します。
m 1:
640 x 480 @ 75Hz で DSS を初期化します。
m 2:
800 x 600 @ 60Hz で DSS を初期化します。
m 3:
1024 x 768 @ 60Hz で DSS を初期化します。
m 4:
1280 x 1024 @ 60Hz で DSS を初期化します。
m 5:
fuji.bgr を SD カードから読み出して、Video1 画面に表示します。
fuji.bgr は、640 x 512 サイズ、RGB24 フォーマット (データ並び順は BGR) の画像データです。
m 6:
Video1 画面を無効化します。
m 7:
Video2 画面を無効化します。
m 8:
Graphics 画面を無効化します。
m 9:
asa.bgr, cake.bgr, shin.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
asa.bgr, cake.bgr, shin.bgr は、いずれも 640 x 512 サイズ、RGB24 フォーマット (データ並び順は BGR) の画像データです。
画像の配置は、1280 x 1024 にちょうど収まるような配置にしています。
m 10:
asa.bgr, cake.bgr, shin.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
コマンド 9 と違って、重なり表示をするようにしています。
ついでに重なったまま動きます。
m 11:
fuji.bgr を SD カードから読み出して、Video1 画面に拡大表示します。
m 12:
fuji.bgr を SD カードから読み出して、Video1 画面に縮小表示します。
※ 1280 x 1024 でこれを実行すると、画面が乱れてしまいますので、1024 x 768 でお試しください。
m 13:
fuji.bgr を SD カードから読み出して、Video1 画面上で徐々に拡大させていきます。
m 14:
asa_a.bgr, cake_a.bgr, shin_a.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
asa_a.bgr, cake_a.bgr, shin_a.bgr は、いずれも 640 x 512 サイズ、ARGB32 フォーマット (データ並び順は BGRA) の画像データです。
アルファブレンドは、すべてのピクセルにおいて、50% (アルファ値としては 0x80) にしています。
画像の配置は、1280 x 1024 にちょうど収まるような配置にしています。
m 15:
asa_a.bgr, cake_a.bgr, shin_a.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
コマンド 14 と違って、重なり表示をするようにしています。
※ 1280 x 1024 でこれを実行すると、画面が乱れてしまいますので、1024 x 768 でお試しください。
m 16:
asa.bgr を SD カードから読み出して、Video2 画面に表示します。
m 17:
asa_a.bgr を SD カードから読み出して、Video2 画面に表示します。
m 18:
asa_a0.bgr を SD カードから読み出して、Video2 画面に表示します。
asa_a0.bgr は 640 x 512 サイズ、ARGB32 フォーマットの画像データ (データ並び順は BGRA) で、アルファブレンドはすべてのピクセルにおいて、100% (アルファ値としては 0x00)にしています。
アルファブレンドを有効にすると、asa_a0.bgr は透過率 100% となって表示されません。
m 19:
asa_aff.bgr を SD カードから読み出して、Video2 画面に表示します。
asa_aff.bgr は 640 x 512 サイズ、ARGB32 フォーマットの画像データ (データ並び順は BGRA) で、アルファブレンドはすべてのピクセルにおいて、0% (アルファ値としては 0xff)にしています。
m 20:
アルファブレンドを有効にし、Video2 画面、Graphics 画面のグローバルアルファブレンドを 0% (アルファ値としては 0xff) にします。
アルファブレンド 0% は、全く透過させないことを意味します。
コマンド 16 - 19 によって表示された画像は、画像データ中のアルファ値によってのみアルファブレンドが決定されます。
m 21:
アルファブレンドを有効にし、Video2 画面、Graphics 画面のグローバルアルファブレンドを 50% (アルファ値としては 0x80) にします。
コマンド 16 - 19 で表示された画像は、グローバルアルファ値と画像データ中のアルファ値の相乗でアルファブレンドが決定されます。
m 22:
アルファブレンドを無効にします。
m 23:
tckgfx.bgr, tckvid1.bgr, tckvid2.bgr を SD カードから読み出して、それぞれ Video1 画面、Video2 画面、Graphics 画面に表示します。
m 24:
transparency color key を有効にします。
コマンド 23 で表示された画像は、コマンド 24 によって影響を受けます。
m 25:
transparency color key を無効にします。
m 26:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
fuji32.bgr は、640 x 480 サイズ、RGB24 (un-packed in 32-bit container) フォーマット (データ並び順は BGRX) の画像データです。
"un-packed in 32-bit container" と言っているのは、BGR 24ビットの後に、適当な pad データを入れて 32 ビットにしているという意味です。
m 27:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
1行 1行の間隔を空けて配置した画像データを表示できるように、DISPC_VID_ROW_INC レジスタへ正しく値設定できているか確かめるためのテストです。
m 28:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
表示する画像は、VRFB Context 1 の 90 度回転画像です。
m 29:
fuji32.bgr を SD カードから読み出して、Video2 画面に表示します。
表示する画像は、VRFB Context 2 の 180 度回転画像です。
m 30:
fuji32.bgr を SD カードから読み出して、Graphics 画面に表示します。
表示する画像は、VRFB Context 3 の 270 度回転画像です。
m 31:
fuji32.bgr を SD カードから読み出して、Video1 画面に表示します。
表示する画像は、VRFB Context 4 の 0 度回転画像です。
m 32:
VRFB に書き込んだデータが、SDRAM 上でどのように配置されるかを確認するためのテストです。
ソースコードのページ に、DSS テストで使用する画像データも一応用意してあります。
dsspic.zip を取得・展開して、すべて SD カードにコピーしてください。
・・・
今までの記事の中で、これらのソースコードが部分的に登場していますが、記事の中のソースコードと現状のソースコードでは、行番号が違っていたりするかもしれません。
ただ、大幅に変わってしまって、原型をとどめていない、というようなことはないと思います。
あと、シリアルコンソールに大量出力すると、シリアルコンソールの表示がたまに乱れるという問題があります。
これは、多分フロー制御をしていないからですね。
ソフトウェアフロー制御をしないといけないなあ・・・と思いつつ、TeraTerm の再起動で誤魔化してしまっています。
最後、蛇足ですが、ソースコードを閲覧するには、GNU GLOBAL が使いやすくてよいと思います。
個人的には、Meadow 上で GLOBAL を使っていますが、非常に快適です。
Google で GNU GLOBAL で引くと、たくさん情報が出てきます。
まだ試したことがないという方、お勧めです。
beagleboard を触ろう - LCD 表示 (2) [組み込みソフト]
前回記事で、外部 LCD に画像を表示させてみましたが、今回はその続きです。
LCD に画像を表示するには、Display Subsystem (DSS) モジュールを使えばいいのでした。
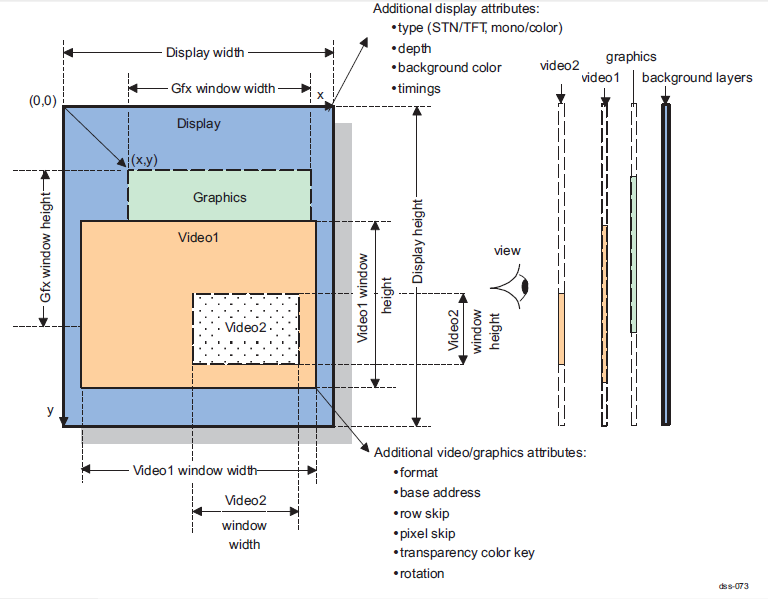
DSS は、Video1, Video2, Graphics 各画面を独立に表示できます。
DSS を設定して、Video1, Video2, Graphics 画面に画像を表示させたというところまでが、前回やったことです。
今回は、アルファブレンド、Transparent Color Key、拡大・縮小、回転を試してみます。
アルファブレンド
アルファブレンドは、画像を透過させる機能です。
アルファ値の大小によって、透過度が変わってきます。
アルファ値は 0x00 - 0xff まで指定できて、0x00 は 100 % を表し、0xff は 0% を表します。
アルファブレンド 100% は、100% 透過することを意味し、0% は全く透過しないことを意味します。
こんなオリジナル↓に対して、

50% 透過だと、こんな感じ↓です。
背景画面の緑色が透けて見えます。

アルファブレンドを有効にするかどうかを決定するのは、DISPC_CONFIG レジスタの LCDALPHABLENDERENABLE ビットです。
アルファブレンドが適用されるのは、Video2 画面、および Graphics 画面です。
Video1 画面には適用されません。

アルファ値は、DISPC_GLOBAL_ALPHA レジスタに設定する値か、もしくは画像データに埋め込んだ値で決定することができます。
DISPC_GLOBAL_ALPHA レジスタでアルファ値を設定した場合は、Video2 画面, Graphics 画面の全ピクセルにおいて、設定したアルファ値が一律に適用されます。
一方、画像データに埋め込む場合は、各ピクセル毎にアルファ値を設定・適用できます。
DSS がサポートしている画像フォーマットに、ARGB 16, ARGB 32, RGBA 32 というのがありますが、この A がアルファ値を表します。
DISPC_GLOBAL_ALPHA レジスタでアルファ値を設定した場合、Video2 画面、Graphics 画面の画像フォーマットが ARGB/RGBA か、それ以外の (A なし) フォーマットかに関わらず、画面は透過します。
ARGB/RGBA であれば、相乗でさらに透過します。
DISPC_GLOBAL_ALPHA レジスタのアルファブレンドが 50%、画像フォーマットが RGB 32 の場合は、こうなります↓
DISPC_GLOBAL_ALPHA レジスタのアルファブレンドが 50%、画像フォーマットが RGBA 32 で、各ピクセルのアルファブレンドが 50% の場合は、こうなります↓
透過度が大きくなるので、緑っぽさが強くなりますね。

DISPC_GLOBAL_ALPHA レジスタのアルファブレンドが 0%、画像フォーマットが RGBA 32 で、各ピクセルのアルファブレンドが 0% の場合は、透過しません↓

なお、アルファブレンドを有効にした場合、Video1, Video2, Graphics 画面の表示優先順位が変わります。
アルファブレンドが無効の場合は、表示優先順位は、Video2 > Video1 > Graphics > 背景画面 です↓(前回記事にて既出)
アルファブレンドが有効の場合は、これが Graphics > Video2 > Video1 > 背景画面 となります↓
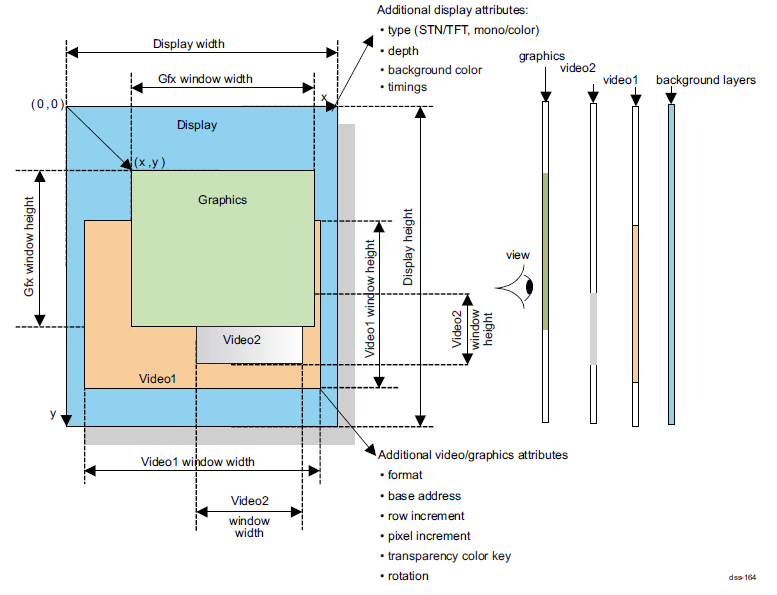
実際にアルファブレンドを有効にして重ね合わせてみると、こんな感じです↓
この写真では、優先順位がどうだか、わけが分かりませんが (^^;
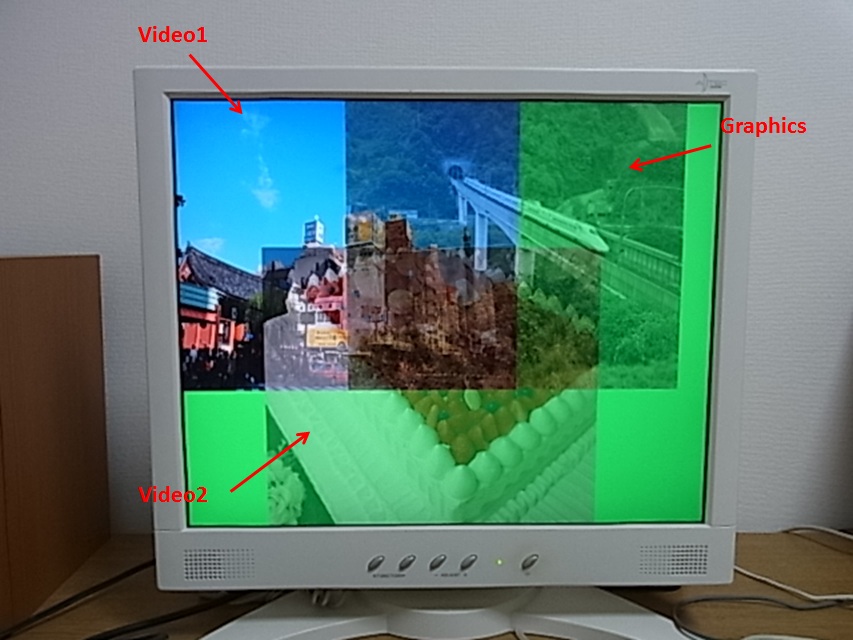
上の写真は、1024 x 768 @ 60Hz で試したものです。
これを、1280 x 1024 @ 60Hz で試すと、こんな風になります↓

うむむ、なんか、乱れてて変です。
うーん・・・と悩ましく思っていると、1280 x 1024 @ 60Hz の時は、ピクセルクロック 108MHz という、無理目な値で動作させていることが思い出されてきました。
OMAP35x TRM には、"Programmable pixel rate up to 75MHz" という記述があって、108MHz は上限オーバーではないかと思っていたのです。
そのせいかどうか、定かではありませんが・・・。
Transparent Color Key
Video1 画面、Video2 画面、Graphics 画面が重なって表示される場合、重なり部分は、表示優先順位に従って表示されます。
アルファブレンドなしの場合は、再掲で恐縮ですが、表示優先度は Video2 > Video1 > Graphics > 背景画面 です。
Video1/Video2 画面と Graphics 画面が重なると、Graphics 画面の重なった部分は表示されません。
Transparent Color Key は、指定した箇所を透明にして、下の画面を見せるようにする機能です。
透明にする箇所は、色によって指定します。
この機能は、絵で見れば一目瞭然です。
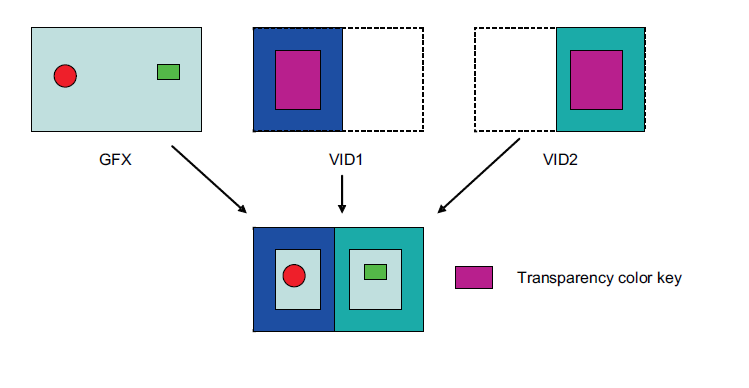
設定は簡単です。
DISPC_CONFIG レジスタの TCKLCDSELECTION ビットと TCKLCDENABLE ビットを立て、DISPC_TRANS_COLOR_0 レジスタに、透明にする箇所の色を設定するだけです。
実際にやってみましょう。
Video1, Video2, Graphics 画面は、それぞれ↓のようなものです。
Video1

Video2

Graphics

Transparency Color Key を無効のままにして Video1, Video2, Graphics 画面を重ねると、↓のようになります。
Graphics 画面は完全に隠れます。

ここで、Transparency Color Key を有効にして、紫色を Transparency Color Key として設定すると、↓のようになります。
紫だった部分が、透けて見えるようになることが分かりますね。

拡大・縮小
Video1, Video2 画面は、拡大・縮小表示させる機能を持っています。
Graphics 画面は、拡大・縮小できません。
拡大・縮小に関して、詳しいことは全然知らないのですが (^^; 元の画素の近傍何点かを使って、拡大・縮小した画素を作るものと思います。
DSS の拡大・縮小機能は、水平方向 5 点、垂直方向 3 点を使うか、もしくは水平方向 5 点、垂直方向 5 点を使うか、いずれかが選択できます。
これら近傍点の画素に重み付け係数をかけ合わせ、新しい画素を作るようになっていると思います。
レジスタ設定的にも、重み付け係数をいちいち設定してやる必要があります。
拡大・縮小のアルゴリズムによって、重み付け係数は適当に設定してね、ということだと思いますが、素人にはどうすればいいか、さっぱり分かりません (T_T)
OMAP35x TRM には、Max-Fauque-Berthier method を使う場合の重み付け係数の値が載っていました。
Max-Fauque-Berthier method とは??
・・・うーん、さっぱり分かりません。
さっぱり分かりませんが、Max-Fauque-Berthier method による拡大・縮小表示を試します。
設定するレジスタは、前回の↓に加えて、
DISPC_VIDn_BA0
DISPC_VIDn_POSITION
DISPC_VIDn_SIZE
DISPC_VIDn_PICTURE_SIZE
DISPC_VIDn_FIFO_THRESHOLD
DISPC_VIDn_FIFO_SIZE_STATUS
DISPC_VIDn_ROW_INC
DISPC_VIDn_PIXEL_INC
DISPC_VIDn_ATTRIBUTES
以下を追加で設定します↓
DISPC_VIDn_FIR
DISPC_VIDn_ACCU
DISPC_VIDn_FIR_COEF_Hi
DISPC_VIDn_FIR_COEF_HVi
275: /* VINC, HINC */
276: firvinc = 1024 * (orgsizey - 1) / (sizey - 1);
277: firhinc = 1024 * (orgsizex - 1) / (sizex - 1);
278: __raw_writel((firvinc << 16) | firhinc, DISPC_VID_FIR(n));
DISPC_VIDn_FIR レジスタの VIDFIRVINC, VIDFIRHINC に、垂直方向の拡大・縮小率、水平方向の拡大・縮小率を設定します。
設定する値は、1024 * (元の長さ - 1) / (拡大・縮小後の長さ - 1) です。
280: /* accumulator */
281: __raw_writel(0x0, DISPC_VID_ACCU(n, 0));
このレジスタはよく分からないのですが、LCD の場合は 0 にせよと OMAP35x TRM に書いてあったので、盲目的に 0 を設定します (^^;
283: /* coefficients */
284: __raw_writel(0x00800000, DISPC_VID_FIR_COEF_H(n, 0));
285: __raw_writel(0x00800000, DISPC_VID_FIR_COEF_HV(n, 0));
286: __raw_writel(0x0D7CF800, DISPC_VID_FIR_COEF_H(n, 1));
287: __raw_writel(0x037B02FF, DISPC_VID_FIR_COEF_HV(n, 1));
288: __raw_writel(0x1E70F5FF, DISPC_VID_FIR_COEF_H(n, 2));
289: __raw_writel(0x0C6F05FE, DISPC_VID_FIR_COEF_HV(n, 2));
290: __raw_writel(0x335FF5FE, DISPC_VID_FIR_COEF_H(n, 3));
291: __raw_writel(0x205907FB, DISPC_VID_FIR_COEF_HV(n, 3));
292: __raw_writel(0xF74949F7, DISPC_VID_FIR_COEF_H(n, 4));
293: __raw_writel(0x00404000, DISPC_VID_FIR_COEF_HV(n, 4));
294: __raw_writel(0xF55F33FB, DISPC_VID_FIR_COEF_H(n, 5));
295: __raw_writel(0x075920FE, DISPC_VID_FIR_COEF_HV(n, 5));
296: __raw_writel(0xF5701EFE, DISPC_VID_FIR_COEF_H(n, 6));
297: __raw_writel(0x056F0CFF, DISPC_VID_FIR_COEF_HV(n, 6));
298: __raw_writel(0xF87C0DFF, DISPC_VID_FIR_COEF_H(n, 7));
299: __raw_writel(0x027B0300, DISPC_VID_FIR_COEF_HV(n, 7));
これらが、近傍点の重み付け係数です。
Max-Fauque-Berthier method に従って、値を設定します。(キリッ
(設定する値は、OMAP35x TRM に載っています。)
DISPC_VIDn_BA0
DISPC_VIDn_POSITION
DISPC_VIDn_SIZE
DISPC_VIDn_PICTURE_SIZE
DISPC_VIDn_FIFO_THRESHOLD
DISPC_VIDn_FIFO_SIZE_STATUS
DISPC_VIDn_ROW_INC
DISPC_VIDn_PIXEL_INC
DISPC_VIDn_ATTRIBUTES
これらのレジスタ↑は、前回と同じように設定します。
前回と違うところは、
- DISPC_VIDn_SIZE レジスタに拡大・縮小後の表示サイズを、DISPC_VIDn_PICTURE_SIZE レジスタに元の大きさを設定すること
- DISPC_VIDn_ATTRIBUTES レジスタの VIDRESIZEENABLE ビットフィールドを設定して拡大・縮小を有効化すること
です。
DISPC_VIDn_ATTRIBUTES レジスタの VIDRESIZEENABLE ビットフィールドには、
- 拡大・縮小しない場合は 0
- 水平方向に拡大・縮小する場合は 1
- 垂直方向に拡大・縮小する場合は 2
- 水平方向・垂直方向ともに拡大・縮小する場合は 3
を設定します。
実際にやってみると、こんな感じです↓
元画像

1.5 倍に拡大

5/8 に縮小

10msec 毎に 1 ピクセルずつ拡大してみました↓
ダウンロードは🎥こちら
回転
90度、180度、270度、回転させた画像を表示させることができます。
回転表示させるには、方法が 2 つあります。
1 つは、DSS の DMA engine の回転機能を使う方法と、SDRAM コントローラの回転機能を使う方法です。
(内臓 SRAM に画像データを置く場合は、前者の方法しか使えません。)
OMAP35x TRM には、パフォーマンスの観点から後者をお勧めします、というようなことが書いてあります。
なので、ここでも素直に後者の方法で回転を試してみます。
OMAP3530 内の SDRAM Controller Subsystem は、SDRC と SMS というモジュールから成っています。
(SDRC については、「メモリ」の回で触れました。)
SMS は、メモリアクセス要求のスケジューリングをしたり、アクセス制限をつけたりする機能を持つモジュールですが、Rotation engine も持っています。
Rotation engine は、OMAP35x TRM では、VRFB とか、Rotation engine とか、略して RE とか呼ばれています。
ある特定のアドレスでアクセスすると、Rotation engine を経由して SDRAM にアクセスするようになっています。
この特定のアドレスは、0x7000_0000 - 0x7FFF_FFFF までの 256MB の領域と、0xE000_0000 - 0xFF00_0000 までの 512MB の領域として割り当てられています。
下の表のように、この領域は 12 分割されています。
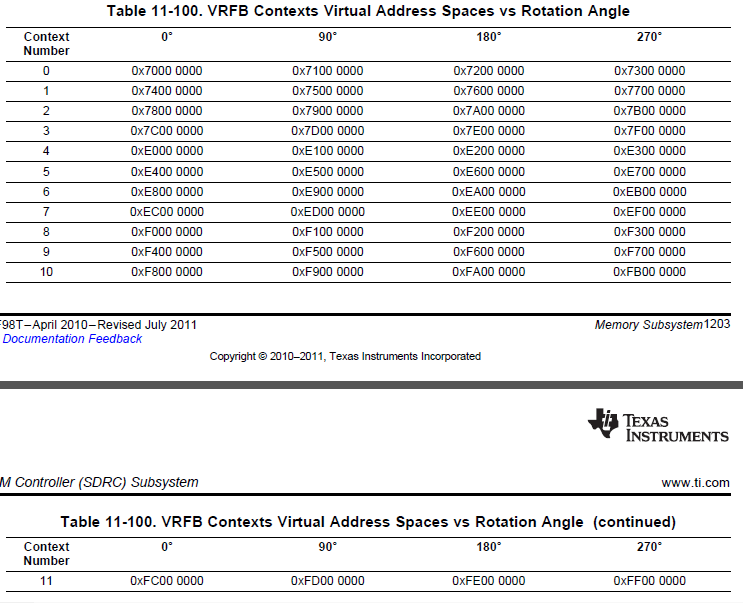
これらは、12個の独立した領域です。
どのように使うかというと、
例えば、ある画像 A を、0x7000_0000 に書き込んだとします。
0x7000_0000 から読み出すと、画像 A の 0 度回転した画像データが得られます。
0x7100_0000 から読み出すと、画像 A の 90 度回転した画像データが得られます。
0x7200_0000 から読み出すと、画像 A の 180 度回転した画像データが得られます。
0x7300_0000 から読み出すと、画像 A の 270 度回転した画像データが得られます。
また、他の画像 B を、0x7400_0000 に書き込んだとします。
0x7400_0000 から読み出すと、画像 B の 0 度回転した画像データが得られます。
0x7500_0000 から読み出すと、画像 B の 90 度回転した画像データが得られます。
0x7600_0000 から読み出すと、画像 B の 180 度回転した画像データが得られます。
0x7700_0000 から読み出すと、画像 B の 270 度回転した画像データが得られます。
こんな感じで、12 分割された各領域を使うことができます。
この各領域のことを、OMAP35x TRM では、VRFB Context と呼んでいます。
Texas Instruments としては、携帯端末を横向き、縦向きに変えた際に画像を回転させる時とかに、この機能を使いなさいよ、ということみたいです。
各 VRFB Context の実体は、SMS_ROT_PHYSICALn レジスタによって設定します。
例えば、VRFB Context 1 の実体を 0x8000_0000 (= SDRAM 先頭アドレス) に設定するには、SMS_ROT_PHYSICAL1 レジスタに 0x8000_0000 を設定します。
こうしておけば、VRFB Context1 の 0 度回転領域 0x7400_0000 に書き込んだ画像データは、 実アドレス 0x8000_0000 の領域に書き込まれます。
また、90 度回転領域 0x7500_0000 から読み出されるデータは、実アドレス 0x8000_0000 の領域から読み出されます。
もちろん、180 度回転領域 0x7600_0000, 270 度回転領域 0x7700_0000 から読み出されるデータも、実アドレス 0x8000_0000 の領域から読み出されたものになります。
各回転領域における画像データの配置は、以下のようになります。
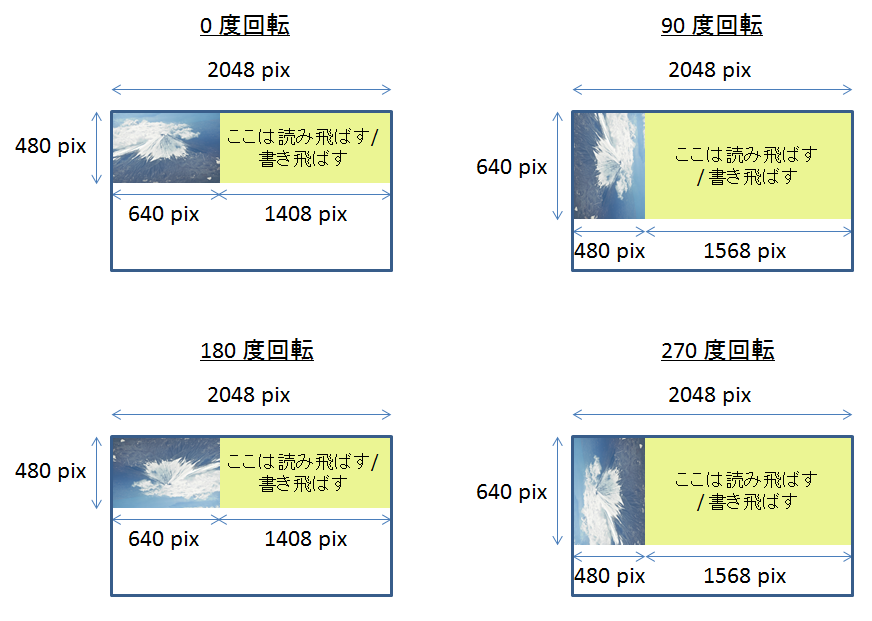
どの回転領域からアクセスする場合でも、横幅 2048 ピクセルの領域内に画像データが配置されているものとしてアクセスする必要があります。
例えば、0x7400_0000 (VRFB Context 1 の 0 度回転領域) にサイズ 640 x 480、画像フォーマット RGB32 (1 ピクセル = 4 バイト) の画像データを書き込むことを考えてみましょう。
まず、先頭の 1 行分 640 ピクセル (= 640 x 4 バイト) を、0x7400_0000 に書き込みます。
(0x7400_0000 - 0x7400_0A00)
次の 2 行目は、0x7400_0000 + 2048 x 4 = 0x7400_2000 から書き込みます。
(0x7400_2000 - 0x7400_2A00)
同様に、次の 3 行目は、0x7400_2000 + 2048 x 4 = 0x7400_4000 から書き込みます。
(0x7400_4000 - 0x7400_4A00)
以下、同様です。
このように、行と行の間には、適切にオフセットを入れる必要があります。
上の例だと、オフセットの値は、(2048 - 640) x 4 になります。
0x7500_0000 (VRFB Context 1 の 90 度回転領域) から、画像データを読んでみましょう。
90 度回転なので、480 x 640 の画像になります。
まず、先頭の 1 行分 480 ピクセル (= 480 x 4 バイト) を、0x7500_0000 から読み出します。
(0x7500_0000 - 0x7500_0780)
次の 2 行目は、0x7500_0000 + 2048 x 4 = 0x7500_2000 から読み出します。
(0x7500_2000 - 0x7500_2780)
同様に、次の 3 行目は、0x7500_2000 + 2048 x 4 = 0x7500_4000 から読み出します。
(0x7500_4000 - 0x7500_4780)
以下、同様です。
VRFB にアクセスするには、このようなルールを守ってアクセスする必要があります。
さもないと、正しい回転画像が得られません。
DSS に VRFB から読み出させる場合は、DSS の DMA engine が適切にオフセットを挟むように、設定する必要があります。
0x7400_0000 (VRFB) に書き込まれたデータは、0x8000_0000 (SDRAM) ではどのように配置されるのでしょうか。
多分ですが、こんなです↓
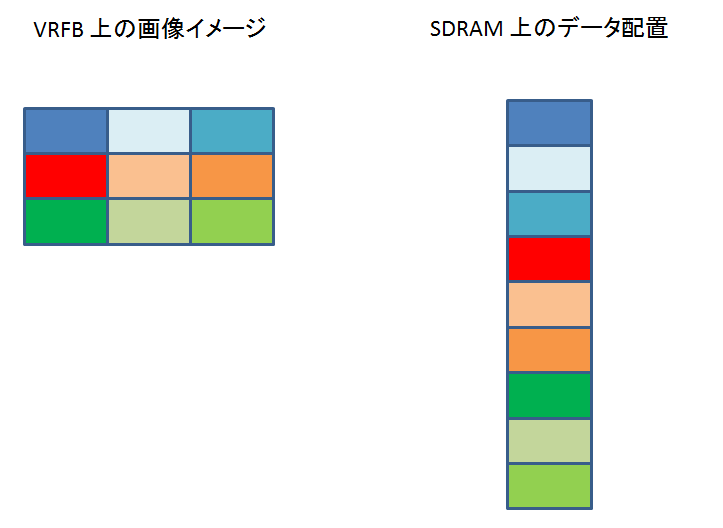
VRFB を介さないで、普通に画像データを書き込んだ場合は、以下のようになります↓
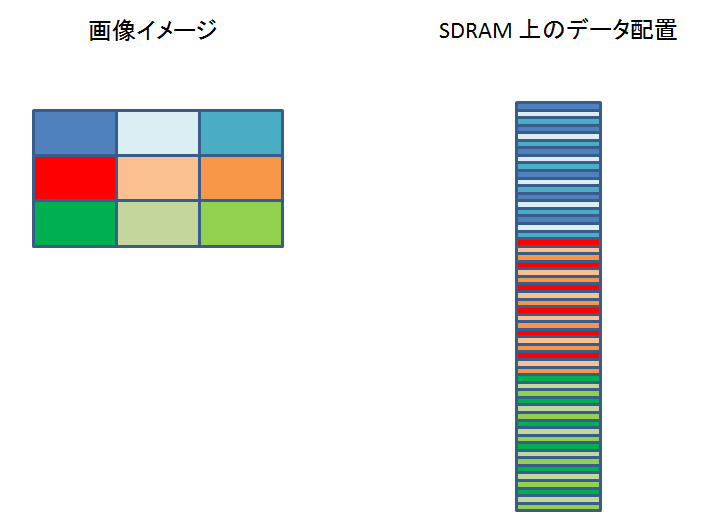
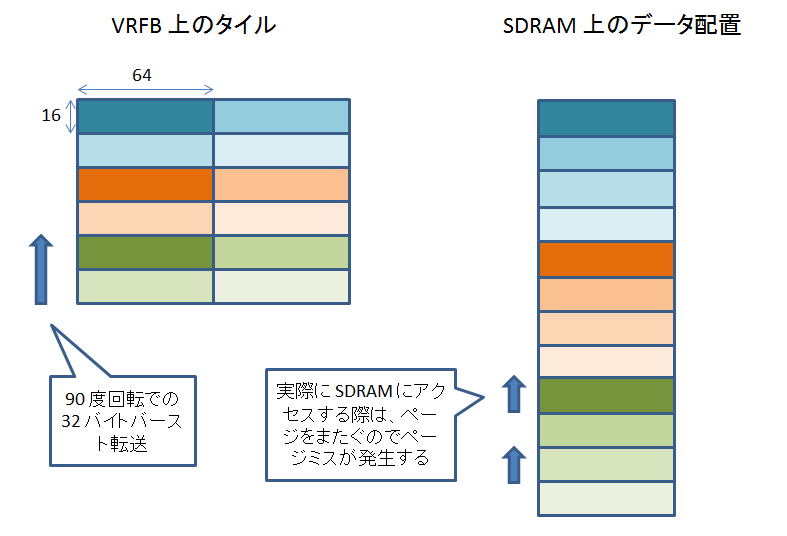
VRFB を介さないで書き込んだ場合、90 度回転させるケースを考えると、DSS の DMA engine が SDRAM からパラレル LCD 出力にデータを転送する際、各バースト転送ごとにページミスが発生してしまいます。
しかし、VRFB 経由で書き込まれたデータの方は、ページミスが発生しません。
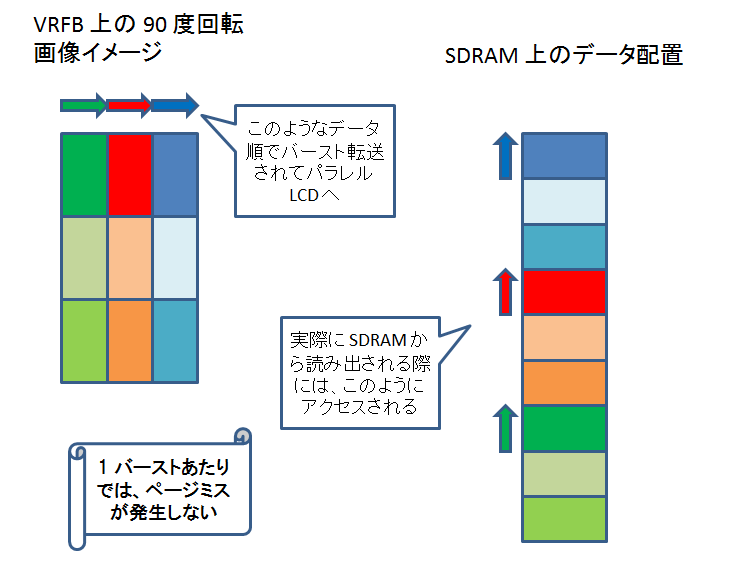
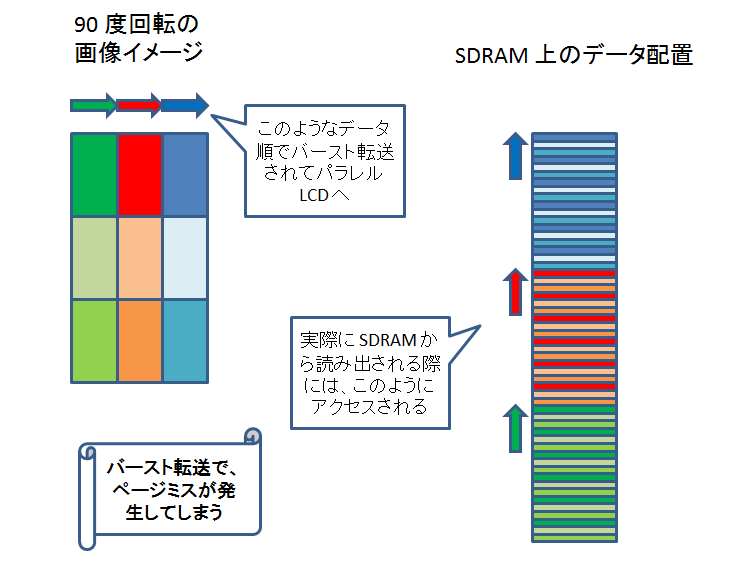
VRFB を介さないで書き込んだ場合、0 度回転、180 度回転の場合はページミスが発生しません。
VRFB 経由で書き込まれたデータの方も、0 度回転、180 度回転の場合でもページミスが発生しません。
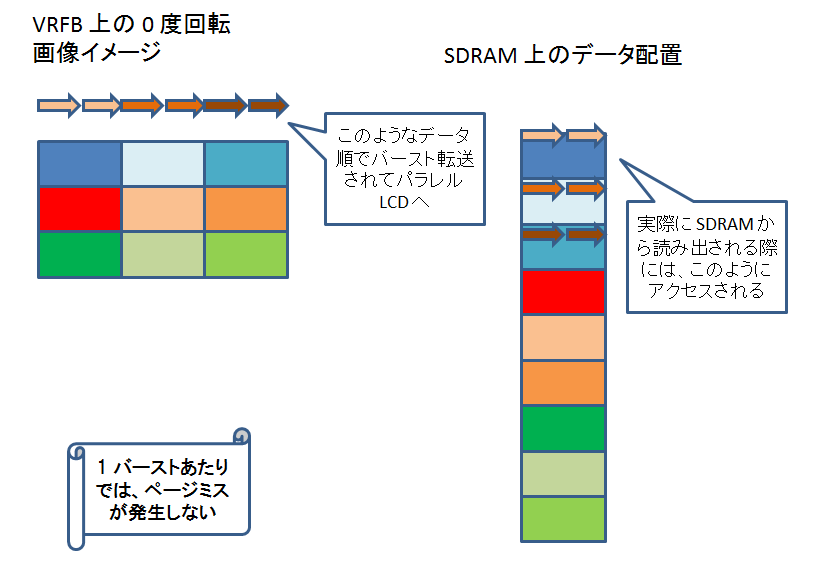
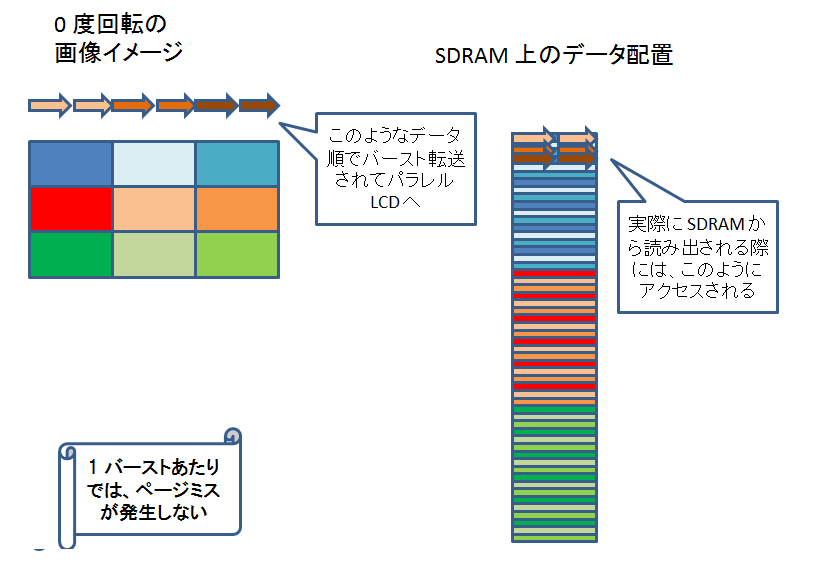
VRFB を介さないで書き込んだ場合は、90 度回転、270 度回転の場合にページミスが発生してしまいますが、VRFB 経由の場合は、どの回転角度でもページミスが発生しません。
というわけで、VRFB を使うと、DSS の DMA engine の回転機能を使う場合に比べて、パフォーマンスが向上します。(するはずです。)
SMS Rotation engine (VRFB) は、タイルベースで画像データを扱います。
実際にプログラミングする際には、タイルサイズを定義する必要があります。
タイルサイズの定義は、VRFB に書き込んだデータが、実際の SDRAM にどのように配置されるかに効いてきます。
タイルサイズは、SDRAM のページサイズと一致させておく必要があります。
beagleboard に搭載されている SDRAM のページサイズは、1024 バイトです。(多分。)
1024 バイトのタイルサイズだと、考えられるのは、
- 32 x 32
- 64 x 16 (16 x 64)
- 128 x 8 (8 x 128)
- 256 x 4 (4 x 256)
- 512 x 2 (2 x 512)
- 1024 x 1 (1 x 1024)
があります。
このうち、32 x 32, 64 x 16, 128 x 8 の場合の、VRFB と実 SDRAM の対応関係を見てみましょう。
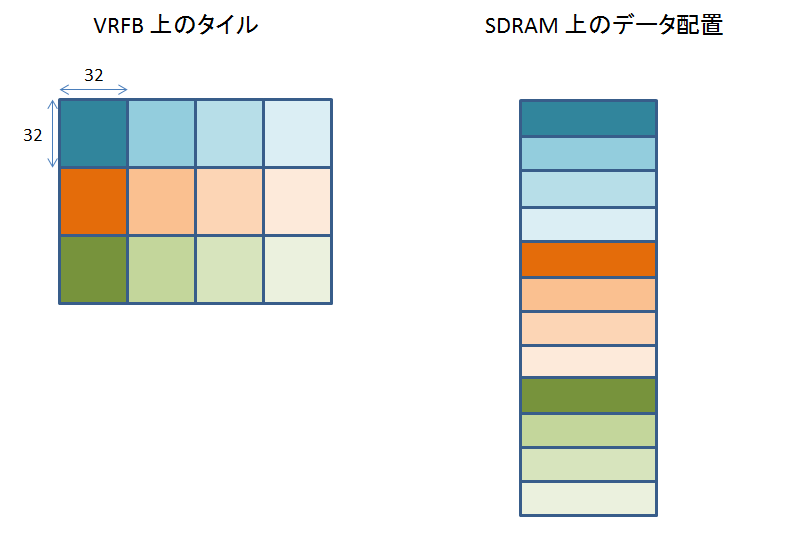
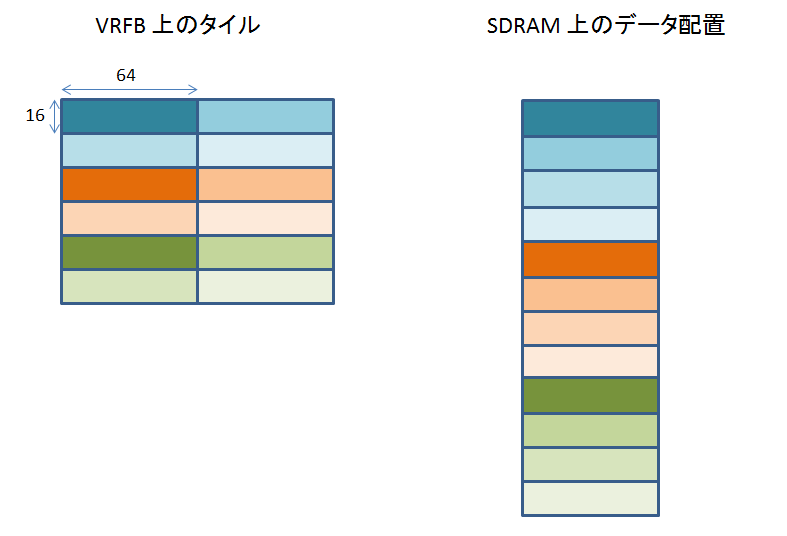
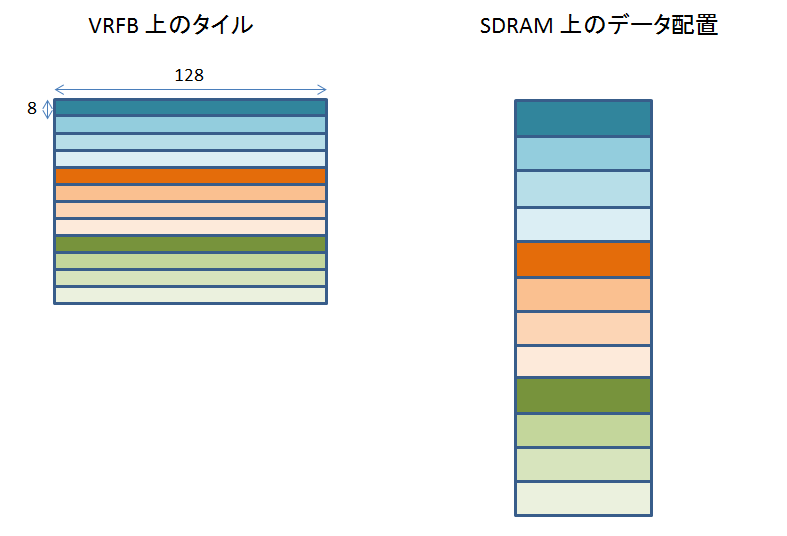
このように、タイルサイズの違いによって、SDRAM に格納されるデータの配置が変わります。
では、どのタイルサイズを選択すればいいかというと、できるだけ正方形に近い組み合わせです。
タイルサイズ (= SDRAM のページサイズ) が 1024 バイトならば、32 x 32 にしておけば OK です。
64 x 16 でも、そんなには悪くありません。
しかし、64 x 16 の場合、DSS の DMA engine のバースト長を 32 バイトにしている時は、バースト転送するたびに SDRAM でページミスが発生することになってしまいます。
実際の画像は、このタイル上に配置するようなイメージです。
VRFB の設定レジスタ SMS_ROT_SIZEn にイメージ幅、イメージ高さを指定する必要があるのですが、設定する値は、実際の画像の大きさではなく、タイルの大きさです。
下の絵で言えば、イメージ幅は 96, イメージ高さは 64 を指定します。
タイル 1 つが、SDRAM の 1 ページ分に相当し、適切に並び替えられて SDRAM に配置されます。
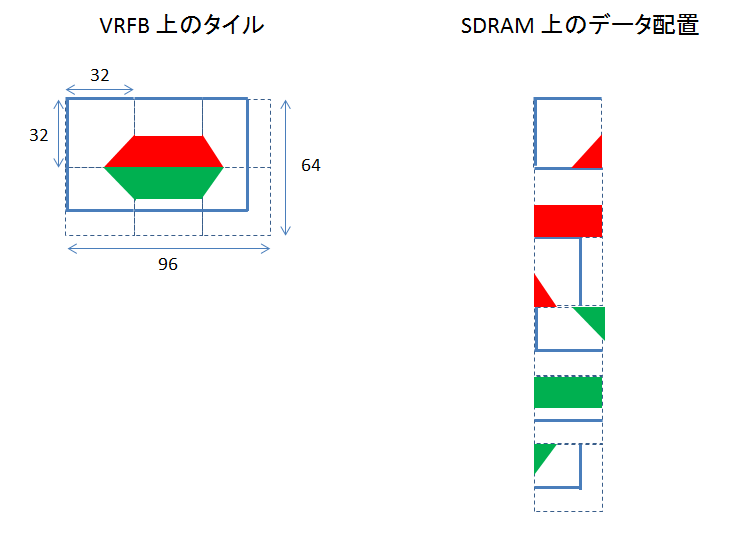
画像がタイルサイズにぴったり合うと、ちょっとだけですが、扱いやすくなります。
今回は、640 x 480 の画像を使います。
これだと、32 x 32 の大きさのタイルが 20 x 15 になって、幅、高さとも整数倍になります。
それでは、実際に回転させてみましょう。
設定するレジスタは、SMS Rotation engine 関連では、以下の 3 つです。
SMS_ROT_CONTROLn
SMS_ROT_SIZEn
SMS_ROT_PHYSICAL_BAn
(n = 0 - 11)
VRFB Context は 12 個あるので、上記レジスタも 12 セットあります。
これらのレジスタには、タイルサイズ、ピクセルサイズ、イメージ幅、イメージ高さ、画像を配置する SDRAM 上の実アドレスを指定します。
461: int set_vrfb(int n, unsigned long ba, int orgsizex, int orgsizey, int format)
462: {
463: unsigned char ph, pw, ps;
464: unsigned short imagewidth, imageheight;
465: unsigned char bpp;
466:
467: /* configure page width and height as 32x32, considering page size is 1KB */
468: pw = 5;
469: ph = 5;
470:
471: switch (format) {
472: case BITMAP8:
473: ps = 0;
474: bpp = 1;
475: break;
476: case RGB12_16:
477: case ARGB16:
478: case RGB16:
479: ps = 1;
480: bpp = 2;
481: break;
482: case RGB24_32:
483: case ARGB32:
484: case RGBA32:
485: ps = 2;
486: bpp = 4;
487: break;
488: default:
489: return -1;
490: }
491:
492: if (orgsizex * bpp % 32)
493: imagewidth = (orgsizex / 32 + 1) * 32;
494: else
495: imagewidth = orgsizex;
496: if (orgsizey % 32)
497: imageheight = (orgsizey / 32 + 1) * 32;
498: else
499: imageheight = orgsizey;
500:
501: __raw_writel((ph << 8) | (pw << 4) | ps, SMS_ROT_CONTROL(n));
502: __raw_writel((imageheight << 16) | imagewidth, SMS_ROT_SIZE(n));
503: __raw_writel(ba, SMS_ROT_PHYSICAL_BA(n));
468 行目、469 行目で、タイルサイズを決定しています。
32x32 のタイルサイズにするには、レジスタに設定する値は 32 ではなく、2 のべき乗数に当たる 5 になります。
471 行目から 487 行目で、引数で与えられた画像フォーマット値に対して、ピクセルサイズ ps を得ています。
ピクセルサイズ ps も、バイト数そのものではなく、2 のべき乗数を指定します。
492 行目から 499 行目で、イメージ幅、イメージ高さを決定しています。
画像幅、画像高さが、タイル幅、タイル高さの整数倍ならば、イメージ幅、イメージ高さは画像幅、画像高さと一致します。
501 行目から、503 行目で SMS Rotation engine 関連のレジスタに値を設定します。
n は、0 - 11 の間の値です。
SMS Rotation engine の設定はこれだけです。
意外と簡単です。
後は、画像を VRFB に書き込んで、別角度の VRFB から読み出すだけです。
VRFB 0 度回転の領域に画像データを書き込んで、0 度回転、90 度回転、180 度回転、270 度回転の領域を DSS に読み取らせてみましょう。
先述のように、DSS に正しく読み取らせるには、行読み出しごとに適切なオフセットを加えないといけないことに注意です。
これは、DISPC_VID_ROW_INC(n) レジスタに "オフセット値 + 1" を設定することにより、実現します。
もちろん、0 度回転の領域に画像データを書き込む際にも、適切にオフセットを挟みます。




という感じで、正しく動作しました。
ところが、、、
Video1 画面に 90 度回転画像を、Video2 画面に 180 度回転画像を、Graphics 画面に 270 度回転画像を同時に表示させると、なんかおかしくなってしまいました。

うーん・・・。
これはちょっと謎です (T_T)
・・・
今回、DSS の応用機能 (?) を触ってみました。
グラフィック関連で言えば、beagleboard 上で使えるデバイスとしては、Imagination Technologies 社の 2D/3D アクセラレータ POWERVR SGX530 があります。
こちらは、どうやら仕様は非公開のようです。
Linux のドライバは、バイナリのみ提供されているようですが。
というわけで、こちらは触りません (^^;
beagleboard を触ろう - LCD 表示 [組み込みソフト]
beagleboard から、DVI ケーブル経由で液晶ディスプレイ (LCD) に画像を表示させてみましょう。
beagleboard と液晶ディスプレイは、HDMI-DVI 変換ケーブルを使って接続します。


ちなみに、自分の LCD は、DVI コネクタと一緒にアナログ RGB コネクタも持つ、かなり古いものです。
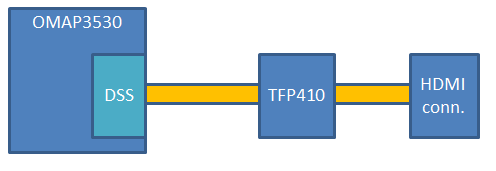
beagleboard に搭載されている HDMI コネクタは、形こそ HDMI ですが、機能的には DVI だそうで、DVI コネクタはでかいので、代わりに小さな HDMI コネクタを載せているそうです。
本来 HDMI は、画像データの他に音声データも運ぶことができますが、beagleboard の場合は、画像データのみ運べます。
beagleboard から画像データを送り出すのは、Display Subsystem (DSS) というモジュールです。
DSS を制御することにより、液晶ディスプレイに画像を表示させることができます。
DSS は、様々な外部出力に対応しています。
1. パラレル LCD 出力
2. Remote Frame Buffer Interface (RFBI)
3. Serial Display Interface (SDI)
4. Display Serial Interface (DSI)
5. NTSC/PAL
DVI ケーブルでの LCD 表示は、1 のパラレル LCD 出力を使います。
2 は、MIPI DBI プロトコルというものを使うみたいです。
MIPI は、Mobile Industry Processor Interface の略で、MIPI Alliance によって策定された規格 (インターフェース仕様/プロトコル) と思います。
DBI は、ディスプレイにパラレル出力する規格です、多分。
3 は、TI (Texas Instruments) ユニークな規格かも。
TI Flatlink なるもののようです。
4 は、2 と同じく MIPI の規格です。
こちらは、2 と違ってシリアル出力です。
5 は、TV ですね。
beagleboard では、パラレル LCD 出力の先には、TFP410 というチップがあり (SRM では DVI-D framer chip と呼ばれている)、これがパラレル LCD 出力を DVI-D 信号に変換してくれます。
DSS を適切に設定して、パラレル LCD 出力から画像データを流すようにすることが、今回の目的です。
DSS の表示機能をさらっと見てみましょう。
DSS が表示する画面は、下図のように、背景画面、Video1 画面、Video2 画面、Graphics 画面から成ります。
Video1 画面、Video2 画面、Graphics 画面は、それぞれ有効・無効を設定できます。
表示優先順位は、Video2 > Video1 > Graphics > 背景画面となります。
Video1, Video2, Graphics の大きさは、背景画面に収まる範囲内で、自由に設定することができます。
表示データは、それぞれ指定されたメモリアドレスから供給されます。
各々に専用の領域を割り当ててやれば、独立した画面を表示することができます。
背景画面の大きさは、LCD に合わせて設定します。
800x600 とか、1024x768 とか、LCD がサポートしているサイズを設定します。
画面サイズを設定するとともに、タイミングパラメータの設定も必要です。
設定するタイミングパラメータは、水平フロントポーチ、水平同期パルス幅、水平バックポーチ、垂直フロントポーチ、垂直同期パルス幅、垂直バックポーチです。
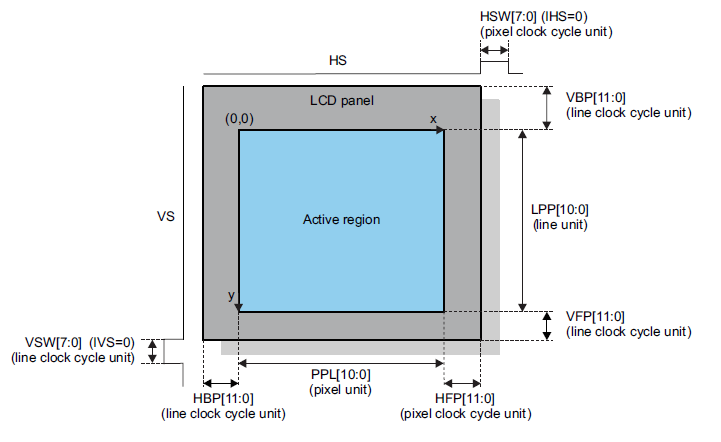
これらは、LCD 以前の、CRT 時代の遺物だと思うのですが、LCD でも設定する必要があります。
設定する値は、画面サイズとリフレッシュレートによって変わります。
それでは、DSS を設定してみましょう。
その前に、いくつかやっておくことがあります。
a) Pad multiplexing 設定
OMAP3530 は、限られた外部ピンを、複数のモジュールで共用するようになっています。
(Pad multiplexing の超概要はこちら。)
DSS のパラレル LCD 出力は、28 本の信号線を使いますが、これらの信号が外部ピンに出るように、構成する必要があります。
u-boot のコードの中に、この設定をしている個所があったので、そのままいただいてきました。
957: MUX_VAL(CP(DSS_PCLK), (IDIS | PTD | DIS | M0))/*DSS_PCLK*/\
958: MUX_VAL(CP(DSS_HSYNC), (IDIS | PTD | DIS | M0)) /*DSS_HSYNC*/\
959: MUX_VAL(CP(DSS_VSYNC), (IDIS | PTD | DIS | M0)) /*DSS_VSYNC*/\
960: MUX_VAL(CP(DSS_ACBIAS), (IDIS | PTD | DIS | M0)) /*DSS_ACBIAS*/\
961: MUX_VAL(CP(DSS_DATA0), (IDIS | PTD | DIS | M0)) /*DSS_DATA0*/\
962: MUX_VAL(CP(DSS_DATA1), (IDIS | PTD | DIS | M0)) /*DSS_DATA1*/\
963: MUX_VAL(CP(DSS_DATA2), (IDIS | PTD | DIS | M0)) /*DSS_DATA2*/\
964: MUX_VAL(CP(DSS_DATA3), (IDIS | PTD | DIS | M0)) /*DSS_DATA3*/\
965: MUX_VAL(CP(DSS_DATA4), (IDIS | PTD | DIS | M0)) /*DSS_DATA4*/\
966: MUX_VAL(CP(DSS_DATA5), (IDIS | PTD | DIS | M0)) /*DSS_DATA5*/\
967: MUX_VAL(CP(DSS_DATA6), (IDIS | PTD | DIS | M0)) /*DSS_DATA6*/\
968: MUX_VAL(CP(DSS_DATA7), (IDIS | PTD | DIS | M0)) /*DSS_DATA7*/\
969: MUX_VAL(CP(DSS_DATA8), (IDIS | PTD | DIS | M0)) /*DSS_DATA8*/\
970: MUX_VAL(CP(DSS_DATA9), (IDIS | PTD | DIS | M0)) /*DSS_DATA9*/\
971: MUX_VAL(CP(DSS_DATA10), (IDIS | PTD | DIS | M0)) /*DSS_DATA10*/\
972: MUX_VAL(CP(DSS_DATA11), (IDIS | PTD | DIS | M0)) /*DSS_DATA11*/\
973: MUX_VAL(CP(DSS_DATA12), (IDIS | PTD | DIS | M0)) /*DSS_DATA12*/\
974: MUX_VAL(CP(DSS_DATA13), (IDIS | PTD | DIS | M0)) /*DSS_DATA13*/\
975: MUX_VAL(CP(DSS_DATA14), (IDIS | PTD | DIS | M0)) /*DSS_DATA14*/\
976: MUX_VAL(CP(DSS_DATA15), (IDIS | PTD | DIS | M0)) /*DSS_DATA15*/\
977: MUX_VAL(CP(DSS_DATA16), (IDIS | PTD | DIS | M0)) /*DSS_DATA16*/\
978: MUX_VAL(CP(DSS_DATA17), (IDIS | PTD | DIS | M0)) /*DSS_DATA17*/\
979: MUX_VAL(CP(DSS_DATA18), (IDIS | PTD | DIS | M0)) /*DSS_DATA18*/\
980: MUX_VAL(CP(DSS_DATA19), (IDIS | PTD | DIS | M0)) /*DSS_DATA19*/\
981: MUX_VAL(CP(DSS_DATA20), (IDIS | PTD | DIS | M0)) /*DSS_DATA20*/\
982: MUX_VAL(CP(DSS_DATA21), (IDIS | PTD | DIS | M0)) /*DSS_DATA21*/\
983: MUX_VAL(CP(DSS_DATA22), (IDIS | PTD | DIS | M0)) /*DSS_DATA22*/\
984: MUX_VAL(CP(DSS_DATA23), (IDIS | PTD | DIS | M0)) /*DSS_DATA23*/\
:
1013: MUX_VAL(CP(HDQ_SIO), (IDIS | PTU | EN | M4)) /*GPIO_170*/\
b) DVI 出力用電源設定 / TFP410 有効化
電源モジュール TPS65950 を操作して、DVI 出力のための電源供給をする必要があり、また、GPIO170 を操作して TFP410 を activate する必要があります。
これらが必要なことは、SRM に書いてありました。
TPS65950 は、I2C1 に繋がっているので、I2C1 にコマンドを流すことによってTPS65950 を制御します。
20: /* TPS65950 settings */
21: data = 0xE0;
22: i2c_write(0x4B, 0x8E, 1, &data, 1);
23: data = 0x05;
24: i2c_write(0x4B, 0x91, 1, &data, 1);
25:
26: data = 0x20;
27: i2c_write(0x4B, 0x96, 1, &data, 1);
28: data = 0x03;
29: i2c_write(0x4B, 0x99, 1, &data, 1);
30:
31: /* activate TFP410 */
32: omap_set_gpio_direction(170, 0);
33: omap_set_gpio_dataout(170, 1);
それでは、とうとう DSS の設定です。
まずは背景画面だけを表示させてみましょう。
設定するレジスタは、以下です。
DSS_CONTROL
DISPC_IRQENABLE
DISPC_CONTROL
DISPC_DEFAULT_COLOR_0
DISPC_TIMING_H
DISPC_TIMING_V
DISPC_DIVISOR
DISPC_SIZE_LCD
110: /* clear GOLCD */
111: sr32(DISPC_CONTROL, 0, 1, 0);
DSS のレジスタのうち、シャドーレジスタと呼ばれるものは、設定した瞬間に設定値が反映されるのではなく、DISPC_CONTROL の GOLCD ビットが立った時に反映されます。
上記のレジスタでは、DISPC_DEFAULT_COLOR_0, DISPC_TIMING_H, DISPC_TIMING_V, DISPC_DIVISOR, DISPC_SIZE_LCD がシャドーレジスタになります。
シャドーレジスタを設定するときには GOLCD ビットをクリアするようにと OMAP35x TRM に書かれているので、ここで落としておきます。
113: /* use DSS1_ALWON_FCLK */
114: __raw_writel(0x0, DSS_CONTROL);
DSS_CONTROL の DISPC_CLK_SWITCH ビットにより、DSS の入力クロックを DSS1_ALWON_FCLK か DSI1_PLL_FCLK か、どちらにするかを選択できますが、DSS1_ALWON_FCLK を選択します。
DSS1_ALWON_FCLK は、DPLL4 からの出力クロックであり、自由に値を設定できます。
この値は、xloader のデフォルトでは 96MHz になっています。
96MHz だとピクセルクロックを自由に作りにくいので、今回は 432MHz にしました(別の箇所で)。
即ち、DSS の入力クロックは 432MHz ということになります。
119: /* disable interrupt */
120: __raw_writel(0x0, DISPC_IRQENABLE);
今回、割り込みは使いません。
なので、すべての割り込みを無効化しておきます。
122: /* set GPOUT1, GPOUT0, TFTDATALINES=24bit, STNTFT , LCDENABLE */
123: __raw_writel(0x18309, DISPC_CONTROL);
DISPC_CONTROL の GPOUT1, GPOUT0 ビットは、パラレル LCD 出力を、RFBI モードで使うか、バイパスモード (RFBI を使わない) で使うかを決定します。
GPOUT1, GPOUT0 の両方が立つと、バイパスモードになります。
今回はバイパスモードで使用するので、両方立てておきます。
また、LCDENABLE ビットも立てておきます。
これを立てないと、パラレル LCD 出力から出力されません。
125: /* set default color GREEN */
126: __raw_writel(0x0000ff00, DISPC_DEFAULT_COLOR(0));
背景色を、緑色にしておきます。
134: /* set H-timing */
135: __raw_writel((hbp << 20) | (hfp << 8) | hsw, DISPC_TIMING_H);
136:
137: /* set V-timing */
138: __raw_writel((vbp << 20) | (vfp << 8) | vsw, DISPC_TIMING_V);
139:
140: /* set LCD, PCD */
141: __raw_writel(0x00010000 | pcd, DISPC_DIVISOR);
142:
143: /* set LPP, PPL */
144: __raw_writel((lpp << 16) | ppl, DISPC_SIZE_LCD);
タイミング設定、ピクセルクロック設定、画面サイズ設定を行います。
これらの値は、どのようなディスプレイモードを選択するかに依存します。
また、サポートされるディスプレイモードは、LCD に依ります。
146: /* set GOLCD */
147: sr32(DISPC_CONTROL, 5, 1, 1);
シャドーレジスタに設定した値を反映させるために、GOLCD ビットを立てます。
正しく設定てきていれば、この操作により、LCD に緑色の背景画面が表示されます。
134 行目から 144 行目までのタイミング設定、ピクセルクロック設定、画面サイズ設定、これらはどのような値を設定すればよいでしょう?
まずは、LCD がどのようなディスプレイモードをサポートしているか、知る必要があります。
LCD によっては、固有の詳細情報を知らせるために、Extended Display Identification Data (EDID) というデータを提供しているものがあります。
EDID は、I2C 経由で読み出すことが出来ます。
それでは自分の LCD はどんなディスプレイモードをサポートしているのかな、と思って EDID を読んでみると、、、
I2C が read error になってしまいました。
どうやら EDID 非対応らしいです。
うーん・・・。
仕方ないので、VESA 標準タイミングのうち、適当そうなのを選んで試してみましょう。
普通の LCD は VESA 標準に従ってるはずだよね、ということで。
VESA 標準タイミングデータシートは、google で "vesa timing" で検索すると、見つけることができます。
VESA タイミングデータシート、非常に分かりやすくて、DSS で設定すべきパラメータがそのまま載っています。
ピクセルクロック値、水平/垂直フロントポーチ、同期パルス幅、バックポーチ、すべて載っています。
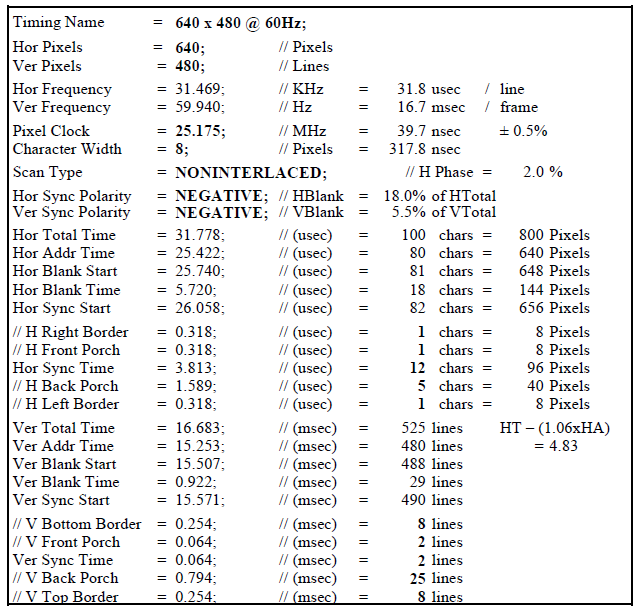
今回試してみたのは、
640 x 480 @ 60Hz
640 x 480 @ 75Hz
800 x 600 @ 60Hz
1024 x 768 @ 60Hz
1280 x 1024 @ 60Hz
です。
ピクセルクロック値は、VESA 標準で指定されている値を正確に作ることができません。
たとえば、640 x 480 @ 75Hz のピクセルクロックは 31.5MHz なのですが、DSS の入力クロック 432MHz から、この値を作ることはできません。
(ピクセルクロックは、432MHz を任意の整数で割った値を指定します。)
DSS の入力クロックを変更してやれば、正確に 31.5MHz を作れると思いますが、ちょっと手抜き。
より近い値として、432MHz を 14 で割った 30.86MHz で代用します。
この場合、画面リフレッシュレートは、73.47Hz になります。
このくらいの差だったら、まあ大丈夫でしょう、きっと。
正しく映ると、こんな感じです↓

各モードの表示結果は、こんな↓です。
| ディスプレイモード | リフレッシュレートの実際の値 | 表示結果 |
| 640 x 480 @ 60Hz | 60.14Hz | OK |
| 640 x 480 @ 75Hz | 73.47Hz | OK |
| 800 x 600 @ 60Hz | 59.22Hz | OK |
| 1024 x 768 @ 60Hz | 66.47Hz | OK |
| 1280 x 1024 @ 60Hz | 60.02Hz | OK |
1024 x 768 @ 60Hz モードでは、実際のリフレッシュレートは 60Hz からかなり外れていますが、いけるもんですね。
モノによりけりかもしれませんが。
自分のは大丈夫でした。
上の表には出ていませんが、1280 x 1024 @ 60Hz モードでは、ピクセルクロックは 108MHz にしています。
OMAP35x TRM を見ると、"Programmable pixel rate up to 75MHz" という記述があって、108MHz は上限オーバーじゃないのかと思いますが、一応、ちゃんと動いていますね。
あまりよろしくないのかもしれませんが。
ちょっと先取りしてしまいますが、640 x 480, 800 x 600, 1024 x 768, 1280 x 1024 の画面に 640 x 480 サイズの Video1 画像を表示させると、こんな風になります。


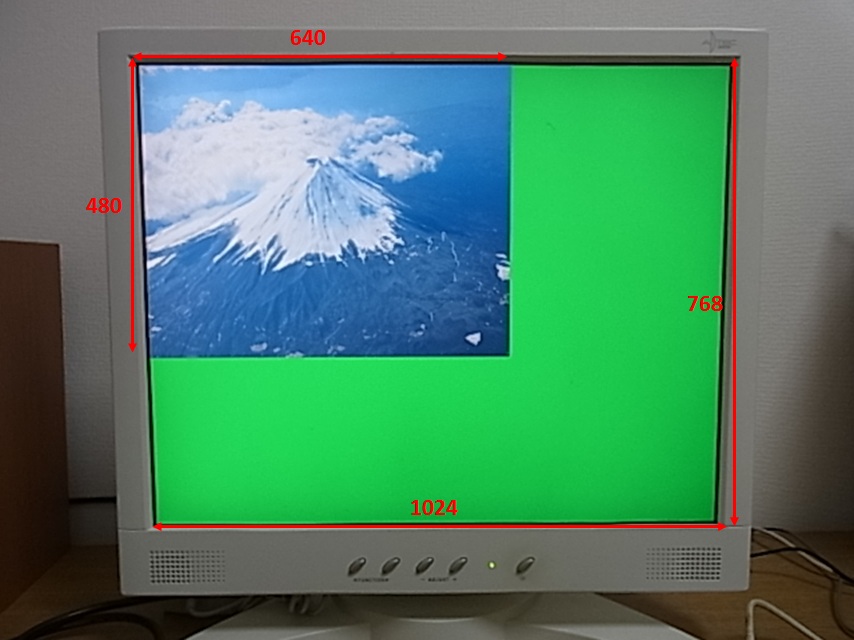

自分の LCD は、確かドット数が 1280 x 1024 だと思うので、1280 x 1024 設定以外では、DSS から送っているピクセル数と、実際のドット数が一致していません。
LCD 側で、適当に拡大して表示してくれているんですね。
・・・
背景画面が表示できたので、次はその上に Video1/Video2, Graphics 画面を表示させてみましょう。
Video1/Video2 の設定方法と、Graphics の設定方法は、ほぼ同じです。
ここでは、Video1/Video2 画面を表示するための設定方法を見てみましょう。
設定するレジスタは、以下です。
DISPC_VIDn_BA0
DISPC_VIDn_POSITION
DISPC_VIDn_SIZE
DISPC_VIDn_PICTURE_SIZE
DISPC_VIDn_FIFO_THRESHOLD
DISPC_VIDn_FIFO_SIZE_STATUS
DISPC_VIDn_ROW_INC
DISPC_VIDn_PIXEL_INC
DISPC_VIDn_ATTRIBUTES
※n は、Video1 の場合は 1, Video2 の場合は 2
159: /* clear GOLCD */
160: sr32(DISPC_CONTROL, 5, 1, 0);
設定するレジスタは、すべてシャドーレジスタなので、背景画面設定時と同じく、GOLCD ビットは落としておきます。
162: /* base address */
163: __raw_writel(ba, DISPC_VID_BA(n, 0));
Video1/Video2 の画像データを格納するアドレスを、DISPC_VIDn_BA0 に指定します。
指定するアドレスは、SRAM でも SDRAM でも大丈夫です。
DSS 内にある DMA engine は、指定されたアドレスから、画像データを DSS に継続的に転送します。
165: /* position */
166: __raw_writel((posy << 16) | posx, DISPC_VID_POSITION(n));
Video1/Video2 画面の開始座標を指定します。
一番左上が (0, 0) です。
背景画面の大きさが 1024 x 768 だとすると、一番右下は (1023, 767) です。
168: /* size */
169: __raw_writel(((sizey-1) << 16) | (sizex-1), DISPC_VID_SIZE(n));
170:
171: /* picture size */
172: __raw_writel(((orgsizey-1) << 16) | (orgsizex-1), DISPC_VID_PICTURE_SIZE(n));
表示サイズ、元画像のサイズを指定します。
Video1/Video2 は、元画像を拡大・縮小して表示する機能を持っています。
今回は、等倍で表示させるので、同じ値を設定しておきます。
(sizey == orgsizey, sizex == orgsizex)
174: /* FIFO threshold */
175: __raw_writel(0x03ff03c0, DISPC_VID_FIFO_THRESHOLD(n));
DMA engine の送り先である FIFO に関する設定です。
FIFO は、Video1, Video2 それぞれに対して存在します。
上限閾値と下限閾値を指定できて、FIFO の中身が下限閾値以下になったら DMA が開始され、上限閾値以下になったら停止します。
上の例は、上限閾値 0x3ff = 1023, 下限閾値 0x3c0 = 960 を指定しています。
OMAP35x TRM には、パフォーマンス最適化のために、上限閾値は FIFO サイズ - 1 を、下限閾値は、バースト長が 16x32bit の場合は、960 にするようにと書いてあります。
(FIFO サイズは、1024 です。)
バースト長は、この後で 16x32bit を設定します。
177: /* row inc */
178: __raw_writel(0x01, DISPC_VID_ROW_INC(n));
179:
180: /* pixel inc */
181: __raw_writel(0x01, DISPC_VID_PIXEL_INC(n));
画像領域から DMA 転送する際、今回の転送から次のデータ転送に移る時に、アドレスをどれくらい進めるかを指定します。
画像データが連続的に格納されている場合は、上記のように 1 を指定すれば OK です。
183: /* attributes */
184: __raw_writel((format << 1) | 0x8001, DISPC_VID_ATTRIBUTES(n));
DMA バースト長を 16x32bit に設定し、VIDENABLE ビットを立てます。
VIDENABLE ビットを立てることにより、Video1/Video2 画面が有効になります。
同時に、画像データのデータフォーマットを指定します。
RGB12 とか RGB24 とか ARGB とか、いろいろ選べます。
画像領域には、ここに指定したフォーマットで画像データを格納しておく必要があります。
186: /* set GOLCD */
187: sr32(DISPC_CONTROL, 5, 1, 1);
最後に、シャドーレジスタに設定した値を反映させるために、GOLCD ビットを立てます。
正しく設定てきていれば、この操作により、Video1/Video2 画面が表示されます。
Graphics 画面の設定は、Video1/Video2 画面の設定とほぼ同じなので、省略です。
後は、画像領域に正しく画像データを格納する必要がありますね。
やっぱり、好きな画像を表示させたいですよね。
以下は、任意の画像を表示させる方法です。
1. 適当な画像を用意する (フォーマットは、とりあえず何でも OK)
2. GIMP を使って、画像を表示させたい大きさに変更する
3. RAW 画像形式でファイルを保存する
4. RAW 画像形式は RGB 形式であるが、これを BGR 形式に変換する
5. 変換した画像データを SD カードにコピーしておく
6. xloader をブートさせ、画像データを SD カードから SDRAM 上の適当なアドレスに読み出す
7. 画像データを格納したアドレスを Base Address に、画像フォーマットを RGB24 (packed in 24-bit container) にするように Video1 (もしくは Video2, Graphics) 画面を設定する
こんな感じでいけますが、少々注釈です。
2 に関して
GIMP を使っていますが、画像データを RAW 画像形式で保存したいためです。
GIMP 以外でも、RAW 画像形式で保存できるものであれば OK です。
RAW 画像形式で保存したいのは、普通の画像フォーマットだと、ヘッダーとかが付加されてしまうからです。
欲しいのは、画像データのみのバイト列ですので。
3 に関して
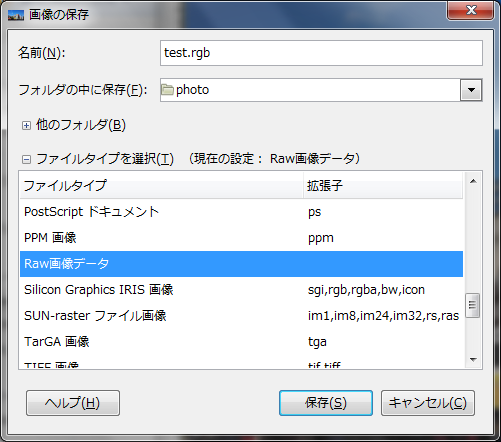
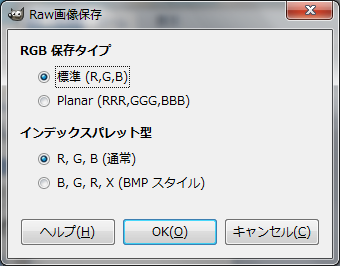
GIMP で、RAW 画像形式で保存するには、↓のように、"Raw画像データ" で保存します。
その後、↓のようなウィンドウが出てきますが、そのまま "OK" 押下です。
4 に関して
GIMP の RAW 画像形式は、RGB の順にデータが格納されます。
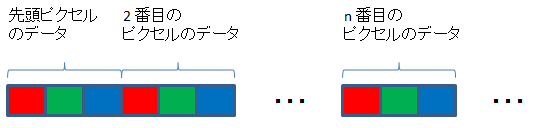
DSS がサポートしている RGB24 形式は、RGB 順ではなく、BGR 順です。

なので、GIMP の RAW 画像形式は、そのままでは使えません。
各ピクセルにおいて、R と B を交換する必要があります。
簡単なプログラムを書いて、RAW 画像データの R と B を入れ替えてやれば、それで OK です。
BGR 形式で保存出来るツールがあれば、ほんとはそれが一番よいのですが。
以上、注釈終わりです。
この方法を使って、Video1, Video2, Graphics 画面すべてを表示させてみました。
1280 x 1024 の背景画面に、それぞれ 640 x 512 の画像を表示させています。

せっかくなので、ちょっと重ねてみましょう。
表示優先度は、Video2 > Video1 > Graphics > 背景画面 でしたね。
ちゃんとその通りになっています↓

・・・
DSS を使って、外部 LCD に表示させてみました。
やっぱりヴィジュアルものは、動かしていて楽しいですね。
今までの UART だとかタイマーだとか、意図通り動いても、あ、動いた、くらいの感覚でしたが、LCD 表示が正しく動いた場合は、おおお、映ったあ!!となります (^-^)
beagleboard を触ろう - FAT ファイルシステム [組み込みソフト]
beagleboard を SD ブートさせる場合、Boot ROM コードは x-loader (MLO) を読み出し、x-loader は u-boot (u-boot.bin) を読み出し、u-boot は Linux カーネル (uImage) を読み出し、という具合に進んでいきます。
Boot ROM コード、x-loader, u-boot それぞれは、FAT ファイルシステムからファイルを読み出す能力を持っています。
x-loader の場合、FAT12/FAT16/FAT32 からファイルを読み出すことができます。
しかし、書き込みコードは実装されていません。
angstrom ブートの回で作った(そしてその後も使い続けている)ブート SD は、FAT32 でフォーマットされています。
ここでは、FAT32 の読み出しについて見ていきます。
その前に、まず、ファイルシステムを格納する SD カードについて少々。
beagleboard では、SD カードに対しては、MMC/SD/SDIO ホストコントローラ (以下 MMC/SD コントローラ) 経由でアクセスします。
MMC/SD コントローラと SD カードは、clk, cmd, data 信号を用いてやり取りを行います。
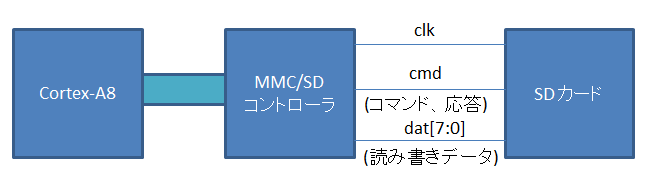
MMC/SD コントローラが cmd 信号上にコマンドを流し、SD カードはコマンドを受け、レスポンスを同じく cmd 信号上に返し、その後 data 信号上でデータを受け渡します。
コマンドには、ブロックリード、ブロックライト、消去等のコマンドが用意されています。
基本的に、SD カードに対しては、ブロック単位の操作しかできません。
ブロックの大きさは、CMD16 (SET BLOCKLEN) コマンドを発行することにより、変更可能です(通常は 512 バイト)。
書き込みを行う際は、NAND フラッシュのように、消去してからプログラムしなければいけないという制約はありません(多分)。
内部的には、消去→プログラムを行っているのかもしれませんが、MMC/SD コントローラからは、消去しないでいきなり書き込めるようなインターフェースになっています。
SD カードを使うためには、いろいろ初期設定をしなければいけないのですが、、、
手順をあまり理解しておらず、、、
OMAP35x TRM に書いてある初期化手順と、xloader の初期化コードは手順があまり一致しないし、、、
ということで、省略です!
初期設定が完了した後は、コマンドを発行するだけで簡単にアクセスすることができます。
x-loader では、ファイルを読み出す際に、CMD17 (READ SINGLE BLOCK) を発行して、1 ブロック(512 バイト)を読み出しています。
・・・
SD カードの先頭セクタ(先頭ブロック)は、MBR (Master Boot Record) と呼ばれる領域です。
MBR にはパーティションテーブルが置かれています。
パーティションテーブルは、4 つのパーティション情報から成っています。
パーティションテーブルを読むことにより、パーティション 1 は FAT32 で、パーティションの先頭セクタは 63、などということが分かります。

各テーブルは、以下のようなフォーマットになっています。
| オフセット | 意味 | サイズ |
| 0x00 | フラグ | 1 |
| 0x01 | パーティションの先頭セクタ (CHS) | 3 |
| 0x04 | パーティションの種類 | 1 |
| 0x05 | パーティションの最後のセクタ (CHS) | 3 |
| 0x08 | パーティションの先頭セクタ (LBA) | 4 |
| 0x0c | パーティションの全セクタ数 | 4 |
セクタ 0 を実際に読み出してみると、以下のようになります。
セクタ 0 (MBR):

オフセット 0x1be からがパーティション 1、オフセット 0x1ce からがパーティション 2 です。
これを解釈すると、
パーティション 1:
| フラグ | ブート可能 |
| パーティションの種類 | FAT32 |
| パーティションの先頭セクタ (LBA) | 63 |
| パーティションの全セクタ数 | 144522 |
パーティション 2:
| フラグ | ブート不可 |
| パーティションの種類 | ext3 |
| パーティションの先頭セクタ (LBA) | 144585 |
| パーティションの全セクタ数 | 3598560 |
となります。
パーティション 1 の先頭セクタ (LBA) は 63 となっていますが、この値は、パーティション 1 が FAT ファイルシステムならば、固定値なのかもしれません。
xloader の FAT コードでは、63 という数字がハードコードされていますので。
FAT パーティションの大まかな構造を見てみましょう。
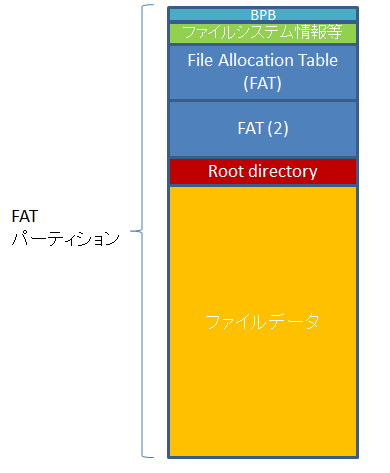
File Allocation Table (FAT) という、物理デバイス内のブロック(クラスタ)の使用状況を表したテーブルがあり、その後にルートディレクトリ情報があり、その後にファイルデータが並ぶ、というような構成になっています。
FAT は、同じものが 2 つ連続して配置されています。
物理デバイスに保持されるファイルの最小単位は、クラスタと呼ばれます。
1 クラスタは、連続する数セクタ (1 セクタでもよい) から構成されます。
1 バイトのファイルをつくったとしても、実際に物理デバイス上に確保される領域は、1 クラスタ分になります。
1 クラスタが何セクタから構成されるかは、ファイルシステムの都合により決めることができます。
FAT は、クラスタの使用状況を表すテーブルであり、FAT32 ならば 1 エントリが 32 ビット長になっていて、次のような順でエントリが並んでいます。
クラスタ 0 の使用状況を表すエントリ
クラスタ 1 の使用状況を表すエントリ
:
最終クラスタの使用状況を表すエントリ
各エントリに書かれる値は、次のような意味になります。
| 0x0000_0000 | 未使用クラスタ |
| 0x0000_0001 | 予約 |
| 0x0000_0002 - 0x0fff_fff6 | 使用中のクラスタ(後続クラスタあり) |
| 0x0fff_fff7 | 不良クラスタ |
| 0x0fff_fff8 - 0x0fff_ffff | 使用中のクラスタ(後続クラスタなし) |
ファイルが 1 クラスタに収まらず、数クラスタに及ぶ場合、0x0000_0002 - 0x0fff_fff6 のエントリを使ってリンクを構成します。
ファイルの最終クラスタであることを示すのが、0x0fff_fff8 - 0x0fff_ffff のエントリです。
ファイルは、クラスタ番号によって管理されます。
ファイルシステムの中にはディレクトリエントリというデータ構造があって、基本的に 1 つのファイルに対して 1 つのディレクトリエントリが存在します。
ディレクトリエントリという名前からは、ディレクトリのみを表すものかと連想してしまいますが、ディレクトリ、ファイル、両方を記述するデータ構造です。
FAT ファイルシステムのディレクトリエントリは、以下のような構造体によって表されます。
typedef struct dir_entry {
char name[8],ext[3]; /* Name and extension */
__u8 attr; /* Attribute bits */
__u8 lcase; /* Case for base and extension */
__u8 ctime_ms; /* Creation time, milliseconds */
__u16 ctime; /* Creation time */
__u16 cdate; /* Creation date */
__u16 adate; /* Last access date */
__u16 starthi; /* High 16 bits of cluster in FAT32 */
__u16 time,date,start; /* Time, date and first cluster */
__u32 size; /* File size in bytes */
} dir_entry;
ディレクトリエントリには、ファイル名とともに、先頭クラスタ番号が記述されています。
(上の構造体では __u16 starthi & __u16 start)
つまり、ファイル名を元に該当するディレクトリエントリを探し出せば、ファイルの位置が分かるという寸法になっています。
しかし、ディレクトリエントリには、ファイルが複数セクタから成る場合、次のクラスタはどこか、という情報が書かれていません。
その情報は、FAT に書かれています。
例えば、ファイルの先頭クラスタがクラスタ 4 であったとします。
クラスタ 4 には、ファイル先頭から 1 クラスタ分のファイルコンテンツが含まれています。
その続きがどこにあるかは、FAT エントリ 4 を見れば分かります。
FAT エントリ 4 に書かれている値が、0x0000_0007 だとすると、ファイルの続きはクラスタ 7 に含まれているということになります。
ファイルは、クラスタ 4 とクラスタ 7 に収まるとしましょう。
そうすると、クラスタ 7 には、0x0fff_fff8 - 0x0fff_ffff のいずれかが書かれているということになります。
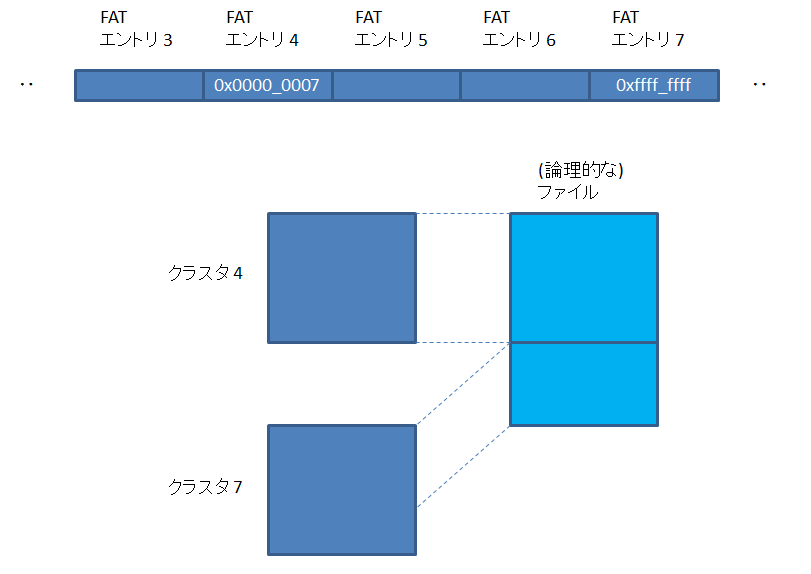
パス名からファイルを取得する手順は、以下のようになります。
例として、/beagle/board/hoge というファイルを探す手順を見てみます。
1. ルートディレクトリから、beagle という名前に合致するディレクトリエントリを探す
→ 見つかったディレクトリエントリの attribute は、ディレクトリを表す 0x10 になっている
2. そのディレクトリエントリから、クラスタ番号 xx を取得する
→ クラスタ xx は、/beagle ディレクトリに存在するディレクトリおよびファイルを表すディレクトリエントリを保持している
3. クラスタ xx を読み出して、board という名前に合致するディレクトリエントリを探す
→ 見つかったディレクトリエントリの attribute は、ディレクトリを表す 0x10 になっている
4. そのディレクトリエントリから、クラスタ番号 yy を取得する
→ クラスタ yy は、/board/board ディレクトリに存在するディレクトリおよびファイルを表すディレクトリエントリを保持している
5. クラスタ yy を読み出して、hoge という名前に合致するディレクトリエントリを探す
→ 見つかったディレクトリエントリの attribute は、ファイルを表す 0x20 になっている
6. そのディレクトリエントリから、クラスタ番号 zz を取得する
→ hoge ファイルの先頭クラスタは zz
7. クラスタ zz を読み出してファイルコンテンツを取得する
8. 続きがある場合は、FAT エントリ zz を見て、次のクラスタ番号を取得する
9. 以下、同じ
ちょっと省略してしまいましたが、1, 3, 5 でディレクトリエントリを走査して探すとき、先頭クラスタ内からは見つからない場合は、次のクラスタを読み出す必要があります。
その場合も、FAT エントリを見て後続のクラスタを探す手順は、8. と同じです。
ファイルを書き込む場合は、/beagle/board/foo というファイルを書き込むとすると、
1. 上記 1 - 4 と同じ手順で /beagle/board ディレクトリのクラスタ番号 yy を取得する
2. クラスタ yy を読み出して、空きディレクトリエントリを探し、確保する
3. FAT を走査して、空きクラスタから、必要な分だけクラスタを確保する (FAT エントリの変更)
4. 確保したディレクトリエントリに foo という名前や、ファイル先頭クラスタ番号を含め、設定を行う
5. 変更した FAT エントリを、対応する物理セクタに書き込む
6. 変更したディレクトリエントリを、対応する物理セクタに書き込む
7. ファイルコンテンツを、確保したクラスタに対応する物理セクタに書き込む
のような手順を踏めば OK です。
(・・・のハズです。試してないですケド。)
SD カードの場合、CMD24 (WRITE SINGLE BLOCK) や CMD25 (WRITE MULTIPLE BLOCK) を発行することにより、書き込みを行うことができます。
・・・
それでは、実際の FAT パーティションを見てみましょう。
FAT パーティションの先頭セクタ (セクタ 63) は、BPB (BIOS Parameter Blobk) と呼ばれる領域で、パーティション内の構造が記述されています。
FAT32 の場合、以下のようなフォーマットです。
| オフセット | 意味 | サイズ |
| 0x00 | ブートストラップコード | 3 |
| 0x03 | ラベル名 | 8 |
| 0x0b | 1 セクタあたりのバイト数 | 2 |
| 0x0d | 1 クラスタあたりのセクタ数 | 1 |
| 0x0e | 予約セクタ数 (メイン FAT の開始セクタ番号) | 2 |
| 0x10 | FAT の数 | 1 |
| 0x11 | ルートディレクトリエントリ数 (FAT32 では 0) | 2 |
| 0x13 | 全セクタ数 (FAT32 では 0) | 2 |
| 0x15 | メディアコード | 1 |
| 0x16 | FAT のセクタ数 | 2 |
| 0x18 | 1 トラックあたりのセクタ数 | 2 |
| 0x1a | ドライブのヘッド数 | 2 |
| 0x1c | 不可視セクタ数 | 4 |
| 0x20 | 全セクタ数 | 4 |
| 0x24 | FAT 1 つあたりのセクタ数 | 4 |
| 0x28 | フラグ | 2 |
| 0x2a | ファイルシステムバージョン | 2 |
| 0x2c | ルートディレクトリの開始クラスタ番号 | 4 |
| 0x30 | ファイルシステム情報のセクタ番号 | 2 |
| 0x32 | バックアップセクタ番号 | 2 |
| 0x34 | 予約 | 12 |
| 0x40 | 物理ドライブ番号 | 1 |
| 0x41 | 予約 | 1 |
| 0x42 | ブートシグネチャ | 1 |
| 0x43 | ボリュームシリアル ID | 4 |
| 0x47 | ボリュームラベル | 11 |
| 0x52 | ファイルシステムタイプ | 8 |
セクタ 63 を読みだしてみると、以下のようになります:
セクタ 63 (FAT BPB):
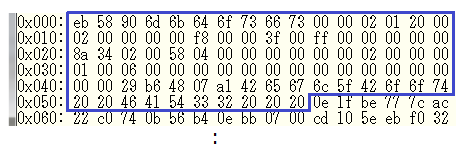
これを解釈すると、
| ブートストラップコード | x86 の jmp 命令 |
| ラベル名 | mkdosfs |
| 1 セクタあたりのバイト数 | 512 |
| 1 クラスタあたりのセクタ数 | 1 |
| 予約セクタ数 (メイン FAT の開始セクタ番号) | 32 |
| FAT の数 | 2 |
| ルートディレクトリエントリ数 (FAT32 では 0) | 0 |
| 全セクタ数 (FAT32 では 0) | 0 |
| メディアコード | 固定ディスク |
| FAT のセクタ数 (FAT32 では 0) | 0 |
| 1 トラックあたりのセクタ数 | 63 |
| ドライブのヘッド数 | 255 |
| 不可視セクタ数 | 0 |
| 全セクタ数 | 144522 |
| FAT 1 つあたりのセクタ数 | 1112 |
| フラグ | 0 |
| ファイルシステムバージョン | 0 |
| ルートディレクトリの開始クラスタ番号 | 2 |
| ファイルシステム情報のセクタ番号 | 1 |
| バックアップセクタ番号 | 6 |
| 予約 | 0 |
| 物理ドライブ番号 | 0 |
| 予約 | 0 |
| ブートシグネチャ | 0x29 |
| ボリュームシリアル ID | 0xa107_48b6 |
| ボリュームラベル | Begl_Boot |
| ファイルシステムタイプ | FAT32 |
となります。
1 クラスタあたりのセクタ数 = 1 なので、1 クラスタ = 1 セクタですね。
1 セクタあたりのバイト数 = 512 なので、1 クラスタも 512 バイトになります。
予約セクタ数 = 32 は、FAT パーティションにおける FAT のオフセットを表します。
FAT パーティションは物理セクタ 63 から始まるので、FAT の先頭は物理セクタ 63 + 32 = 95 ということになります。
そこから FAT が 1112 セクタ x 2 個続き、その後にルートディレクトリが配置されます。
というわけで、ルートディレクトリの先頭セクタは、95 + 1112 x 2 = 2319 となります。
ルートディレクトリの開始クラスタ番号は 2 になっていますね。
これは、ルートディレクトリが格納されている、物理セクタ 2319 から始まるクラスタを、クラスタ番号 2 として番号付けしなさい、という意味です。
今、クラスタサイズとセクタサイズは等しいので、物理セクタ 2319 がクラスタ 2、物理セクタ 2320 がクラスタ 3, 物理セクタ 2317 + n がクラスタ n になります。
ルートディレクトリを見てみましょう。
物理セクタ 2319 です。
セクタ 2319 (ルートディレクトリ):

ディレクトリエントリのフォーマットは、先ほどにも出しましたが、↓のようになっています。
typedef struct dir_entry {
char name[8],ext[3]; /* Name and extension */
__u8 attr; /* Attribute bits */
__u8 lcase; /* Case for base and extension */
__u8 ctime_ms; /* Creation time, milliseconds */
__u16 ctime; /* Creation time */
__u16 cdate; /* Creation date */
__u16 adate; /* Last access date */
__u16 starthi; /* High 16 bits of cluster in FAT32 */
__u16 time,date,start; /* Time, date and first cluster */
__u32 size; /* File size in bytes */
} dir_entry;
1 エントリの大きさは 32 バイトなので、上のダンプの 2 行分が 1 エントリになっています。
ルートディレクトリの中から、MLO ファイルを探してみましょう。
M (0x4d) L (0x4c), O (0x4f) という名前を探すと、オフセット 0x1a0 のエントリが合致します。
| ファイル名 | MLO |
| 拡張子 | なし |
| attribute | 0x20 |
| 作成日時 | 2011/10/19 1:55:41 |
| アクセス日時 | 2011/11/25 |
| 更新日時 | 2011/11/25 23:04:46 |
| 先頭クラスタ番号 | 6323 |
| ファイルサイズ | 36264 |
となります。
ファイルサイズ は 36264 バイトであり、1 クラスタは 512 バイトなので、クラスタ 71 個分に MLO 本体は格納されていることになります。
ファイル先頭クラスタ番号 = 6323 ですが、これは FAT パーティション内のオフセットであり、物理セクタ何番かというと、
・ルートディレクトリのクラスタ番号は 2
・ルートディレクトリの物理セクタは 2319
・クラスタ番号 n は物理セクタ 2317 + n
ということを思い出すと、8640 ということが分かります。
ということで、セクタ 8640 の先頭部分を見てみると、
セクタ 8640 (MLO 先頭):

MLO のファイル先頭は、4 バイト長のファイルサイズと 4 バイト長のロードアドレスなのでした。
(x-loader ビルドの回)
ファイルサイズ 0x0000_8da0 = 36256
ロードアドレス 0x4020_0800
MLO のサイズは 36264 バイトですが、MLO の先頭に書かれているファイルサイズはヘッダー部分 8 バイトの大きさを差し引いた値なので、合っています。
ロードアドレスは、x-loader がロードされるアドレスであり、0x4020_0800 は正しい値です。
その後は、0xea00_0012 (= b 0x58), 0xe59f_f014 (= ldr pc,[pc, #20]) と、マシン語命令が続いていきます。
クラスタ 6323 に続くクラスタを探してみましょう。
クラスタ 6323 に対応する FAT エントリは、
・FAT の先頭クラスタは物理セクタ 95
・1 クラスタあたりの FAT エントリ数は 128
であることを考慮すると、物理セクタ 144 の、51 番目 (0 ベース) のエントリー (オフセット 204 = 0xcc) であることが分かります。
セクタ 144 (FAT):

オフセット 0x0c0 の行にある、一番右端の 0x0000_18b4 が、クラスタ 6323 に対応するエントリーですね。
0x0000_18b4 = 6324 です。
あれ、6323 の次ということですね。
6324 のエントリーを見てみると、0x0000_18b5 = 6325 であり、これまた次を指すエントリーです。
よく見てみると、この後ずーっと次を指すエントリーが続いています。
最後は、オフセット 0x1e4 の 0xffff_ffff です。
0xffff_ffff は、もう続きがないということを表すエントリーでした。
つまり、ファイル終端です。
オフセット 0xcc - 0x1e4 までの連続しているエントリーが、MLO のためのエントリーです。
クラスタ 6323 から 6393 までが、連続して MLO に占められているということになります。
物理セクタで言えば、8640 から 8710 までです。
FAT エントリー数(= クラスタ数 = セクタ数)を数えてみると、71 個です。
先ほど、ファイルサイズから、MLO は 71 個のクラスタに収められていると言いましたが、それと合致していますね。
これで、MLO の格納場所がすべて分かりました。
後は、SD カードに対して CMD17 (READ SINGLE BLOCK) を発行すれば、ファイルコンテンツを取得することができます。
・・・
今回は FAT32 について見てきましたが、基本的な構造は FAT12/FAT16 も同じです。
ただ、BPB を解釈する方法とか、FAT32 とちょっとだけ違いますが。
xloader の FAT コードは、今まで見てきたデータ構造を同じようにたどって、u-boot.bin を読み出します。
今回、思わず MLO を追ってしまいましたが、u-boot.bin を追った方が気分的に良かった気がしてきました。
まあ、気分の問題ですし、結果も同じようなものになるはずなので、どうでもいいのですけど (^^;
beagleboard を触ろう - NAND ECC [組み込みソフト]
NAND フラッシュメモリは、ビット化けが起こり得るデバイスであり、ECC (Error Correction Code / Error Checking and Correction) を使って補っています。
ECC は、ユーザーデータに ECC データを付加することによって、誤り訂正を行えるようにした仕組みです。
ECC は、1 ビットの誤りならば、訂正が可能です。
2 ビットの誤りならば、訂正はできませんが、誤りが発生したことは検出できます。
3 ビット以上の誤りがあれば、結果はまちまちです。
間違った判断に基づき、誤り訂正したり、誤りがなかったと判断したりするかもしれません。
ECC データは、ユーザーデータ 2^N ビットに対し、2*N ビット必要です。
例えば、ユーザーデータが 8 ビットならば、N = 3 なので、ECC データは 6 ビット必要です。
ユーザーデータが 2048 ビットならば N = 11 なので、ECC データは 22 ビット必要です。
8 ビットと 2048 ビットを比較すると、ECC データの割合が、2048 ビットの方が少ないため、効率的に思えてしまいますが、その分誤り訂正能力が落ちます。
[ユーザーデータ、ECC データ] = [8 ビット、6 ビット] の場合は、8 ビット中 1 ビットの誤りがあった場合に、訂正できます。
[ユーザーデータ、ECC データ] = [2048 ビット、22 ビット] の場合は、2048 ビット中 1 ビットの誤りしか訂正できません。
beagleboard 搭載の NAND フラッシュメモリ MT29F2G16ABDHC-ET は、1 ページのサイズは 2112 バイトです。
この 1 ページを、ユーザーデータとして 2048 バイトを使い、残りを ECC データ(最大 64 バイト)として使います。
xloader の ECC コードは、2048 バイトを 8 分割して 256 バイトずつのデータとして、それぞれに対して ECC データを付加する方法を取っています。
256 バイト = 2048 ビットなので、ECC データのサイズは 22 ビット です。
22 ビットが収まるように、3 バイトを 1 つの ECC データとして割り当てています。
ECC データは 8 個分あるので、合計サイズは 24 バイトですね。
イメージ的に図示すると、こんな感じです↓
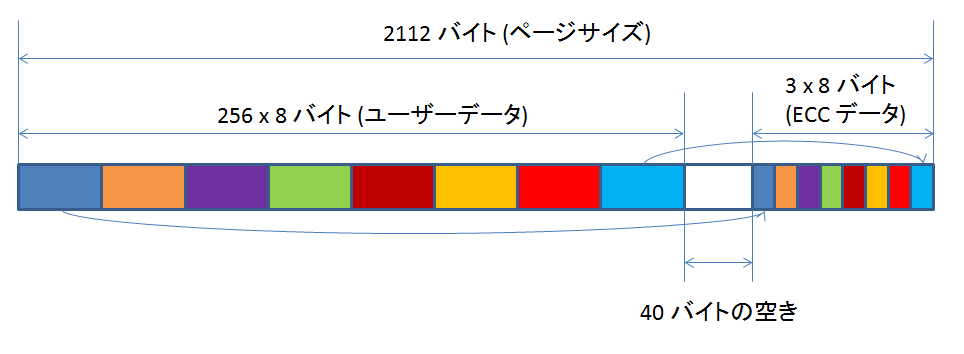
ECC データを格納できる領域は 64 バイトあるので、もう少し精度の高い ECC データを格納することも可能です。
128 バイトごとに ECC を付加するとすれば、必要な ECC の個数は 16 個、1 つあたりの ECC サイズは 20 ビット、これを 3 バイトに収めるとして、3 x 16 = 48 バイトで、64 バイトに収まりますね。
NAND ECC は、256 バイト単位というのがスタンダードなのかどうか、すみません、よく分かっていません。
ウェブで見つけたサムスンの NAND ECC の説明資料も、256 バイト単位になっていました。
ECC データ生成方法のベースになっているのは、パリティです。
偶数パリティであれ、奇数パリティであれ、1 ビット誤りがあった場合、誤りがあったことは分かっても、どのビットで誤りがあったかは分かりませんよね。
ECC は、パリティを巧みに組み合わせて、どこに誤りがあるかを分かるようにした、非常に賢いアルゴリズムを使っています。
NAND ECC は、奇数パリティをベースにしています。
奇数パリティだと、ユーザーデータがオール 0xff の場合、ECC データもオール 0xff になります。
これ、ブロック消去によりデータが 0xff になったときのことを考えると、都合がいいですよね。
偶数パリティなら、消去した後に ECC データ領域を 0x00 で上書きしないといけないですから。
それでは、ECC の生成方法と誤り訂正方法の説明です。
(NAND ECC と同じく、奇数パリティを使用します。)
簡単のため、8 ビットデータに対して、6 ビットの ECC データを生成する場合を見てみます。
以下の図のように、6 ビットの ECC データの各ビットは、8 ビットデータのうち 4 ビットを使って、奇数パリティを生成します。
上図のように 8 ビットデータが 0b00100010 だとすると、ECC データは 0b001111 となります。
奇数パリティの計算は、以下のように、XOR と NOT のみで出来ます。
Pi = ~(bw ^ bx ^ by ^ bz)
※例えば、P1 = ~(b7 ^ b5 ^ b3 ^ b1)
b7 - b0 から影響を受ける ECC ビットは、以下の表のようになります。
影響を受けるというのは、そのビットを元にして ECC が計算されている、という意味に取ってください。
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
| P4` | P4` | P4` | P4` | ||||
| P2` | P2` | P2` | P2` | ||||
| P1` | P1` | P1` | P1` | ||||
| P4 | P4 | P4 | P4 | ||||
| P2 | P2 | P2 | P2 | ||||
| P1 | P1 | P1 | P1 |
各列、1, 2, 4 が 1 つずつ揃っていますね。
(Pi と Pi` は違うビットからパリティを生成するので当たり前なのですが。)
よくよく見ると、
a. 影響を受ける P のビット番号の合計 = データのビット番号
b. 影響を受ける P` のビット番号の合計 = データのビット番号の反転
という関係があります。
例えば、b5 を例にとってみると、
a-左辺 影響を受ける P のビット番号の合計 = 5
a-右辺 データのビット番号 = 5
b-左辺 影響を受ける P` のビット番号の合計 = 2
b-右辺 データのビット番号の反転 = ~5 = ~0b101 = 0b010 = 2
となっています。
8 ビットデータの ECC データの生成は、こんな感じで P4, P4`, P2, P2`, P1, P1` から生成します。
ユーザーデータ数が大きくなったら、それに合わせて P/P` が増えていきます。
16 ビットデータならば、P8/P8` を、32 ビットデータならば P8/P8` と P16/P16` を追加すればいいわけですね。
32 ビットデータの場合、Pi/Pi` は、以下のビットを使って計算します。
P1/P1`, P2/P2`, P4/P4' に適用されているルールと、P8/P8`, P16/P16` に適用されているルールが異なるように見えませんか?
P4/P4` までは P が一番左にあるのに、P8/P8` 以降は P` が一番左にあります。
これは、配列インデックスは左側が 0 なのに、ビット番号は右側が 0 になっていて、逆順になっているので、そう見えるだけです。
ビット番号を左側が 0 になるように書き換えると、自然に見えます。
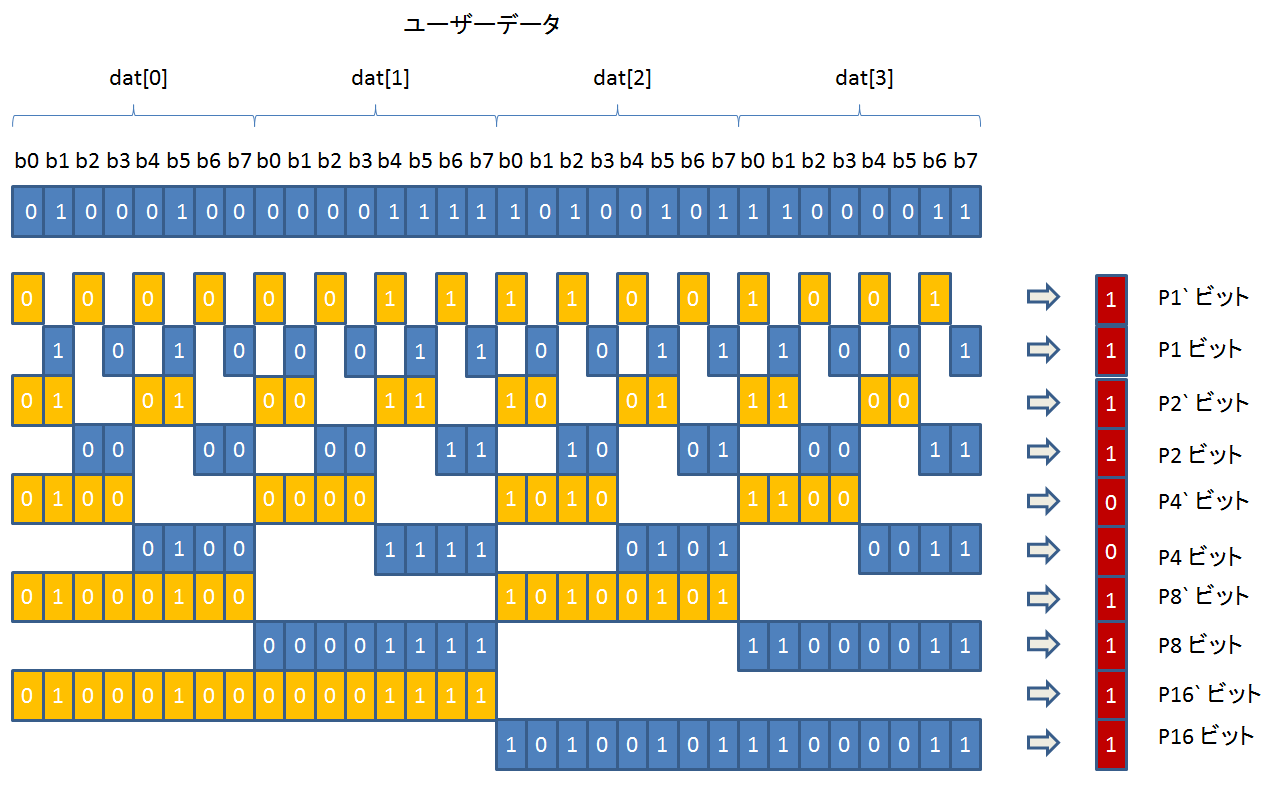
さて、それでは ECC データを使って、どうやってエラー訂正するのでしょうか。
先ほどと同じく、8 ビットデータを例に取ります。
具体的に 0b00100010 の場合を見てみましょう。
ECC データは、0b001111 です。
読み出したユーザーデータが 1 ビット反転し、ECC ビットは正しかったとしましょう。
仮に b4 ビットが反転したとします。
この場合、ユーザーデータは 0b00110010 になります。
このユーザーデータから計算して得られる ECC ビットは、0b101010 になります。
一方、読み出し ECC データは 0b001111 です。
計算 ECC データ 0b101010 と読み出し ECC データ 0b001111 を比較すると、ビット 5 (P4), ビット 2 (P2`), ビット 0 (P1`) の計 3 ビットが異なっていることが分かります。
これは、何を意味しているでしょうか。
再度、データビットと ECC ビットの関連表を見てください。
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
| P4` | P4` | P4` | P4` | ||||
| P2` | P2` | P2` | P2` | ||||
| P1` | P1` | P1` | P1` | ||||
| P4 | P4 | P4 | P4 | ||||
| P2 | P2 | P2 | P2 | ||||
| P1 | P1 | P1 | P1 |
b4 が反転すると、P4, P2`, P1` が本来の値から反転します。
それ以外のビット、P4`, P2, P1 は b4 ビットの影響を受けず、計算 ECC ビットと読み出し ECC ビットは一致します。
P4, P2`, P1` のみが異なるパターンは、上の表と照らし合わせると b4 しかないことが分かりますので、b4 が反転したケースであることが特定できます。
ここまで特定できれば、b4 を反転させると、正しい値が得られるということが分かります。
ということで、正しく訂正できます。
今度は、読み出したユーザーデータは正しく、ECC データが 1 ビット反転したケースを考えてみましょう。
先ほどと同じく、0b00100010 の場合を考えます。
再度持ち出すまでもありませんが、ECC データは 0b001111 です。
仮に P1 が反転したとします。
読み出し ECC データは 0b001101 になります。
ユーザーデータは正しいので、計算 ECC は 0b001111 で変わりません。
そうすると、計算 ECC と、読み出し ECC は、ビット 1 (P1) だけが異なることになります。
このケースは、そのものずばり P1 のみが反転して誤っていたということになります。
P1 を反転させれば、正しい値になります(ユーザーデータが化けていたわけではないので、直す必要もありませんが)。
この場合も、正しく訂正できます。
以上のように、ユーザーデータ + ECC データのうち、1 ビットだけ反転したケースは、正しく訂正できます。
2 ビット反転した場合は、誤りがあることだけは検出できますが、訂正はできません。
3 ビット以上反転した場合は、誤りがあることを確実に検出することはできません。
誤りがあったことを検出するか、誤った判断で誤りなしと判断するか、誤った判断でエラー訂正するか、ビットの化け方次第です。
先に、NAND ECC は、ECC データ 22 ビットを 3 バイトに収めていると説明しましたが、xloader の場合、そのフォーマットは以下の図のようになっています。
最後の 2 ビットは、1 固定です。
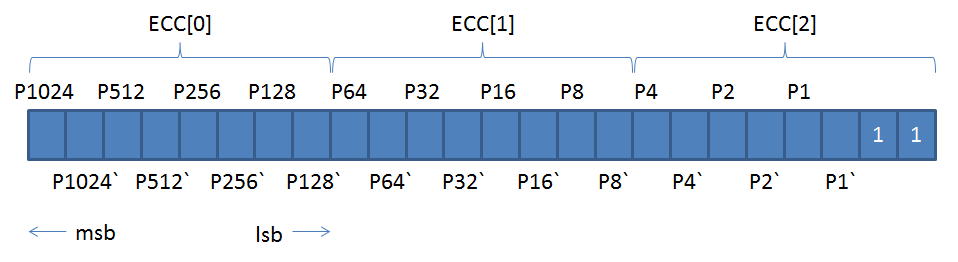
これが、スタンダードなのかどうか分かりませんが・・・。
ECC データ全体は合計で 24 バイトになりますが、この 24 バイトは、xloader では 1 ページの一番最後に配置しています。
再度、先ほどの図です。
これもスタンダードなのか、そうでないのか、不明です・・・。
これで、とりあえず ECC の説明はおしまいです。
・・・
xloader の ECC を扱うコードを見てみましょう。
やってることは上の説明の通りなのですが、これが難解で・・・
データから ECC を生成するコード、ECC によりデータを訂正するコードの両方があります。
まず ECC を生成するコードから見てみましょう。
28: /*
29: * Pre-calculated 256-way 1 byte column parity
30: */
31: static const u_char nand_ecc_precalc_table[] = {
32: 0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, ...
33: 0x65, 0x30, 0x33, 0x66, 0x3c, 0x69, ...
34: 0x66, 0x33, 0x30, 0x65, 0x3f, 0x6a, ...
35: 0x03, 0x56, 0x55, 0x00, 0x5a, 0x0f, ...
36: 0x69, 0x3c, 0x3f, 0x6a, 0x30, 0x65, ...
37: 0x0c, 0x59, 0x5a, 0x0f, 0x55, 0x00, ...
38: 0x0f, 0x5a, 0x59, 0x0c, 0x56, 0x03, ...
39: 0x6a, 0x3f, 0x3c, 0x69, 0x33, 0x66, ...
40: 0x6a, 0x3f, 0x3c, 0x69, 0x33, 0x66, ...
41: 0x0f, 0x5a, 0x59, 0x0c, 0x56, 0x03, ...
42: 0x0c, 0x59, 0x5a, 0x0f, 0x55, 0x00, ...
43: 0x69, 0x3c, 0x3f, 0x6a, 0x30, 0x65, ...
44: 0x03, 0x56, 0x55, 0x00, 0x5a, 0x0f, ...
45: 0x66, 0x33, 0x30, 0x65, 0x3f, 0x6a, ...
46: 0x65, 0x30, 0x33, 0x66, 0x3c, 0x69, ...
47: 0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, ...
48: };
49:
50:
51: /*
52: * Creates non-inverted ECC code from line parity
53: */
54: static void nand_trans_result(u_char reg2, u_char reg3,
55: u_char *ecc_code)
56: {
57: u_char a, b, i, tmp1, tmp2;
58:
59: /* Initialize variables */
60: a = b = 0x80;
61: tmp1 = tmp2 = 0;
62:
63: /* Calculate first ECC byte */
64: for (i = 0; i < 4; i++) {
65: if (reg3 & a) /* LP15,13,11,9 --> ecc_code[0] */
66: tmp1 |= b;
67: b >>= 1;
68: if (reg2 & a) /* LP14,12,10,8 --> ecc_code[0] */
69: tmp1 |= b;
70: b >>= 1;
71: a >>= 1;
72: }
73:
74: /* Calculate second ECC byte */
75: b = 0x80;
76: for (i = 0; i < 4; i++) {
77: if (reg3 & a) /* LP7,5,3,1 --> ecc_code[1] */
78: tmp2 |= b;
79: b >>= 1;
80: if (reg2 & a) /* LP6,4,2,0 --> ecc_code[1] */
81: tmp2 |= b;
82: b >>= 1;
83: a >>= 1;
84: }
85:
86: /* Store two of the ECC bytes */
87: ecc_code[0] = tmp1;
88: ecc_code[1] = tmp2;
89: }
:
130: void nand_calculate_ecc (const u_char *dat, u_char *ecc_code)
131: {
132: u_char idx, reg1, reg2, reg3;
133: int j;
134:
135: /* Initialize variables */
136: reg1 = reg2 = reg3 = 0;
137: ecc_code[0] = ecc_code[1] = ecc_code[2] = 0;
138:
139: /* Build up column parity */
140: for(j = 0; j < 256; j++) {
141:
142: /* Get CP0 - CP5 from table */
143: idx = nand_ecc_precalc_table[dat[j]];
144: reg1 ^= (idx & 0x3f);
145:
146: /* All bit XOR = 1 ? */
147: if (idx & 0x40) {
148: reg3 ^= (u_char) j;
149: reg2 ^= ~((u_char) j);
150: }
151: }
152:
153: /* Create non-inverted ECC code from line parity */
154: nand_trans_result(reg2, reg3, ecc_code);
155:
156: /* Calculate final ECC code */
157: ecc_code[0] = ~ecc_code[0];
158: ecc_code[1] = ~ecc_code[1];
159: ecc_code[2] = ((~reg1) << 2) | 0x03;
160: }
31 行目に、nand_ecc_precalc_table[] 配列が宣言されています。
この配列には、0 - 255 までの 1 バイト値に対して、以下の図のようなビットパターンで XOR を取ったものが格納されています。
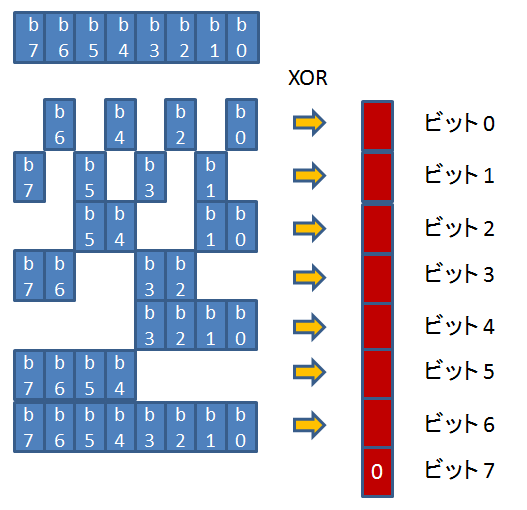
値 i に対して、上記のビットパターンで XOR を取ったものが nand_ecc_precalc_table[i] になっているわけです。
nand_ecc_precalc_table[i] の各ビットは、次のような意味を持ちます。
ビット 0: 値 i から計算した P1` (ただし奇数パリティではなく偶数パリティ、以下同じ)
ビット 1: 値 i から計算した P1
ビット 2: 値 i から計算した P2`
ビット 3: 値 i から計算した P2
ビット 4: 値 i から計算した P4`
ビット 5: 値 i から計算した P4
ビット 6: 値 i のすべてのビットで XOR を取った値
ビット 7: 常に 0
※P4 - P1` の意味が分からなくなってしまったら、ここを再度見てください。
次に、130 行目からの nand_calculate_ecc() 関数を見ていきましょう。
ローカル変数 reg1, reg2, reg3 は、以下のパリティ値を計算するために使用されます:
reg1: P4, P4`, P2, P2`, P1, P1`
reg2: P1024`, P512`, P256`, P128`, P64`, P32`, P16`, P8`
reg3: P1024, P512, P256, P128, P64, P32, P16, P8
139: /* Build up column parity */
140: for(j = 0; j < 256; j++) {
141:
142: /* Get CP0 - CP5 from table */
143: idx = nand_ecc_precalc_table[dat[j]];
144: reg1 ^= (idx & 0x3f);
140 行目は、256 バイトのユーザーデータを、1 バイトずつループを回す、の意です。
143 行目, 144 行目で、nand_ecc_precalc_table[dat[j]] の下位 6 ビットを取得し、その値と reg1 とで XOR を取っています。
idx の下位 6 ビットには、dat[j] から計算した P4, P4`, P2, P2`, P1, P1` の値が入ります。
reg1 には、0 から j - 1 番目までのデータで計算した P4, P4`, P2, P2`, P1, P1` が入っています。
この reg1 に、j 番目のデータの P4, P4`, P2, P2`, P1, P1` を XOR してあげれば、0 から j 番目までのデータで計算した P4, P4`, P2, P2`, P1, P1` が得られます。
これを 256 回ループで回せば、0 から 255 番目までのデータで計算した P4, P4`, P2, P2`, P1, P1` が得られます。
これで P4 - P1` は OK です。
P8/P8` 以降は、ECC を計算するビットが、8 ビット以上の長さで連続しています。
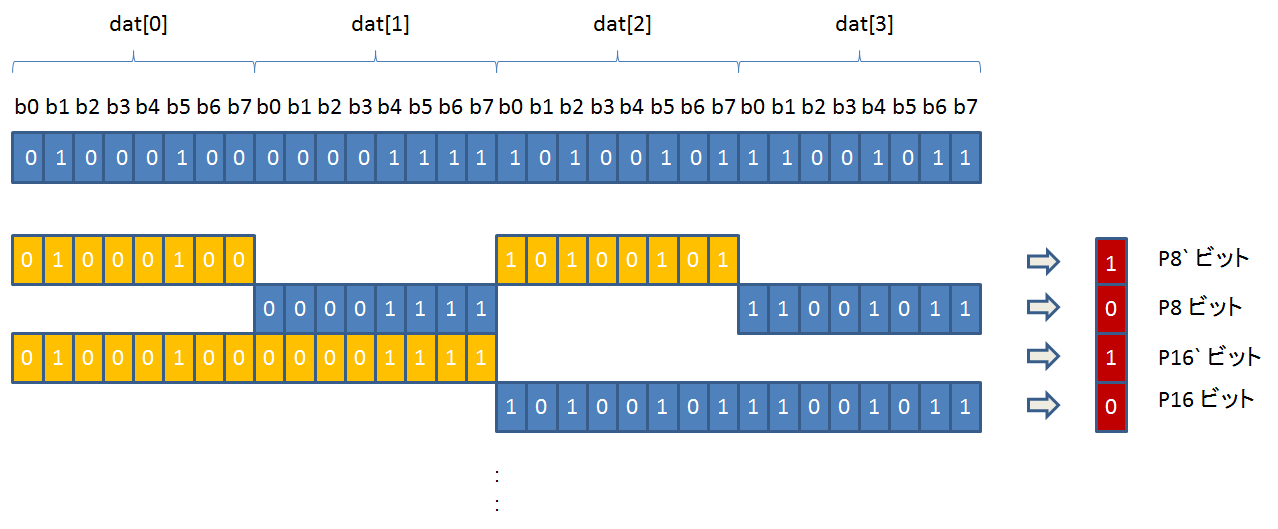
そのため、P8/P8` 以降は、バイト単位の XOR 値を用いて計算できます。
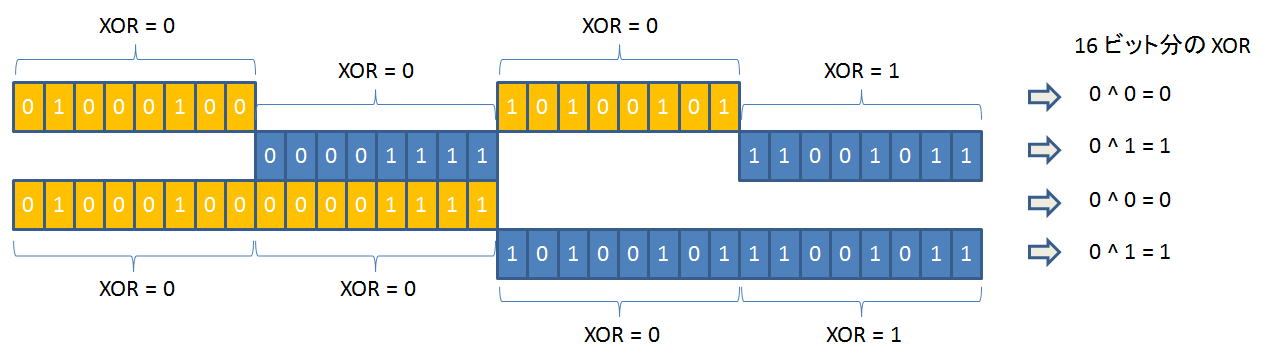
※↑の図と、その一つ上の図では、得られるビットの値が逆になっています。これは、XOR で得られる値は偶数パリティであるが、最終的な ECC ビットは奇数パリティなので、逆になっていると理解してください。
コードでは、P8/P8` 以降は、reg3, reg2 を使って計算します。
139: /* Build up column parity */
140: for(j = 0; j < 256; j++) {
141:
142: /* Get CP0 - CP5 from table */
143: idx = nand_ecc_precalc_table[dat[j]];
144: reg1 ^= (idx & 0x3f);
145:
146: /* All bit XOR = 1 ? */
147: if (idx & 0x40) {
148: reg3 ^= (u_char) j;
149: reg2 ^= ~((u_char) j);
150: }
151: }
idx のビット 6 は、値 dat[j] のすべてのビットで XOR を取った値が入っていることに注意してください。
147 行目の条件文は、「dat[j] のすべてのビットで XOR を取った値が 1」ならば、真になります。
XOR 計算は、0 と XOR を取る場合は値が変わらないので、計算する必要がありません。
1 と XOR を取る場合は値が変わるので、その場合は、P8/P8` 以降に反映させます。
その判定をしているのが、147 行目ということになります。
dat[j] の XOR 値が 1 だった場合、P8/P8` - P1024/P1024` までのうち、どの ECC ビットに反映させるかが問題となります。
DATA ビットと ECC ビットの関連表をもう一度見てください。
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
| P4` | P4` | P4` | P4` | ||||
| P2` | P2` | P2` | P2` | ||||
| P1` | P1` | P1` | P1` | ||||
| P4 | P4 | P4 | P4 | ||||
| P2 | P2 | P2 | P2 | ||||
| P1 | P1 | P1 | P1 |
これは、b7 - b0 が影響を与える ECC ビットを表す表でした。
この表に関して、
a. 影響を受ける P のビット番号の合計 = データのビット番号
b. 影響を受ける P` のビット番号の合計 = データのビット番号の反転
という法則があるのでした。
これと類似した法則が、dat と P8/P8` - P1024/P1024` との間にも成り立ちます。
簡単にするために、ユーザーデータを 256 バイトの代わりに 8 バイトデータで考えます。
dat が P8, P8`, P16, P16`, P32, P32` のどれに影響を与えるかという関連表を書くと、以下のようになります。
| dat[0] | dat[1] | dat[2] | dat[3] | dat[4] | dat[5] | dat[6] | dat[7] |
| P32 | P32 | P32 | P32 | ||||
| P16 | P16 | P16 | P16 | ||||
| P8 | P8 | P8 | P8 | ||||
| P32` | P32` | P32` | P32` | ||||
| P16` | P16` | P16` | P16` | ||||
| P8` | P8` | P8` | P8` |
今度は、↓のような関係があります。
A. 影響を受ける P のビット番号の合計 = (dat のインデックス) * 8
B. 影響を受ける P` のビット番号の合計 = (dat のインデックスの反転) * 8
(ここでもう一度、影響を受けるというのは、そのデータを元にして ECC が計算されている、という意味に取ってください。)
例えば、dat[2] で試してみると、
A-左辺 影響を受ける P のビット番号の合計 = 16
A-右辺 (dat のインデックス) * 8 = 16
B-左辺 影響を受ける P` のビット番号の合計 = 40
B-右辺 (dat のインデックスの反転) * 8 = ~2 * 8 = ~0b010 * 8 = 0b101 * 8 = 5 * 8 = 40
となって、合ってますね。
・・・というわけで、この法則を使って P8/P8` 以降を計算しているのが 148, 149 行目です。
148: reg3 ^= (u_char) j;
149: reg2 ^= ~((u_char) j);
reg3 の各ビットは、以下のように使われます。
ビット 7: P1024 用
ビット 6: P512 用
ビット 5: P256 用
ビット 4: P128 用
ビット 3: P64 用
ビット 2: P32 用
ビット 1: P16 用
ビット 0: P8 用
同じように、reg2 の各ビットは、以下のように使われます。
ビット 7: P1024` 用
ビット 6: P512` 用
ビット 5: P256` 用
ビット 4: P128` 用
ビット 3: P64` 用
ビット 2: P32` 用
ビット 1: P16` 用
ビット 0: P8` 用
それで、改めて 148, 149 行目を見ると、reg3 は P 用なので、反転せずにそのまま dat のインデックスを使い、reg2 は P` 用なので、反転した dat のインデックスを使っています。
具体的に、j = 2 の場合を見てみましょう。
reg3 には、dat[0], dat[1] から計算された Pi の値が入っています。
reg2 には、同じく dat[0], dat[1] から計算された Pi` の値が入っています。
dat[2] のビットのうち、ECC 計算に使うビットは、
・P16
・P8`, P32`, P64`, P128`, P256`, P512`, P1024` (16 以外全部)
です。
これはつまり、dat[2] の全ビットの XOR 値が 1 ならば (if (idx & 0x40))、 P16 と、P16` 以外のすべての Pi` を、反転させる必要があることを意味します。
reg3 と XOR を取る (u_char) j は、j = 2 の場合は、P16 用のビットだけが立っていることを示す値です。
reg3 には dat[0], dat[1] から計算された Pi の値が入っていますが、(u_char) j (j = 2) との XOR を取った結果、P16 だけが反転します。
P16 以外の Pi は変化しません。
0 との XOR 計算は、元の値を変えませんので。
この結果、dat[0], dat[1], および dat[2] から計算された Pi の値が得られたことになります。
これを 256 回まで繰り返せば、dat[0] から dat[255] までの値から計算された Pi の値が得られます。
reg2 も同様です。
reg2 と XOR を取る (u_char) ~j は、j = 2 の場合は、P16` 用のビットだけが落ち、それ以外のビットはすべて立っていることを示す値です。
reg2 には dat[0], dat[1] から計算された Pi` の値が入っていますが、(u_char)~j (j = 2) との XOR を取った結果、P16` 以外のすべてのビットが反転します。
P16` のビットだけは反転しません。
この結果、dat[0], dat[1], および dat[2] から計算された Pi` の値が得られたことになります。
これを 256 回まで繰り返せば、dat[0] から dat[255] までの値から計算された Pi` の値が得られます。
うーん、すごくよくできていますねー。
・・・ということで、for ループを抜けると、reg1, reg2, reg3 は、以下のようになります:
reg1:
ビット 7: 0
ビット 6: 0
ビット 5: 256 バイトデータで計算された P4 (ただし奇数パリティではなく偶数パリティ、以下同じ)
ビット 4: 256 バイトデータで計算された P4`
ビット 3: 256 バイトデータで計算された P2
ビット 2: 256 バイトデータで計算された P2`
ビット 1: 256 バイトデータで計算された P1
ビット 0: 256 バイトデータで計算された P1`
reg2:
ビット 7: 256 バイトデータで計算された P1024`
ビット 6: 256 バイトデータで計算された P512`
ビット 5: 256 バイトデータで計算された P256`
ビット 4: 256 バイトデータで計算された P128`
ビット 3: 256 バイトデータで計算された P64`
ビット 2: 256 バイトデータで計算された P32`
ビット 1: 256 バイトデータで計算された P16`
ビット 0: 256 バイトデータで計算された P8`
reg3:
ビット 7: 256 バイトデータで計算された P1024
ビット 6: 256 バイトデータで計算された P512
ビット 5: 256 バイトデータで計算された P256
ビット 4: 256 バイトデータで計算された P128
ビット 3: 256 バイトデータで計算された P64
ビット 2: 256 バイトデータで計算された P32
ビット 1: 256 バイトデータで計算された P16
ビット 0: 256 バイトデータで計算された P8
154 行目で nand_trans_result() 関数を呼び出し、reg2 と reg3 から、[P1024, P1024`, P512, P512`, P256, P256`, P128, P128`] および [P64, P64`, P32, P32`, P16, P16`, P8, P8`] を作ります。
153: /* Create non-inverted ECC code from line parity */
154: nand_trans_result(reg2, reg3, ecc_code);
最後、157 - 159 行目で、最終的な ECC データを生成します。
156: /* Calculate final ECC code */
157: ecc_code[0] = ~ecc_code[0];
158: ecc_code[1] = ~ecc_code[1];
159: ecc_code[2] = ((~reg1) << 2) | 0x03;
今まで計算してきた ECC データは、偶数パリティでした。
NAND ECC は奇数パリティなので、ビットを反転させます。
また、ECC データの 3 番目は、P4 がビット7, P1` がビット2 になるようにシフトされ、ビット1 とビット 0 は 1 とならなければいけないので、159 行目はそれもやっています。
これで、ECC 生成ロジックはおしまいです。
お疲れ様でした!
・・・
まだ、ECC 訂正ロジックが残っています。
ECC 訂正ロジックも、説明した通りのことをやっているのですが、こちらもちと手強くて・・・
生成ロジックに比べたら簡単なのですが。
162: /*
163: * Detect and correct a 1 bit error for 256 byte block
164: */
165: int nand_correct_data (u_char *dat, u_char *read_ecc, u_char *calc_ecc)
166: {
167: u_char a, b, c, d1, d2, d3, add, bit, i;
168:
169: /* Do error detection */
170: d1 = calc_ecc[0] ^ read_ecc[0];
171: d2 = calc_ecc[1] ^ read_ecc[1];
172: d3 = calc_ecc[2] ^ read_ecc[2];
173:
174: if ((d1 | d2 | d3) == 0) {
175: /* No errors */
176: return 0;
177: }
178: else {
179: a = (d1 ^ (d1 >> 1)) & 0x55;
180: b = (d2 ^ (d2 >> 1)) & 0x55;
181: c = (d3 ^ (d3 >> 1)) & 0x54;
182:
183: /* Found and will correct single bit error in the data */
184: if ((a == 0x55) && (b == 0x55) && (c == 0x54)) {
185: c = 0x80;
186: add = 0;
187: a = 0x80;
188: for (i=0; i<4; i++) {
189: if (d1 & c)
190: add |= a;
191: c >>= 2;
192: a >>= 1;
193: }
194: c = 0x80;
195: for (i=0; i<4; i++) {
196: if (d2 & c)
197: add |= a;
198: c >>= 2;
199: a >>= 1;
200: }
201: bit = 0;
202: b = 0x04;
203: c = 0x80;
204: for (i=0; i<3; i++) {
205: if (d3 & c)
206: bit |= b;
207: c >>= 2;
208: b >>= 1;
209: }
210: b = 0x01;
211: a = dat[add];
212: a ^= (b << bit);
213: dat[add] = a;
214: return 1;
215: }
216: else {
217: i = 0;
218: while (d1) {
219: if (d1 & 0x01)
220: ++i;
221: d1 >>= 1;
222: }
223: while (d2) {
224: if (d2 & 0x01)
225: ++i;
226: d2 >>= 1;
227: }
228: while (d3) {
229: if (d3 & 0x01)
230: ++i;
231: d3 >>= 1;
232: }
233: if (i == 1) {
234: /* ECC Code Error Correction */
235: read_ecc[0] = calc_ecc[0];
236: read_ecc[1] = calc_ecc[1];
237: read_ecc[2] = calc_ecc[2];
238: return 2;
239: }
240: else {
241: /* Uncorrectable Error */
242: return -1;
243: }
244: }
245: }
246:
247: /* Should never happen */
248: return -1;
249: }
169: /* Do error detection */
170: d1 = calc_ecc[0] ^ read_ecc[0];
171: d2 = calc_ecc[1] ^ read_ecc[1];
172: d3 = calc_ecc[2] ^ read_ecc[2];
170 行目から 173 行目までで、ユーザーデータから計算された ECC データと、ユーザーデータの後に付加されている ECC データの XOR を取っています。
174: if ((d1 | d2 | d3) == 0) {
175: /* No errors */
176: return 0;
177: }
計算 ECC と読み出し ECC がまったく同じなら、XOR は 0 になります。
これは、データがまったく化けていなかったケースですね。
174 行目は、その判定です。
この後は、いずれかのデータが化けたケースです。
179: a = (d1 ^ (d1 >> 1)) & 0x55;
180: b = (d2 ^ (d2 >> 1)) & 0x55;
181: c = (d3 ^ (d3 >> 1)) & 0x54;
182:
183: /* Found and will correct single bit error in the data */
184: if ((a == 0x55) && (b == 0x55) && (c == 0x54)) {
179 - 181 行目で、何やらビット操作をして、その値を使って 184 行目で判定をしていますが、この判定は、ユーザーデータが 1 ビットだけ反転しているケースか、もしくはそれ以外のケースかを判別しています。
なぜ、これでユーザーデータが 1 ビットだけ反転したということが分かるのでしょう?
179 行目の d1 ^ (d1 >> 1) の意味を考えてみましょう。
d1 の各ビットの意味は、次の通りです:
ビット 7: 計算 ECC と読み出し ECC の P1024 が不一致なら 1
ビット 6: 計算 ECC と読み出し ECC の P1024` が不一致なら 1
ビット 5: 計算 ECC と読み出し ECC の P512 が不一致なら 1
ビット 4: 計算 ECC と読み出し ECC の P512` が不一致なら 1
ビット 3: 計算 ECC と読み出し ECC の P256 が不一致なら 1
ビット 2: 計算 ECC と読み出し ECC の P256` が不一致なら 1
ビット 1: 計算 ECC と読み出し ECC の P128 が不一致なら 1
ビット 0: 計算 ECC と読み出し ECC の P128` が不一致なら 1
ユーザーデータが 1 ビットだけ反転しているケースでは、Pi と Pi` のうち、片方が一致し、もう片方が不一致になります。
[ビット 7, ビット 6], [ビット 5, ビット 4], [ビット 3, ビット 2], [ビット 1, ビット 0] の各組において、取りうる値は [1, 0] か [0, 1] だけです。
[1, 1] と [0, 0] はありません。
そうなったとしたら、他の化け方をしているケースです。
[1, 0] もしくは [0, 1] になっているかを判別するには、このビット同士で XOR を取ってみればいいですね。
[1, 0] もしくは [0, 1] ならば XOR 値は 1 になり、[0, 0] か [1, 1] ならば XOR 値は 0 になります。
179 - 181 行目のビット演算は、この XOR 計算をやっています。
この計算で、ビット 6, 4, 2, 0 のがすべて 1 になっているなら (= 0x55)、隣り合っているビット同士は、すべて [1, 0] か [0, 1] かのいずれかであると断定できます。
181 行目が、0x54 との比較になっているのは、ビット 6, 4, 2 だけを見ているからですね。
ECC データの 3 バイト目の下位 2 ビットは 1 固定になっているので、比較から排除しています。
・・・というわけで、171 - 184 行目により、ユーザーデータが 1 ビットだけ反転したケースか、それ以外のケースかが判別できます。
185 行目から 214 行目までが、反転ビットを探して、そのビットを反転させる処理です。
add が、反転ビットが何バイト目なのかを表す変数、bit が、そのバイトの中で何ビット目が反転しているかを表す変数であることに注意すれば、処理の意味は分かります。
a. 影響を受ける P のビット番号の合計 = データのビット番号
A. 影響を受ける P のビット番号の合計 = (dat の番号) * 8
にも注意しながら、見てみてください。
Pi` のビットを飛ばしながら、Pi のビットのみを見ていることが分かると思います。
ユーザーデータを正しく訂正した後、関数は終了です。
217 行目から 238 行目までが、ECC データが 1 ビットだけ反転したかどうかのチェックです。
ECC データが 1 ビットだけ反転した場合は、一つの Pi もしくは Pi` が不一致になり、それ以外の Pi/Pi` は一致になります。
d1, d2, d3 の 1 が立っているビットの合計が 1 であれば、ECC データが 1 ビットだけ反転したケースであると判別でき、ECC データを訂正して終了します。
それ以外のケースでは、訂正不可能なエラーであると判断して、-1 を返します。
・・・
ECC のコードは、理解するのは大変ですが、使う分には簡単です。
前回記事で、nand_program_page() を紹介しましたが、それには ECC 処理が入っていませんでした。
ECC 処理を追加すると、以下のようになります。
362: int nand_program_page(u_char *buf, int len, ulong addr)
363: {
364: int i, j;
365: u_char status = 0;
366: u_char *databuf = (u_char *)0x80000000;
367: int page_off = (int)(addr & (PAGE_SIZE - 1));
368: #ifdef NAND_16BIT
369: u16 *p;
370: page_off *= 2;
371: len *= 2;
372: #else
373: u_char *p;
374: #endif
375:
376: for (i = 0; i < page_off; i++)
377: databuf[i] = 0xff;
378: for (i = page_off, j = 0; i < page_off + len; i++, j++)
379: databuf[i] = buf[j];
380: for (i = page_off + len; i < PAGE_SIZE + OOB_SIZE - ECC_SIZE; i++)
381: databuf[i] = 0xff;
382:
383: #ifdef ECC_CHECK_ENABLE
384: for (i = 0, j = 0; i < ECC_SIZE; i += ECC_STEPS, j += 256)
385: nand_calculate_ecc(&databuf[j], &databuf[PAGE_SIZE + OOB_SIZE - ECC_SIZE + i]);
386: len = PAGE_SIZE + OOB_SIZE - page_off;
387: #endif /* ECC_CHECK_ENABLE */
388:
389: #ifdef NAND_16BIT
390: len /= 2;
391: #endif /* NAND_16BIT */
392:
393: NanD_Command(NAND_CMD_PROGRAM);
394: NanD_Address(ADDR_COLUMN_PAGE, addr);
395:
396: #ifdef NAND_16BIT
397: p = (u16 *)&databuf[page_off];
398: #else
399: p = &databuf[page_off];
400: #endif
401:
402: for (i = 0; i < len; i++, p++) {
403: WRITE_NAND(*p, NAND_ADDRESS);
404: }
405:
406: NanD_Command(NAND_CMD_PROGRAMSTART);
407:
408: while (1) {
409: status = nand_status();
410: serial_printf("[%s] status = 0x%x\n", __FUNCTION__, status);
411: if ((status & 0x60) == 0x60)
412: break;
413: wait_us_polling(1, 1000000);
414: }
415:
416: if (status & 0x01)
417: return 1;
418: else
419: return 0;
420: }
引数で受け取ったデータを書いた後、2048 バイト境界まで、元の値を変更しないように 0xff で埋め、ECC データ領域に ECC データを書き込みます。
データ訂正関数 nand_correct_data() は、READ PAGE を行う関数に入っています。
READ PAGE 関数では、nand_calculate_ecc() も使っています。
nand_calculate_ecc() は、読み書きで使い、nand_correct_data() は読み出しで使う、ということですね。
beagleboard を触ろう - メモリ [組み込みソフト]
beagleboard には、RAM と ROM が 2 つずつ搭載されています。
OMAP3530 内部に内臓 RAM と内臓 ROM、外部に SDRAM と NAND フラッシュメモリ、です。
内臓 RAM は、 OMAP35x TRM では SRAM internal や、OCM RAM などと表記されています。
(OCM は On Chip Memory の略)
容量 64KB の SRAM です。
この内臓 SRAM、 OMAP35x TRM にはあまり説明が載っていません。
「リセット後、2KB だけが使えるが、変更できる」と書いてあるのですが、どうやって変更するかという説明は、ありません。
xloader が動作しているときは、64KB が使えています。
イニシャルブートストラップである Boot ROM が、SRAM を 64KB 使えるように設定した上で xloader を実行しているのですが、実際にどうやっているのかは不明です。
蛇足ですが、これまでに何回か触れた通り、xloader は内臓 SRAM にロードされて実行されています。
次に、内臓 ROM ですが、 OMAP35x TRM では、OCM ROM などと表記されています。
マスク ROM ですので、書き換えはできません。
内臓 ROM にはイニシャルブートストラップが格納されており、リセット直後にイニシャルブートストラップのコードが実行されますので、何もしなくてもアクセスできるメモリ、ということになります。
(TRM にも「常にアクセスできる」と書いてあります。)
イニシャルブートストラップ以降は、内臓 ROM にアクセスすることは殆どないんでしょうねえ。
何らかのサービス関数が格納されている可能性はありますが。
・・・
SDRAM は、OMAP3530 の上に POP (Package-on-Package) として実装されています。
System Reference Manual によると、Micron 製の 2Gb (= 256MB) Mobile DDR SDRAM が載っています。
POP 実装されている Micron のチップの型番は、MT29C2G48MAKLCJI-6 なるもののようです。
MT29C2G48MAKLCJI-6 は、Mobile LPDRAM と NAND フラッシュがパッケージされた製品の型番です。
データレーン x16 の 2Gb NAND フラッシュメモリと、データレーン x32 の 1Gb LPDRAM が 2 つ載っています。
SDRAM は、SDRC (SDRAM Controller) によって制御されます。
SDRC は CS0 と CS1 の 2 つの Chip Select 信号を持っており、beagleboard でも CS0、CS1 両方を使っています。
1Gb のチップが 2 つなので。
Chip Select は、デバイスがアクセスされる際にアサートされる信号です。
CPU から、SDRAM がマップされているアドレスにアクセスすると、SDRC によって Chip Select 信号が SDRAM に対してアサートされます。
xloader に制御が移ってきた時点では、SDRAM にアクセスすることはできません。
誤ってアクセスすると、例外が発生してしまいます。
SDRC に対して初期化を行うことによって、初めてアクセスできるようになります。
Texas Instruments の WIKI に、SDRC 初期化に関する情報があります。
http://processors.wiki.ti.com/index.php/Setting_up_AM37x_SDRC_registers
OMAP35x TRM にも、もちろん説明はあるのですが、WIKI の方が分量も少ないし、こちらを見つつ、必要ならば TRM も参照するというのがいいのではないでしょうか。
それでは、xloader での SDRC 初期化を見てみましょう。
xloader では、config_3430sdram_ddr() という関数で SDRC の初期化を行っています。
271: void config_3430sdram_ddr(void)
272: {
273: /* reset sdrc controller */
274: __raw_writel(SOFTRESET, SDRC_SYSCONFIG);
275: wait_on_value(BIT0, BIT0, SDRC_STATUS, 12000000);
276: __raw_writel(0, SDRC_SYSCONFIG);
277:
278: /* setup sdrc to ball mux */
279: __raw_writel(SDRC_SDP_SHARING, SDRC_SHARING);
280:
281: if (beagle_revision() == REVISION_XM) {
282: __raw_writel(0x2, SDRC_CS_CFG); /* 256MB/bank */
283: __raw_writel(SDP_SDRC_MDCFG_0_DDR_XM, SDRC_MCFG_0);
284: __raw_writel(SDP_SDRC_MDCFG_0_DDR_XM, SDRC_MCFG_1);
285: __raw_writel(MICRON_V_ACTIMA_200, SDRC_ACTIM_CTRLA_0);
286: __raw_writel(MICRON_V_ACTIMB_200, SDRC_ACTIM_CTRLB_0);
287: __raw_writel(MICRON_V_ACTIMA_200, SDRC_ACTIM_CTRLA_1);
288: __raw_writel(MICRON_V_ACTIMB_200, SDRC_ACTIM_CTRLB_1);
289: __raw_writel(SDP_3430_SDRC_RFR_CTRL_200MHz, SDRC_RFR_CTRL_0);
290: __raw_writel(SDP_3430_SDRC_RFR_CTRL_200MHz, SDRC_RFR_CTRL_1);
291: } else {
292: __raw_writel(0x1, SDRC_CS_CFG); /* 128MB/bank */
293: __raw_writel(SDP_SDRC_MDCFG_0_DDR, SDRC_MCFG_0);
294: __raw_writel(SDP_SDRC_MDCFG_0_DDR, SDRC_MCFG_1);
295: __raw_writel(MICRON_V_ACTIMA_165, SDRC_ACTIM_CTRLA_0);
296: __raw_writel(MICRON_V_ACTIMB_165, SDRC_ACTIM_CTRLB_0);
297: __raw_writel(MICRON_V_ACTIMA_165, SDRC_ACTIM_CTRLA_1);
298: __raw_writel(MICRON_V_ACTIMB_165, SDRC_ACTIM_CTRLB_1);
299: __raw_writel(SDP_3430_SDRC_RFR_CTRL_165MHz, SDRC_RFR_CTRL_0);
300: __raw_writel(SDP_3430_SDRC_RFR_CTRL_165MHz, SDRC_RFR_CTRL_1);
301: }
302:
303: __raw_writel(SDP_SDRC_POWER_POP, SDRC_POWER);
304:
305: /* init sequence for mDDR/mSDR using manual commands (DDR is different) */
306: __raw_writel(CMD_NOP, SDRC_MANUAL_0);
307: __raw_writel(CMD_NOP, SDRC_MANUAL_1);
308:
309: delay(5000);
310:
311: __raw_writel(CMD_PRECHARGE, SDRC_MANUAL_0);
312: __raw_writel(CMD_PRECHARGE, SDRC_MANUAL_1);
313:
314: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_0);
315: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_1);
316:
317: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_0);
318: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_1);
319:
320: /* set mr0 */
321: __raw_writel(SDP_SDRC_MR_0_DDR, SDRC_MR_0);
322: __raw_writel(SDP_SDRC_MR_0_DDR, SDRC_MR_1);
323:
324: /* set up dll */
325: __raw_writel(SDP_SDRC_DLLAB_CTRL, SDRC_DLLA_CTRL);
326: delay(0x2000); /* give time to lock */
327:
328: }
274: __raw_writel(SOFTRESET, SDRC_SYSCONFIG);
275: wait_on_value(BIT0, BIT0, SDRC_STATUS, 12000000);
276: __raw_writel(0, SDRC_SYSCONFIG);
274 - 276 行目は、SDRC のリセットです。
275 行目は、SDRC_STATUS レジスタの ビット 0 (RESETDONE ビット) が立つのを、タイムアウト付きで待っています。
279: __raw_writel(SDP_SDRC_SHARING, SDRC_SHARING);
279 行目で、SDRC_SHARING レジスタに、0x0000_0100 (= SDP_SDRC_SHARING) を設定しています。
これにより、CS0, CS1 ともに 32 ビットデータレーンとして設定しています。
MT29C2G48MAKLCJI-6 の LPDRAM は 32 ビットバス幅を持っていますので、これで OK ですね。
292: __raw_writel(0x1, SDRC_CS_CFG); /* 128MB/bank */
292 行目では、CS1 の開始アドレスを設定しています。
CS0 の開始アドレスは 0x8000_0000 であり、この値は変更することができません(多分)。
しかし、CS1 のアドレス範囲は S/W で設定可能です。
292 行目により、CS1 の開始アドレスが 0x8800_0000 になります。
この結果、0x8000_0000 - 0x8800_0000 が CS0 に繋がったチップによってカバーされ、0x8800_0000 - 0x9000_0000 が CS1 に繋がったチップによってカバーされることになります。
つまり、0x8000_0000 - 0x9000_0000 の 256MB の連続空間が、SDRAM にマップされることになります。
ここから後は、CS0 と CS1 の両方に対する設定を、組にして行います。
293: __raw_writel(SDP_SDRC_MDCFG_0_DDR, SDRC_MCFG_0);
294: __raw_writel(SDP_SDRC_MDCFG_0_DDR, SDRC_MCFG_1);
293, 294 行目により、
・RAS 幅は 13 ビット
・CAS 幅は 10 ビット
・RAM サイズは 128 MB
・外部 SDRAM バス幅は 32 ビット
・deep-power-down mode サポート
・メモリタイプは DDR-SDRAM
という設定になります。
295: __raw_writel(MICRON_V_ACTIMA_165, SDRC_ACTIM_CTRLA_0);
296: __raw_writel(MICRON_V_ACTIMB_165, SDRC_ACTIM_CTRLB_0);
297: __raw_writel(MICRON_V_ACTIMA_165, SDRC_ACTIM_CTRLA_1);
298: __raw_writel(MICRON_V_ACTIMB_165, SDRC_ACTIM_CTRLB_1);
295 行目から 298 行目は、タイミングパラメータです。
接続されている SDRAM に依存するパラメータであり、どのような値が適正値か知るのは困難ですが、
http://processors.wiki.ti.com/index.php/Setting_up_AM37x_SDRC_registers
に、OMAP35x/AM/DM37x DDR register calc tool なるツールがあり、これを使うと、適正値を得ることができます。
でも、SDRAM のデータシートが必要ですが。
搭載 SDRAM の型番は、MT46H32M32LFJG-6 IT のようです。
MT46H32M32LFJG-6 IT のデータシートを、適当に探して中を見てみると・・・
・・・必要なタイミング値が載っていない・・・。
うーん、まあ、仕方ないですね。
今の設定値で普通に SDRAM 使えてますし、多分、適正な値が設定されているのでしょう。
299: __raw_writel(SDP_3430_SDRC_RFR_CTRL_165MHz, SDRC_RFR_CTRL_0);
300: __raw_writel(SDP_3430_SDRC_RFR_CTRL_165MHz, SDRC_RFR_CTRL_1);
299, 300 行目により、リフレッシュレートを設定します。
こちらも SDRAM 依存なので、データシートのタイミング値があれば、より適切な設定値が分かる可能性があるのですが、仕方ないですね。
今の設定値で普通に SDRAM 使えてますし、多分、適正な値が設定されているのでしょう。
303: __raw_writel(SDP_SDRC_POWER_POP, SDRC_POWER);
303 行目は、パワーセーブ系の設定です。
しかし、詳細を説明できるほどの知識がありません・・。
305: /* init sequence for mDDR/mSDR using manual commands (DDR is different) */
306: __raw_writel(CMD_NOP, SDRC_MANUAL_0);
307: __raw_writel(CMD_NOP, SDRC_MANUAL_1);
308:
309: delay(5000);
310:
311: __raw_writel(CMD_PRECHARGE, SDRC_MANUAL_0);
312: __raw_writel(CMD_PRECHARGE, SDRC_MANUAL_1);
313:
314: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_0);
315: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_1);
316:
317: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_0);
318: __raw_writel(CMD_AUTOREFRESH, SDRC_MANUAL_1);
319:
320: /* set mr0 */
321: __raw_writel(SDP_SDRC_MR_0_DDR, SDRC_MR_0);
322: __raw_writel(SDP_SDRC_MR_0_DDR, SDRC_MR_1);
305 行目から 318 行目までは、SDRAM に対する初期化シーケンスの発行です。
このようにやりなさい、というのが、OMAP35x TRM の Low-Power SDR/Mobile DDR Initialization Sequence 節に書かれています。
その後、SDRC_MR レジスタを設定しなさい、ということも書かれていて、321 行目、322 行目はそれをやっています。
これは、CAS レイテンシーを 3 にし、バースト長を 4 に設定しています。
324: /* set up dll */
325: __raw_writel(SDP_SDRC_DLLAB_CTRL, SDRC_DLLA_CTRL);
最後、325 行目ですが、これは、Double Data Ratio (DDR) のタイミングを調整するもののようです。
DDR の場合、データを取り込む際に、クロック信号ではなく、データストローブ信号を使うようなのですが、このデータストローブ信号をクロック信号より 90度遅らせるようにする、というのが 325 行目かな・・。
すみません、よく分かっていません (^^;
まあ、これでとにかく、SDRAM が使えるようになります。
・・・
最後、NAND フラッシュです。
NAND フラッシュは、メモリといっても RAM のように簡単にアクセスすることはできません。
読むのも書くのも消去するのも、コマンドを発行することによって行います。
また、読み出しも、書き込みも、ページという単位で行います。
beagleboard に載っている NAND フラッシュは、MT29F2G16ABDHC-ET という型番なのですが(多分)、MT29F2G16ABDHC-ET の 1 ページは 2112 バイトです(ユーザーデータ 2048 + ECC データ 64)。
読み出す場合は、NAND メモリアレイから 1 ページ分(NAND フラッシュ内部の) DATA レジスタに読み込み、CPU は DATA レジスタから値を取得します。
(レジスタというと、普通は 4 バイト長ですが、ここでいう DATA レジスタはページサイズ分の大きさがあります。)
CPU が、DATA レジスタの値をどれくらい読み出すかは、自由です。
1 バイトでも 1 ページ分でも構いません。
ただ、1 バイトだけ読み出すだけでも、内部的には 1 ページ分の読み出し動作が行われます。
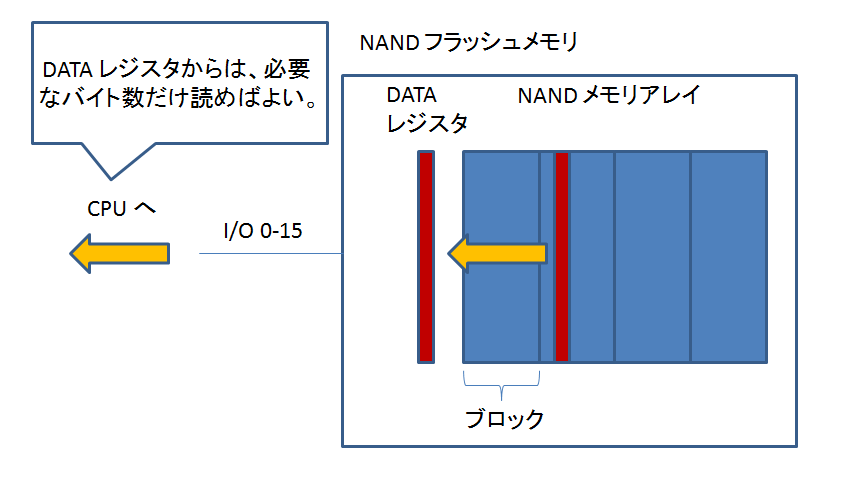
書き込みの場合、(NAND フラッシュ内部の)DATA レジスタはオール 1 にリセットされます(すべてのバイトが 0xFF)。
その状態で、CPU は DATA レジスタに、必要な分だけ値を上書きします。
DATA レジスタにどれくらい書き込むかは自由です。
1 バイトでも 1 ページ分でも構いません。
その後、DATA レジスタから、NAND メモリアレイに 1 ページ分書き込まれます。
すぐ後で触れますが、1 を NAND メモリアレイに書き込んでも、ビット値は変化しないので、CPU が上書きしなかったところは、不変になります。
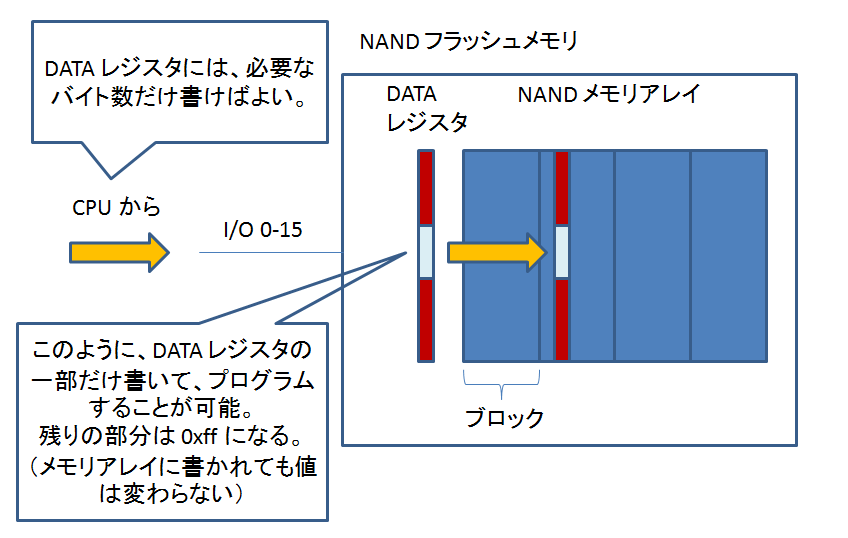
フラッシュメモリへの書き込みは、通常、プログラムと言います。
プログラムは、各ビットを 1 から 0 にすることしかできません。
0 から 1 にすることはできないのです。
例えば、あるバイトを 0xFF から 0x00 にすることはできても、0x00 から 0xFF にすることはできません。
あるビットに 1 を書くと、もともと 1 であった場合は 1 がキープされますし、0 であった場合も 0 → 1 への変更はできないので、0 がキープされます。
つまり、あるバイトに 0xFF を書くと、そのバイトは変更されません。
プログラムを行う前には、通常、消去を行います。
消去は、すべてのビットを 1 にします。
消去の単位は、プログラムの単位であったページよりも更に広いブロックという単位で行います。
MT29F2G16ABDHC-ET の 1 ブロックは、64 ページです。
消去およびプログラムを行うことにより、任意の値を書き込むことができます。
NAND フラッシュはアドレスピンを持っていません。
コマンド、アドレス、データ、いずれも I/O ピン上を流れます。
今送っているのがコマンドなのか、アドレスなのか、データなのかが判別できるように、CLE, ALE といった信号を使っています。
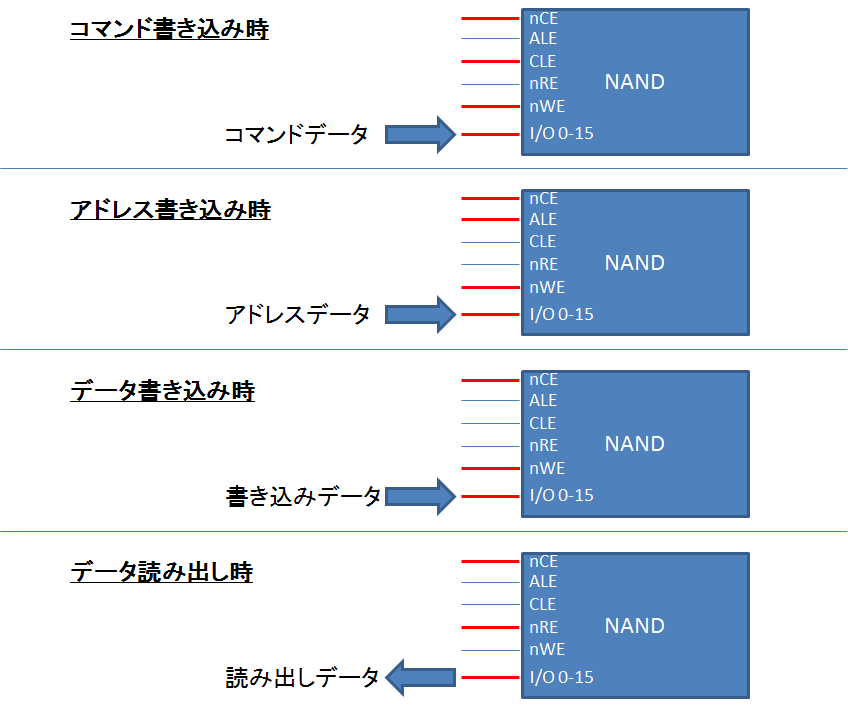
OMAP3530 では、NAND フラッシュは GPMC (General Purpose Memory Controller) モジュールの下に繋がれています。
GPMC は、GPMC_NAND_COMMAND, GPMC_NAND_ADDRESS, GPMC_NAND_DATA というレジスタを持っており、それぞれのレジスタに値を書き込むと、NAND フラッシュにはそれぞれ、コマンド、アドレス、データとして書き込まれます。
また、GPMC は、制御信号のタイミングの面倒も見てくれます。
CPU 側と NAND フラッシュは、nCE, ALE, CLE, nRE, nWE, I/O といった信号を制御してデータをやり取りするわけですが、信号を active/inactive にするタイミングを NAND フラッシュに合わせないと、うまくやり取りできません。
あらかじめ GPMC にタイミング値を設定しておくと、GPMC はその設定に従ってタイミングを計りながら NAND フラッシュにアクセスしてくれます。
S/W としては、何も考えずに GPMC_NAND_COMMAND, GPMC_NAND_ADDRESS, GPMC_NAND_DATA に値を書くだけで、後は GPMC がよきに計らってくれます。
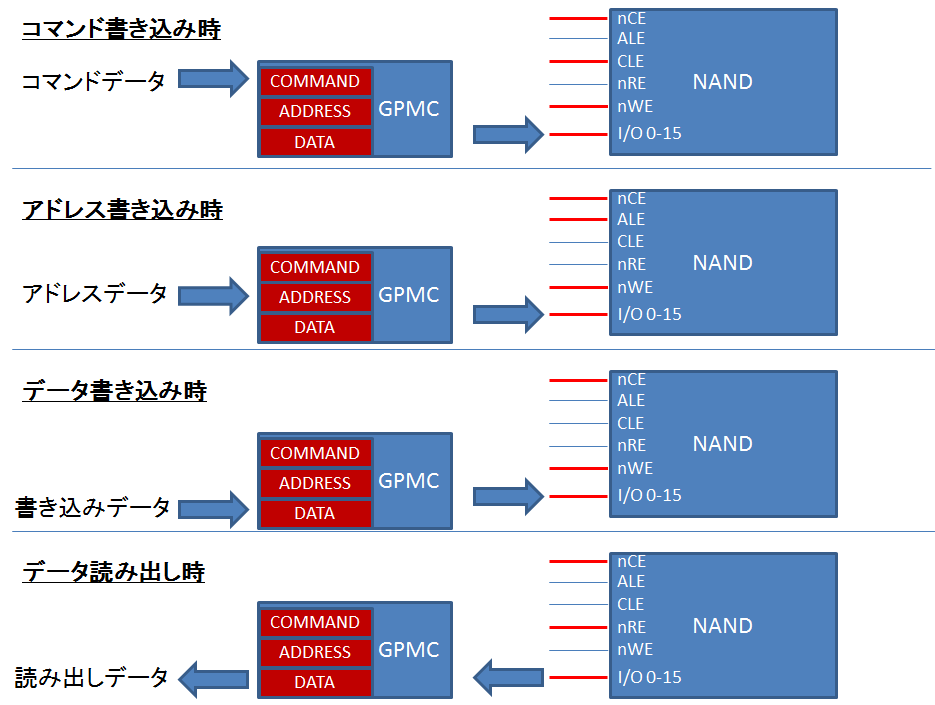
NAND からデータを読み書きするには、GPMC_NAND_COMMAND, GPMC_NAND_ADDRESS, GPMC_NAND_DATA にアクセスすればよいだけです。
これらのレジスタに対する基本的なオペレーションは、
・GPMC_NAND_COMMAND に 1 バイトのコマンドを書く
・GPMC_NAND_ADDRESS に数バイトのアドレスを書く
(・GPMC_NAND_COMMAND に 1 バイトの第 2 コマンドを書く)
・GPMC_NAND_DATA から必要なバイト数読み書きする
といった感じです。
コマンドの種類と、アドレスの与え方は、以下の表のようになっています。
アドレスの与え方は、下の表に従います。
与えるアドレスは、x16 製品の場合は 2 バイト単位だと思います。
(例えば、先頭から 128K バイト目を指定したい場合は、アドレス 64K を指定する。)
少なくとも、MT29F2G16ABDHC-ET は、そうです。
x8 製品だったら、多分、バイト単位でしょうね。
読み出し、消去、書き込み(プログラム)は、以下のようにします。
READ PAGE オペレーション
・コマンド 0x00 を GPMC_NAND_COMMAND に書き込み
・アドレス First, Second, Third, Fourth, Fifth を、この順に GPMC_NAND_ADDRESS に書き込み
・コマンド 0x30 を GPMC_NAND_COMMAND に書き込み
・GPMC_NAND_DATA から必要な分だけデータ読み出し(ただし、ページ境界まで)
ERASE BLOCK オペレーション
・コマンド 0x60 を GPMC_NAND_COMMAND に書き込み
・アドレス Third, Fourth, Fifth を、この順に GPMC_NAND_ADDRESS に書き込み
・コマンド 0xD0 を GPMC_NAND_COMMAND に書き込み
PROGRAM PAGE オペレーション
・コマンド 0x80 を GPMC_NAND_COMMAND に書き込み
・アドレス First, Second, Third, Fourth, Fifth を、この順に GPMC_NAND_ADDRESS に書き込み
・GPMC_NAND_DATA に必要な分だけデータ書き込み(ただし、ページ境界まで)
・コマンド 0x10 を GPMC_NAND_COMMAND に書き込み
xloader の NAND ドライバーは k9f1g08r0a.c というファイルです。
元々は、READ PAGE しかサポートしていないのですが、ERASE BLOCK, PROGRAM PAGE を追加すると、以下のようになります。
やっていることは、上の説明の通りです。
(使いやすくするため、コマンドの完了チェックを追加しています。)
330: u_char nand_status(void)
331: {
332: u16 status;
333:
334: NanD_Command(NAND_CMD_STATUS);
335: status = READ_NAND(NAND_ADDR);
336:
337: return (u_char)status;
338: }
339:
340: int nand_erase_block(ulong block_addr)
341: {
342: u_char status = 0;
343:
344: NanD_Command(NAND_CMD_ERASE);
345: NanD_Address(ADDR_PAGE, block_addr);
346: NanD_Command(NAND_CMD_ERASESTART);
347:
348: while (1) {
349: status = nand_status();
350: serial_printf("[%s] status = 0x%x\n", __FUNCTION__, status);
351: if ((status & 0x60) == 0x60)
352: break;
353: wait_us_polling(1, 1000000);
354: }
355:
356: if (status & 0x01)
357: return 1;
358: else
359: return 0;
360: }
361:
362: int nand_program_page(u_char *buf, int len, ulong page_addr)
363: {
364: int cntr;
365: u16 *p = (u16 *)buf;
366: u_char status = 0;
367:
368: NanD_Command(NAND_CMD_PROGRAM);
369: NanD_Address(ADDR_COLUMN_PAGE, page_addr);
370:
371: if (bus_width == 16)
372: len /= 2;
373: for (cntr = 0; cntr < len; cntr++, p++) {
374: WRITE_NAND(*p, NAND_ADDRESS);
375: }
376:
377: NanD_Command(NAND_CMD_PROGRAMSTART);
378:
379: while (1) {
380: status = nand_status();
381: serial_printf("[%s] status = 0x%x\n", __FUNCTION__, status);
382: if ((status & 0x60) == 0x60)
383: break;
384: wait_us_polling(1, 1000000);
385: }
386:
387: if (status & 0x01)
388: return 1;
389: else
390: return 0;
391: }
あ、NAND は write protect がかけられるようになっていて、xloader による初期設定では、write protect がオンになっています。
消去、プログラムを試そうと思ったら、write protect を外しておく必要があります。
sr32(GPMC_CONFIG, 4, 1, 1);
この 1 行を、どこか適当なところ(nand_init() 関数とか)に追加しておく必要があります。
・・・
とりあえずこれで、NAND フラッシュの説明はおしまいです。
NAND フラッシュ全般に関しては、この EE Times の記事↓などを参考にされるとよいかと思います。
http://www.eetimes.com/design/memory-design/4009410/Flash-memory-101-An-Introduction-to-NAND-flash
この記事の内容は、ほぼそのまま beagleboard の MT29F2G16ABDHC-ET にも適用できると思いますが、ページ真中辺のアドレスの与え方の説明が、ちょっとだけ違います。
EE Times のは、容量 = 2GB, I/O = x8 の NAND フラッシュの説明になっているみたいで、MT29F2G16ABDHC-ET は 2GB, x16 なので、微妙に違います。
下の図で、上側が x16, 下側が x8 のアドレスの与え方です。
beagleboard を触ろう - LED とボタン [組み込みソフト]
beagleboard 上の LED を点灯させてみたいと思います。
beagleboard には、ユーザーが制御できる LED が 3 つあります。
うち 2 つは GPIO によって制御でき、残り 1 つは電源モジュール TPS65950 によって制御できます。
TPS65950 は、OMAP3530 の外部にあるデバイスで、OMAP3530 とは I2C バスによって繋がっています。
TPS65950 制御の LED は、OMAP3530 からは、I2C モジュールを制御することによって点灯させます。
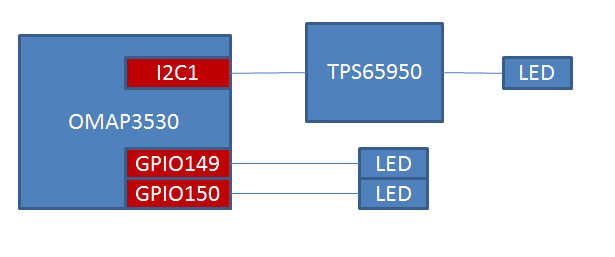
まずは GPIO 制御の LED の方から。
ボードを見ると、2 つの LED の近傍に USR0, USR1 と書いてあります。
USR0/USR1 LED は、GPIO 149 と GPIO 150 によって制御します。
USR0 LED は、OMAP3530 の外部ピン W8 に、USR1 LED は、同じく AA9 に接続されています。
W8 は、内部的には、UART1 CTS か、GPIO 150 か、HSUSB3 TLL CLK かのいずれかに割り当てることができます。
また、AA9 は、内部的には、UART1 RTS か、GPIO 149 か、どちらかに割り当てることができます。
この選択は、S/W で行います。
xloader による設定では、W8 も AA9 も、GPIO に割り当てられます。
971: MUX_VAL(CP(UART1_RTS), (IDIS | PTD | DIS | M4)) /*GPIO_149*/
972: MUX_VAL(CP(UART1_CTS), (IDIS | PTD | DIS | M4)) /*GPIO_150*/
GPIO の制御は簡単です。
1. 入力か、出力かを決める
2. 読み/書きする
だけです。
入力か出力かは、GPIO_OE レジスタによって決定します。
GPIO にディップスイッチなどが繋がっている場合は入力を、LED などが繋がっている場合は出力にします。
読み/書きは、GPIO_DATAIN / GPIO_DATAOUT を読み書きします。
書き込みの場合は、GPIO_SETDATAOUT, GPIO_CLEARDATAOUT の組を使う方法もあります。
GPIO_SETDATAOUT に 1 を書けば 1 が立ち、GPIO_CLEARDATAOUT に 1 を書けば、1 が落ちて 0 になります。
書き込んだ値は保持されるので、一度 1 にすれば LED が点灯し続けます。
消灯させるには、1 を落として 0 にします。
GPIO_OE, GPIO_DATAIN, GPIO_DATAOUT, GPIO_SETDATAOUT, GPIO_CLEARDATAOUT といったレジスタは、いずれも 32 ビットのレジスタ x 6 本で構成されています。
各ビットが、1 つの GPIO に対応します。
つまり、GPIO は、32 x 6 = 192 個存在します。
LED の点灯では、このうち 149 番と 150 番を使います。
TPS65950 制御の LED の方は、近傍に PMU STAT と印字されています。
PMU STAT LED を制御するには、TPS65950 での LED 制御方法と I2C の制御方法の両方を知る必要があります。
TPS65950 TRM の中に数ページほど、LED の制御方法が解説されています。
制御レジスタは、LEDEN という名前で、こんな↓です。
beagleboard に搭載されている PMU STAT LED は、TRM でいうところの LEDB です。
なので、LEDEN レジスタの LEDBON ビット(ビット 1)を立ててやればよいということになります。
(実際に動かしてみると、LEDBON ビットのみならず、LEDBPWM ビットも立てないと光らないです。なぜかなあ?)
LEDEN レジスタは、OMAP3530 からは直接アクセスできません。
I2C バス上にコマンドを流すことによって、間接的にアクセスします。
I2C は、下の図のように、「スレーブのアドレス」 + 「データ」の組でやり取りを行います。
データをマスターから送るか、スレーブから送るかは、スレーブアドレスの後の 1 ビット (R/W) が 0 か 1 かで決まります。
下の図では、上の方がマスターからスレーブにデータ送信する場合、下の方がマスターがスレーブからデータ受信する場合を表しています。
I2C のプロトコルに関する説明は、検索すると、よいものがたくさんあります。
"I2C 仕様" とかで検索してみてください。
TPS65950 は I2C バス上でスレーブになります。
スレーブアドレスは、0x48, 0x49, 0x4a, 0x4b の 4 つを持っており、スレーブアドレスごとに担当する機能が分けられているみたいです。
LED を制御する機能は、スレーブアドレス 0x4A なので、0x4A に続いてデータを送信します。
TPS65950 の LEDEN レジスタに LEDBON ビット(と LEDBPWM ビット)を立てるにはどうすればよいでしょうか。
TPS65950 TRM を見てみると、LEDEN の Physical address は 0x0000_00EE とあります。
0x0000_00EE に、LEDBON ビット + LEDBPWM ビット = 0x22 を書き込めばよいのです。
こんな感じで、アドレス、レジスタアドレス、書き込みデータ、という順に送信します。
TPS65950 はこのデータを受け取ると、アドレス 0xEE にデータ 0x22 を書き込む命令と解釈し、内部で書込みを実行します。
レジスタ値を読み出す場合は、スレーブアドレス、レジスタアドレスを送信した後、再度スレーブアドレスを送信すると、TPS65950 は、指定されたレジスタの値を返してきます。
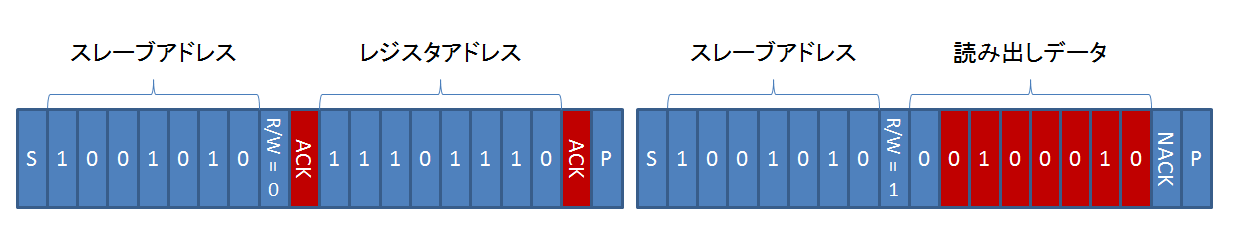
I2C 上で送るデータをどのように解釈するかは、スレーブデバイス次第だと思いますが、シリアル EEPROM なんかだと、TPS65950 と全く同じようなデータフォーマットでやり取りを行います。
即ち、書き込みの場合は、スレーブアドレス、書き込みアドレス、書き込みデータという順に送信し、読み込みの場合は、スレーブアドレス、読み出しアドレス、スレーブアドレスという順に送信し、その後、読み出しデータを受信します。
TPS65950 制御の PMU STAT LED は、PWM によって輝度調整が可能です。
GPIO 制御の USR0/USR1 LED は、オン、オフの 2 通りしかありませんが、こちらは暗めに点けたりとか、だんだん明るくしたりとか、だんだん暗くしたりとかの制御ができます。
PWM をどのように制御するかは、TPS65950 TRM に載っています。
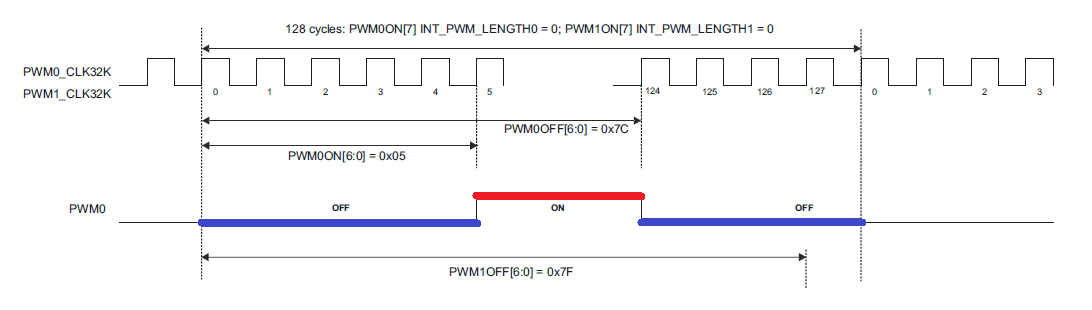
クロック周波数 32KHz の 128 クロック分が 1 サイクルになっています。
1 サイクルの中で、どのタイミングでオンして、どのタイミングでオフするかがプログラム可能になっています。
上の図でいうと、赤線部分がオンで、青線部分がオフです。
オンの時間が長ければ明るく、オフの時間が長ければ暗くなります。
例えば、クロック 0 でオンして、クロック 127 でオフするようにプログラムすると、128 クロック中、127 クロックの間オンということになるので、最大輝度の 127/128 の明るさで点灯することになります。
クロック 126 でオンして、クロック 127 でオフすると、1/128 の明るさで点灯します。
徐々に明るくしたり、暗くしたりするには、タイマーを使えばいいですね。
10 msec ごとに 1/128 ずつ明るくしていけば、1.28 秒で最小輝度から最大輝度まで変化します。
それでは、簡単なテストプログラムです。
GPIO にしろ、I2C にしろ、xloader がドライバ関数を用意してくれているので、LED を点けるのは簡単です。
231: static unsigned char ledon;
232: static unsigned char ledoff;
233:
234: static void led_timer_handler(int irq)
235: {
236: static int inc = -1;
237:
238: clear_timer_interrupt(irq);
239:
240: ledon += inc;
241:
242: if (ledon == 126)
243: inc = -1;
244: else if (ledon == 0)
245: inc = 1;
246:
247: i2c_write(0x4A, 0xF1, 1, &ledon, 1);
248: }
249:
250: static int led_test(void)
251: {
252: unsigned char cmd;
253:
254: printf("[%s]\n", __FUNCTION__);
255:
256: omap_set_gpio_direction(149, 0);
257: omap_set_gpio_direction(150, 0);
258:
259: serial_ch = 0;
260: intc_enable_irq(UART3_IRQ);
261:
262: cmd = 0x22;
263: ledon = 126;
264: ledoff = 127;
265: i2c_write(0x4A, 0xEE, 1, &cmd, 1);
266: i2c_write(0x4A, 0xF1, 1, &ledon, 1);
267: i2c_write(0x4A, 0xF2, 1, &ledoff, 1);
268:
269: start_timer(1, 10000, led_timer_handler);
270:
271: while (serial_ch != 'q') {
272: omap_set_gpio_dataout(149, 1);
273: omap_set_gpio_dataout(150, 0);
274:
275: wait_us_interrupt(2, 1260000);
276:
277: omap_set_gpio_dataout(149, 0);
278: omap_set_gpio_dataout(150, 1);
279:
280: wait_us_interrupt(2, 1260000);
281: }
282:
283: omap_set_gpio_dataout(149, 0);
284: omap_set_gpio_dataout(150, 0);
285:
286: ledon = 127;
287: ledoff = 0;
288: i2c_write(0x4A, 0xF1, 1, &ledon, 1);
289: i2c_write(0x4A, 0xF2, 1, &ledoff, 1);
290:
291: stop_timer(1);
292: intc_disable_irq(UART3_IRQ);
293:
294: return 0;
295: }
256, 257 行目で GPIO 149, 150 の入出力方向を「出力」に設定しています。
262 行目から 267 行目までは PMU STAT LED の初期設定です。
PWM を使って、輝度 1/128 の明るさで PMU STAT LED を点けています。
PMU STAT LED は、10 ms タイマーを使って、led_timer_handler() により、輝度を 1/128 ずつ変えています。
USR0/USR1 LED は、271 行目から 281 行目の処理により、126 ms 毎に点滅させています。
PMU STAT LED が輝度最小から最大(またはその逆)に変化するまで 126 ms かかるので、USR0, USR1, PMU STAT は同期して点灯します。
こんな感じです。
ダウンロードは🎥こちら
手前の交互に点滅しているのが USR0, USR1, 奥の徐々に明るさが変わっているのが PMU STAT です。
左側の常時点灯しているのは、電源が入ると自動的に光る PWR LED です。
PMU STAT の明暗の変化が、なんか変なような気もしますが・・・。
一番暗くなった後に、急に明るくなる感じ (^^;
・・・
出力タイプの GPIO を使ったので、ついでに入力タイプの方も見てみたいと思います。
beagleboard 上には USER ボタンが付いていますが、これが押されたかどうか、GPIO 7 により取得することができます。
入力方向の場合は、割り込みも使えます。
押された/離されたというイベントが発生した時に、割り込みを上げることができます。
USER ボタンは OMAP3530 の AE21 ピンに繋がっています。
AE21 ピンは、内部的には、sys_boot5 か、mmc2_dir_dat3 か、GPIO 7 のいずれかに割り当てることができますが、xloader による設定では、GPIO に割り当てられています。
制御方法は、割り込みを使う場合、
1. GPIO_OE レジスタによって、「入力」方向に設定する
2. 立ち上がり、立ち下がり、高値水平、低値水平(日本語変?)のうち、どのイベントで割り込みを上げるかを決定する
3. GPIO_IRQENABLE1 レジスタによって、割り込みを有効にする
4. 割り込みが上がってきたら、割り込みハンドラーによって GPIO_DATAIN レジスタを読む
といった感じです。
2 についてですが、ボタンが押された時、離された時を知りたい時は、立ち上がり、および立ち下がりで割り込みを上げるように設定します。
仮に、高値水平、低値水平の両方で割り込みを上げるようにすると、ボタンが押された / 離された瞬間以外は常に割り込みが上がる状態になってしまい、あまり使えません (^^;
高値水平、低値水平はどういうデバイスで使うのかな・・・。
ボタン、ディップスイッチでは使わなさそうですね。
入力は、GPIO_CTRL によって定まるクロック x 2 以上の間、サンプリングされます。
立ち上がり / 立ち下がりで割り込みを上げる設定にしている場合、この時間内に立ち上がって立ち下がって元の状態に戻ったとすると、立ち上がり / 立ち下がり割り込みは発生しません。
即ち、H/W によってチャタリングが除去されるわけですね。
実際にテストプログラムを動かしてみても、チャタリング除去が効いていることが分かります。
テストプログラムは、こんな感じです。
296: static void button_handler(int irq)
297: {
298: if (omap_get_gpio_irqstatus(7) == 0) {
299: serial_printf("other event 0x%x\n", omap_get_gpio_irqstatus(7));
300: return;
301: }
302:
303: if (omap_get_gpio_datain(7))
304: serial_printf("button pressed\n");
305: else
306: serial_printf("button released\n");
307:
308: omap_clear_gpio_irqstatus(7);
309: }
310:
311: static int button_test(void)
312: {
313: serial_ch = 0;
314: intc_enable_irq(UART3_IRQ);
315:
316: omap_set_gpio_direction(7, 1);
317: omap_set_gpio_risingdetect(7, 1);
318: omap_set_gpio_fallingdetect(7, 1);
319:
320: register_handler(button_handler, GPIO_IRQ(7));
321: omap_clear_gpio_irqstatus(7);
322: omap_enable_gpio_irq(7);
323: intc_enable_irq(GPIO_IRQ(7));
324:
325: while (serial_ch != 'q') {
326: ;
327: }
328:
329: intc_disable_irq(UART3_IRQ);
330:
331: intc_disable_irq(GPIO_IRQ(7));
332: omap_disable_gpio_irq(7);
333: omap_clear_gpio_irqstatus(7);
334:
335: return 0;
336: }
316 行目で、GPIO 7 の入出力方向を、「入力」に設定しています。
317 行目、318 行目で、立ち上がり、立ち下がりで割り込みが発生するように設定しています。
320 行目で、296 行目の button_handler を割り込みハンドラーとして登録しています。
マクロ GPIO_IRQ(7) は、29 に展開されます。
GPIO 0 - 31 は、IRQ 番号 29 が割り当てられていますので。
322 行目は、GPIO_IRQENABLE1 レジスタにより、GPIO 7 の割り込みを有効にしています。
323 行目は、割り込みコントローラのマスクレジスタにおいて、IRQ 29 をアンマスクしています。
296 行目の割り込みハンドラーは、ボタンが押された / 離された時に呼び出されます。
303 行目で GPIO 7 の値を読んで、1 ならば「ボタンが押された」、0 ならば「ボタンが離された」を表示します。
308 行目で、割り込み要因をクリアしています。
これがないと、延々と割り込みが上がり続け、割り込み永久ループになってしまいます。
このテストプログラムを動かして、ボタンを 1 回だけ押して離してみると、下図のようになります。
「押された」「離された」が 1 回ずつしか表示されていませんので、チャタリング除去が効いているということですね。
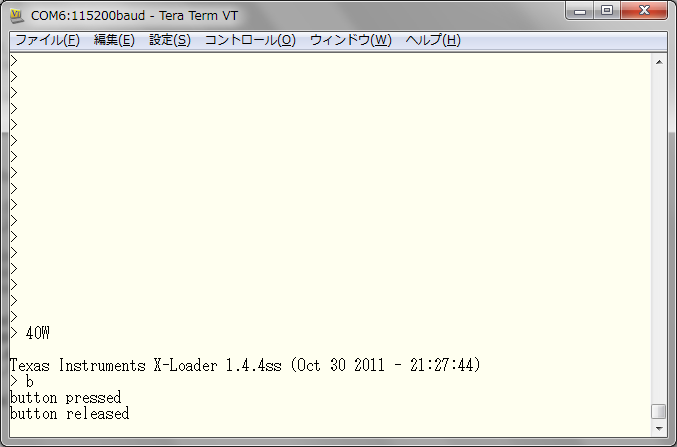
・・・
xloader が用意してくれている I2C ドライバ関数は、PIO モードで動作します。
I2C にも、UART 同様、割り込みモード、DMA モードがあるわけでして、そちらも見てみた方がいいかなあという気もしますが、扱い方は UART とほぼ同じなので、省略します。
beagleboard を触ろう - タイマーとコンテキストスイッチ [組み込みソフト]
OMAP3530 には、11 個の汎用タイマー (General Purpose Timer) が載っています。
タイマーデバイスとしては、他に 32kHz 同期タイマーが 1 個、ウォッチドッグタイマーが 2 個ついています。
ここでは、汎用タイマーを見てみます。
汎用タイマーは、入力クロックとして、SYS_CLK と 32K_CLK の 2 つから選択できます。
x-loader は、汎用タイマー 0 - 11 のすべてに対して、入力クロックが SYS_CLK となるように設定しています。
また、SYS_CLK の値は、13MHz に設定しています。
入力クロックが入ると、タイマーカウンターがインクリメントされます。
x-loader の場合は、13MHz = 1/13M 秒毎に、タイマーカウンターがインクリメントされることになります。
つまり、13M 回クロックが入ると、1 秒です。
タイマーカウンターの値は、TCRR レジスタから読み出すことができます。
汎用タイマーの使い方は、
1. タイマーカウンターの初期値を設定する
2. 周期タイマーか、ワンショットタイマーかの設定をする
3. 指定時間経ったら割り込みを上げるように、割り込み設定する
4. タイマーをスタートする
5. 割り込みを待つ
6. 指定時間経ったら、割り込みにより通知される
7. 周期タイマーならば、タイマーをストップしない限り、5 - 6 が繰り返される
というような感じです。
タイマーカウンターの初期値の設定方法は、2 通りあります。
a) TCRR レジスタに直接初期値を書き込む
b) TLDR レジスタに初期値を書込み、TTGR に任意の値を書き込む(こうすると TCRR に TLDR の値がコピーされる)
a) の方が簡単でいいじゃないかと思えますが、b) の方がいい時もあります。
汎用タイマーを周期タイマーとして使う場合は、タイマーが expire した時に、TLDR の値が自動的に TCRR にコピーされます。
なので、周期タイマーの場合は、b) の方が便利です。
割り込みを発生させるイベントとしては、オーバーフロー、コンペアマッチ、キャプチャーがあります。
オーバーフロー割り込みは、タイマーカウンターがオーバーフローした場合、つまり 0xFFFF_FFFF からインクリメントして 0x0000_0000 になった時に発生します。
コンペアマッチ割り込みは、タイマーカウンターの値が、TMAR レジスタの値と一致した場合に発生します。
キャプチャー割り込みは、使ったことがないので省略です (^^;
オーバーフロー割り込みを使用する場合、タイマーカウンターの初期値は、0xFFFF_FFFF - (expire するまでのカウント) + 1 にします。
例えば、1 ms タイマーにする場合、expire するまでのカウントは 13000 になるので、タイマーカウンターの初期値は 0xFFFF_CD37 にします。
コンペアマッチ割り込みを使用する場合は、タイマーカウンターの初期値を 0, TMAR レジスタに expire するまでのカウントを設定します。
1 ms タイマーなら、タイマーカウンターの初期値 0, TMAR レジスタの値を 13000 にすればよいです。
というよりは、(TMAR の値) - (タイマーカウンターの初期値) が 13000 になればよいです。
割り込みを発生させるには、TIER レジスタで、対応する割り込みイベントをイネーブルしてやる必要があります。
オーバーフロー割り込みを発生させるには、TIER のビット 1, コンペアマッチ割り込みを発生させるには TIER のビット 0 を立てる必要があります。
割り込みが発生すると、TISR レジスタで、対応する割り込みイベントのビットが立ちます。
TIER と同じように、オーバーフロー割り込みが発生した場合はビット 1, コンペアマッチ割り込みが発生した場合はビット 0 が立ちます。
割り込みハンドラーでは、割り込み要因をクリアするために、1 になったビットに 1 を書き込んでやる必要があります。
・・・
こんな感じで、タイマーを使うのは結構簡単です。
例えば、↓のようなコードで指定 micro sec 分だけビジーウェイトするような関数を作れます。
割り込みを使いつつもビジーウェイトするなんて、普通はなかなかないと思いますが・・・。
94: static volatile int oneshot_timer_expired[NUM_TIMER];
:
:
120: static void oneshot_timer_handler(int irq)
121: {
122: int num = irq - 36;
123:
124: __raw_writel(__raw_readl(gpt_tisr[num-1]), gpt_tisr[num-1]);
125: oneshot_timer_expired[num-1] = 1;
126: }
127:
128: void wait_us_interrupt(int num, int usec)
129: {
130: /* disable prescalar */
131: sr32(gpt_tclr[num-1], 5, 1, 0);
132:
133: /* one shot timer */
134: sr32(gpt_tclr[num-1], 1, 1, 0);
135:
136: /* set load value */
137: __raw_writel(0xFFFFFFFF - 13 * usec + 1, gpt_tldr[num-1]);
138:
139: /* load TLDR */
140: __raw_writel(1, gpt_ttgr[num-1]);
141:
142: oneshot_timer_expired[num-1] = 0;
143:
144: /* interrupt settings */
145: __raw_writel(OVF_IT_BIT, gpt_tisr[num-1]);
146: __raw_writel(OVF_IT_BIT, gpt_tier[num-1]);
147: register_handler(oneshot_timer_handler, GPT_IRQ(num));
148: intc_enable_irq(GPT_IRQ(num));
149:
150: /* start timer */
151: sr32(gpt_tclr[num-1], 0, 1, 1);
152:
153: while (!oneshot_timer_expired[num-1])
154: ;
155:
156: /* stop timer */
157: sr32(gpt_tclr[num-1], 0, 1, 0);
158: }
145 行目で TISR に OVF_IT_BIT を書き込んでいるのは、念のため割り込み要因をクリアしておくためです。
・・・
タイマー割り込みを使って、コンテキストスイッチを実現してみましょう。
まず、どんな風にしたらコンテキストスイッチができるか、考えてみます。
割り込みが発生した時、S/W によってレジスタ一式(コンテキスト)がスタックに保存されます。
元の処理に戻る場合、保存したレジスタ一式を復帰させることによって、元に戻ります。
これだと、元の処理に戻るだけですが、スタック上に保存してあるレジスタ値を書き換えてあげると、コンテキストスイッチが可能です。
保存してあるレジスタ値の中には、pc (= program counter, 命令カウンタ) も含まれています。
pc を含め、スタック上に保存してあるレジスタ値をうまく書き換えることができれば、別の処理にジャンプさせることができます。
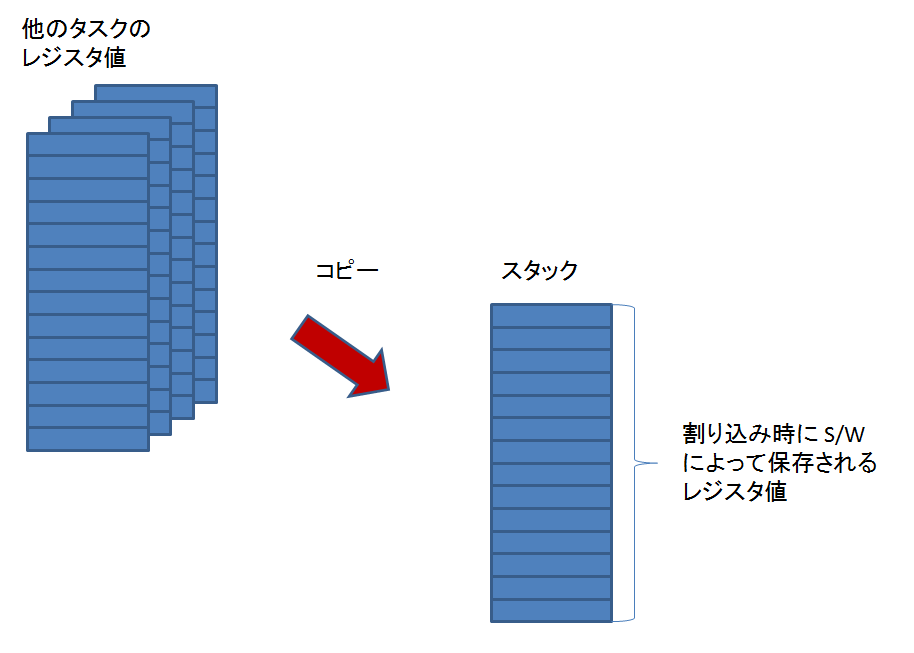
コンテキストを格納する領域をタスク数分用意しておき、タイマーハンドラーが定期的にコンテキストを交換してやれば、うまくいきそうです。
割り込み発生時には、レジスタ値を全て保存しなければなりません。
270: _do_irq:
271: #if 0
272: sub lr,lr,#4
273: str lr,[sp,#-4]!
274: mrs r14,spsr
275: stmfd sp!,{r0-r3,r12,r14}
276: bl do_irq
277: ldmfd sp!,{r0-r3,r12,r14}
278: msr spsr_csxf,r14
279: ldmfd sp!,{pc}^
280: #else
281: sub lr,lr,#4
282: str lr,[sp,#-4]!
283: mrs r14,spsr
284: stmfd sp!,{r0-r12,r14}
285: mov r0, sp
286: bl save_context
287: bl do_irq
288: bl restore_context
289: ldmfd sp!,{r0-r12,r14}
290: msr spsr_csxf,r14
291: ldmfd sp!,{pc}^
292: #endif
272 行目から 279 行目までが、今まで使っていた割り込み処理コードでしたが、これを 281 行目から 291 行目までのように変更しました。
282 行目で保存している lr は、実質 pc です。
_do_irq にジャンプしてきた時点で、Cortex-A8 は、SVC モードから IRQ モードに移行しています。
IRQ モードでの lr には、SVC モードの pc の値がコピーされています。
つまり、282 行目で保存している lr には、SVC モードの pc の値が入っています。
284 行目で保存しているのは、r0 - r12 と、SPSR の値です。
IRQ モードでの SPSR には、SVC モードの CPSR の値がコピーされています。
284 行目までに、r0 - r12, CPSR, pc が保存できましたが、sp と lr だけが保存できていません。
sp と lr は、286 行目で呼び出している save_context 関数の中で保存しています。
4: struct context {
5: unsigned long r0;
6: unsigned long r1;
7: unsigned long r2;
8: unsigned long r3;
9: unsigned long r4;
10: unsigned long r5;
11: unsigned long r6;
12: unsigned long r7;
13: unsigned long r8;
14: unsigned long r9;
15: unsigned long r10;
16: unsigned long r11;
17: unsigned long r12;
18: unsigned long spsr;
19: unsigned long pc;
20: unsigned long sp;
21: unsigned long lr;
22: };
3: static struct context *stack_pointer;
4: static struct context task_context[5];
5: static struct context *current_context = &task_context[0];
:
:
32: void save_context(struct context *sp)
33: {
34: unsigned long r13, r14;
35: unsigned long mode;
36:
37: stack_pointer = sp;
38:
39: current_context->r0 = sp->r0;
40: current_context->r1 = sp->r1;
41: current_context->r2 = sp->r2;
42: current_context->r3 = sp->r3;
43: current_context->r4 = sp->r4;
44: current_context->r5 = sp->r5;
45: current_context->r6 = sp->r6;
46: current_context->r7 = sp->r7;
47: current_context->r8 = sp->r8;
48: current_context->r9 = sp->r9;
49: current_context->r10 = sp->r10;
50: current_context->r11 = sp->r11;
51: current_context->r12 = sp->r12;
52: current_context->spsr = sp->spsr;
53: current_context->pc = sp->pc;
54:
55: mode = sp->spsr & 0x1f;
56: __asm__ volatile("mrs r0,cpsr\n\t"
57: "and r1,r0,#0x1f\n\t"
58: "bic r0,#0x1f\n\t"
59: "orr r0,r0,%2\n\t"
60: "msr cpsr,r0\n\t"
61: "mov %0,r13\n\t"
62: "mov %1,r14\n\t"
63: "bic r0,#0x1f\n\t"
64: "orr r0,r0,r1\n\t"
65: "msr cpsr,r0\n\t":"=r"(r13),"=r"(r14):"r"(mode):"r0","r1");
66: current_context->sp = r13;
67: current_context->lr = r14;
68: }
55 行目から 67 行目が、sp, lr を保存している箇所です。
SVC モードの sp, lr は、SVC モードに移行すれば取得できるので、それをやっています。
取得した sp, lr も含め、すべてのレジスタ値を current_context が指す struct context に保存しています。
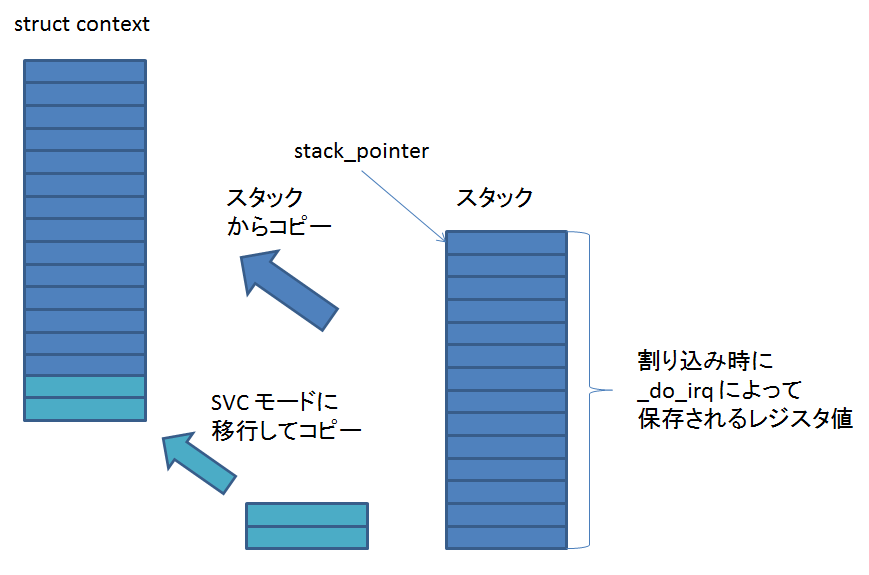
逆に、割り込み処理が終わるときは、restore_context を呼び出します。
70: void restore_context(void)
71: {
72: unsigned long mode;
73:
74: stack_pointer->r0 = current_context->r0;
75: stack_pointer->r1 = current_context->r1;
76: stack_pointer->r2 = current_context->r2;
77: stack_pointer->r3 = current_context->r3;
78: stack_pointer->r4 = current_context->r4;
79: stack_pointer->r5 = current_context->r5;
80: stack_pointer->r6 = current_context->r6;
81: stack_pointer->r7 = current_context->r7;
82: stack_pointer->r8 = current_context->r8;
83: stack_pointer->r9 = current_context->r9;
84: stack_pointer->r10 = current_context->r10;
85: stack_pointer->r11 = current_context->r11;
86: stack_pointer->r12 = current_context->r12;
87: stack_pointer->spsr = current_context->spsr;
88: stack_pointer->pc = current_context->pc;
89:
90: mode = current_context->spsr & 0x1f;
91: __asm__ volatile("mrs r0,cpsr\n\t"
92: "and r1,r0,#0x1f\n\t"
93: "bic r0,#0x1f\n\t"
94: "orr r0,r0,%2\n\t"
95: "msr cpsr,r0\n\t"
96: "mov r13,%0\n\t"
97: "mov r14,%1\n\t"
98: "bic r0,#0x1f\n\t"
99: "orr r0,r0,r1\n\t"
100: "msr cpsr,r0\n\t"::"r"(current_context->sp),"r"(current_context->lr),"r"(mode):"r0","r1");
101: }
74 行目から 88 行目までの stack_pointer は、レジスタ値が保存されているスタックのアドレスを保持しています。
スタックに保存されているレジスタ値および SVC モードの sp, lr を current_context に保持されている値で上書きしています。
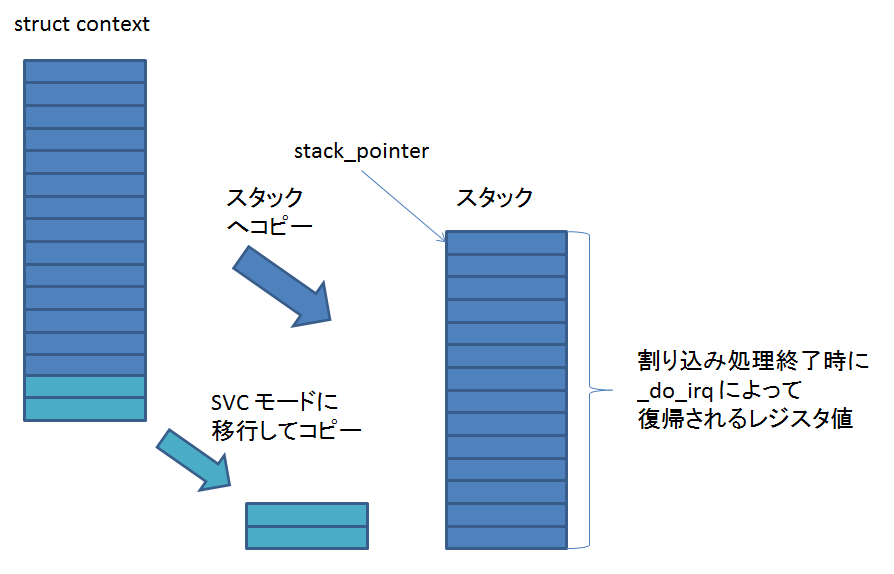
save_context で保存対象となっている current_context の実体が、restore_context で復帰対象となっている current_context と同じならば、まったく同じ値を上書きしていることになります。
しかし、save_context と restore_context の間で、current_context を別の struct context に切り替えてやれば、restore_context で、切り替えた struct context の値がスタックに上書きされることになります。
そうすると、_do_irq の最後の方、289 行目から 291 行目でスタック上のレジスタ値を復帰させるので、struct context に設定していた値が各レジスタにコピーされることになるので、新しい処理に移る、というような流れです。
288: bl restore_context
289: ldmfd sp!,{r0-r12,r14}
290: msr spsr_csxf,r14
291: ldmfd sp!,{pc}^
コンテキストの切り替えは、タイマーハンドラーが行います。
198: static void cyclic_timer_handler(int irq)
199: {
200: int num = irq - 36;
201:
202: __raw_writel(OVF_IT_BIT, gpt_tisr[num-1]);
203: serial_printf("timer_handler!\n");
204:
205: context_switch();
206: }
context_switch 関数は、これです。
4: static struct context task_context[5];
:
22: void context_switch(void)
23: {
24: static int tid = 0;
25:
26: tid++;
27: if (tid == task_num)
28: tid = 0;
29: current_context = &task_context[tid];
30: }
何のことはなく、単にぐるぐる task_context を回しているだけです (^^;
まあ、ラウンドロビンですね。
context_switch でアクセスしている task_context[] には、下の関数で登録します。
7: static int task_num = 1;
8:
9: void add_task(unsigned long pc, unsigned long sp)
10: {
11: task_context[task_num].pc = pc;
12: task_context[task_num].sp = sp;
13: task_context[task_num].spsr = 0x153;
14: task_num++;
15: }
それではテストプログラムです。
179: static void task_test1(void)
180: {
181: while (1) {
182: wait_us_interrupt(3, 1000000);
183: serial_printf("%s\n", __FUNCTION__);
184: }
185: }
186:
187: static void task_test2(void)
188: {
189: while (1) {
190: wait_us_interrupt(4, 1000000);
191: serial_printf("%s\n", __FUNCTION__);
192: }
193: }
194:
195: static int timer_test(void)
196: {
197: serial_ch = 0;
198:
199: add_task((unsigned long)task_test1, (unsigned long)0x80000400);
200: add_task((unsigned long)task_test2, (unsigned long)0x80000800);
201:
202: intc_enable_irq(UART3_IRQ);
203: start_timer(1, 3000000);
204: while (1) {
205: if (serial_ch == 'q')
206: break;
207: wait_us_interrupt(2, 1000000);
208: serial_printf("%s\n", __FUNCTION__);
209: }
210: stop_timer(1);
211: intc_disable_irq(UART3_IRQ);
212:
213: delete_all_tasks();
214:
215: return 0;
216: }
199 行目、200 行目で task_context に登録します。
199 行目が task_context[1], 200 行目が task_context[2] への登録になります。
add_task の第 2 引数はスタックのアドレスですが、199 行目、200 行目では、SDRAM の先頭付近を指定しています。
x-loader は内臓 SRAM だけで動作するので、SDRAM はすべて空いている状態ですので、どこを使っても大丈夫です。
203 行目で、3 秒周期の周期タイマーをスタートしています。
これにより、3 秒ごとに、先ほどの cyclic_timer_handler 関数が呼び出されます。
timer_test 関数は、タイマーをスタートした後、1 秒おきに "timer_test" をシリアルコンソールに出し続けます。
そして、3 秒後にタイマー割り込みが発生します。
この時に何が起こるかというと・・・
cyclic_timer_handler の中で context_switch が呼び出され、current_context のポイント先が 199 行目で登録した task_context[1] に切り替わります。
cyclic_timer_handler の処理が終了すると、_do_irq の 288 行目が実行され、スタック上のレジスタ値および SVC モードの sp, lr を上書きしていきます。
288: bl restore_context
289: ldmfd sp!,{r0-r12,r14}
290: msr spsr_csxf,r14
291: ldmfd sp!,{pc}^
288 行目で、スタック上のレジスタ値および SVC モードの sp, lr は、↓のようになります。
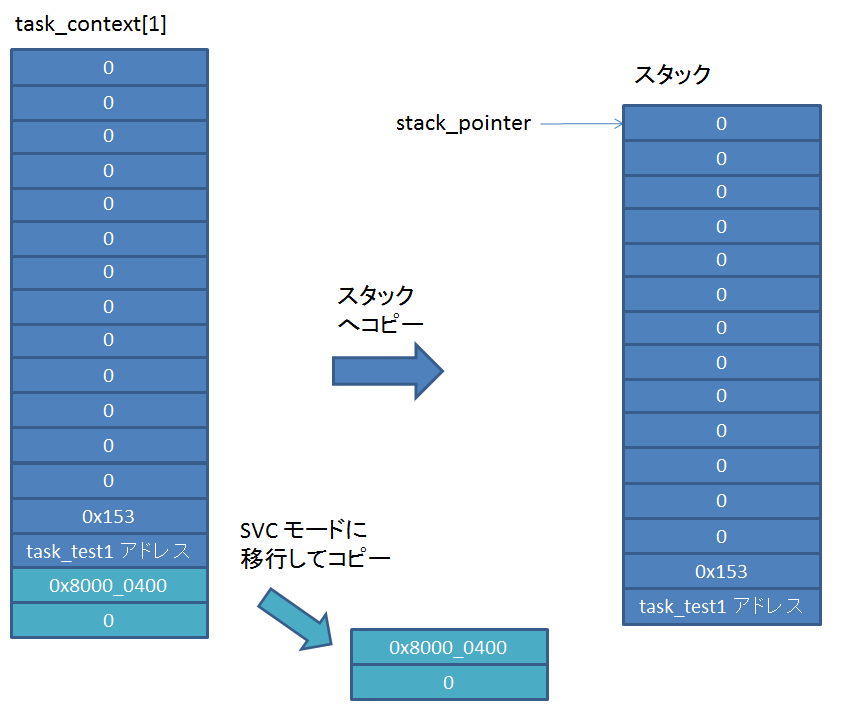
pc は task_test1 のアドレスを指し、sp は 0x8000_0400 を指しています。
spsr の値 0x153 は、SVC モードを表します。
291 行目が実行された時に、SVC モードに移行し、命令ポインタ (pc) は task_test1 のアドレスを指すようになります。
つまり、task_test1 がこれから SVC モードで実行される状態になったわけです。
タイマー割り込みが発生する前は timer_test が実行されていたのに、割り込み処理が終わった後は、task_test1 に処理が移ったわけですね。
つまり、タイマー割り込みでコンテキストスイッチが発生、なわけです。
次の 3 秒後にも同じことが行われます。
次は、task_test2 の番ですね。
その次の 3 秒後は、timer_test に戻ります。
戻る場所は、前回 timer_test が中断したところです。
前回 task_test1 に実行権が移った時、task_context[0] に、その情報がすべて保存されたわけですから。
その次の 3 秒後は、task_test1 に戻ります。
戻る場所は、前回 task_test1 が中断したところです。
task_context[1] に、その情報がすべて保存されているので・・・。
という感じで続きます。
実行結果は、こんな感じです。
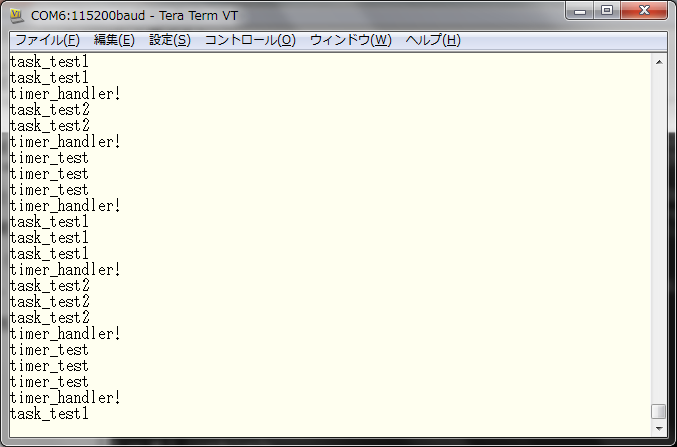
・・・
例としては相変わらずしょうもないですが、タスクってこんなものなのか、って実感が湧きませんか?
実際の OS のコンテキストスイッチも、こんな感じです (^-^)
前の10件 | -
beagle さん

-
nice! 5
記事 23
テーマ パソコン・インターネット
プロフィール
ブログを紹介する


