beagleboard を触ろう - NAND ECC [組み込みソフト]
NAND フラッシュメモリは、ビット化けが起こり得るデバイスであり、ECC (Error Correction Code / Error Checking and Correction) を使って補っています。
ECC は、ユーザーデータに ECC データを付加することによって、誤り訂正を行えるようにした仕組みです。
ECC は、1 ビットの誤りならば、訂正が可能です。
2 ビットの誤りならば、訂正はできませんが、誤りが発生したことは検出できます。
3 ビット以上の誤りがあれば、結果はまちまちです。
間違った判断に基づき、誤り訂正したり、誤りがなかったと判断したりするかもしれません。
ECC データは、ユーザーデータ 2^N ビットに対し、2*N ビット必要です。
例えば、ユーザーデータが 8 ビットならば、N = 3 なので、ECC データは 6 ビット必要です。
ユーザーデータが 2048 ビットならば N = 11 なので、ECC データは 22 ビット必要です。
8 ビットと 2048 ビットを比較すると、ECC データの割合が、2048 ビットの方が少ないため、効率的に思えてしまいますが、その分誤り訂正能力が落ちます。
[ユーザーデータ、ECC データ] = [8 ビット、6 ビット] の場合は、8 ビット中 1 ビットの誤りがあった場合に、訂正できます。
[ユーザーデータ、ECC データ] = [2048 ビット、22 ビット] の場合は、2048 ビット中 1 ビットの誤りしか訂正できません。
beagleboard 搭載の NAND フラッシュメモリ MT29F2G16ABDHC-ET は、1 ページのサイズは 2112 バイトです。
この 1 ページを、ユーザーデータとして 2048 バイトを使い、残りを ECC データ(最大 64 バイト)として使います。
xloader の ECC コードは、2048 バイトを 8 分割して 256 バイトずつのデータとして、それぞれに対して ECC データを付加する方法を取っています。
256 バイト = 2048 ビットなので、ECC データのサイズは 22 ビット です。
22 ビットが収まるように、3 バイトを 1 つの ECC データとして割り当てています。
ECC データは 8 個分あるので、合計サイズは 24 バイトですね。
イメージ的に図示すると、こんな感じです↓
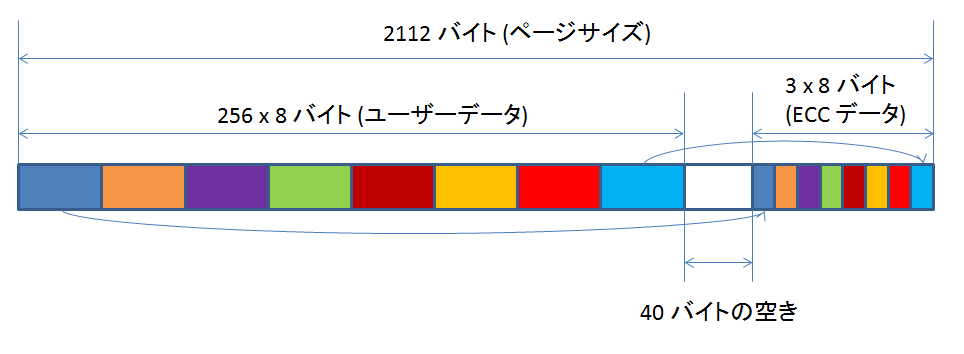
ECC データを格納できる領域は 64 バイトあるので、もう少し精度の高い ECC データを格納することも可能です。
128 バイトごとに ECC を付加するとすれば、必要な ECC の個数は 16 個、1 つあたりの ECC サイズは 20 ビット、これを 3 バイトに収めるとして、3 x 16 = 48 バイトで、64 バイトに収まりますね。
NAND ECC は、256 バイト単位というのがスタンダードなのかどうか、すみません、よく分かっていません。
ウェブで見つけたサムスンの NAND ECC の説明資料も、256 バイト単位になっていました。
ECC データ生成方法のベースになっているのは、パリティです。
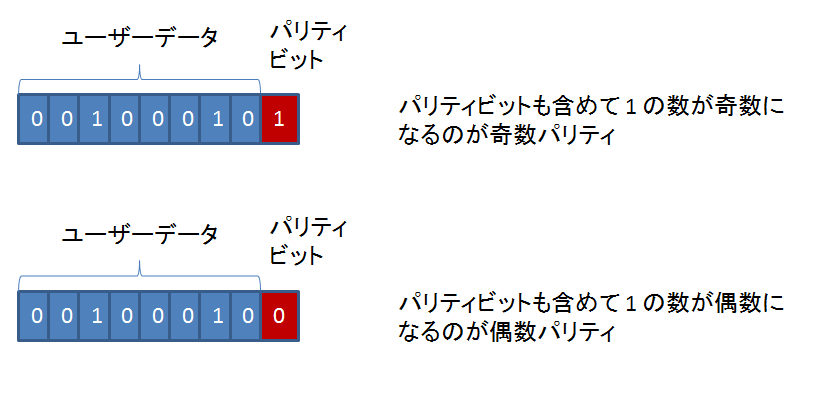
偶数パリティであれ、奇数パリティであれ、1 ビット誤りがあった場合、誤りがあったことは分かっても、どのビットで誤りがあったかは分かりませんよね。
ECC は、パリティを巧みに組み合わせて、どこに誤りがあるかを分かるようにした、非常に賢いアルゴリズムを使っています。
NAND ECC は、奇数パリティをベースにしています。
奇数パリティだと、ユーザーデータがオール 0xff の場合、ECC データもオール 0xff になります。
これ、ブロック消去によりデータが 0xff になったときのことを考えると、都合がいいですよね。
偶数パリティなら、消去した後に ECC データ領域を 0x00 で上書きしないといけないですから。
それでは、ECC の生成方法と誤り訂正方法の説明です。
(NAND ECC と同じく、奇数パリティを使用します。)
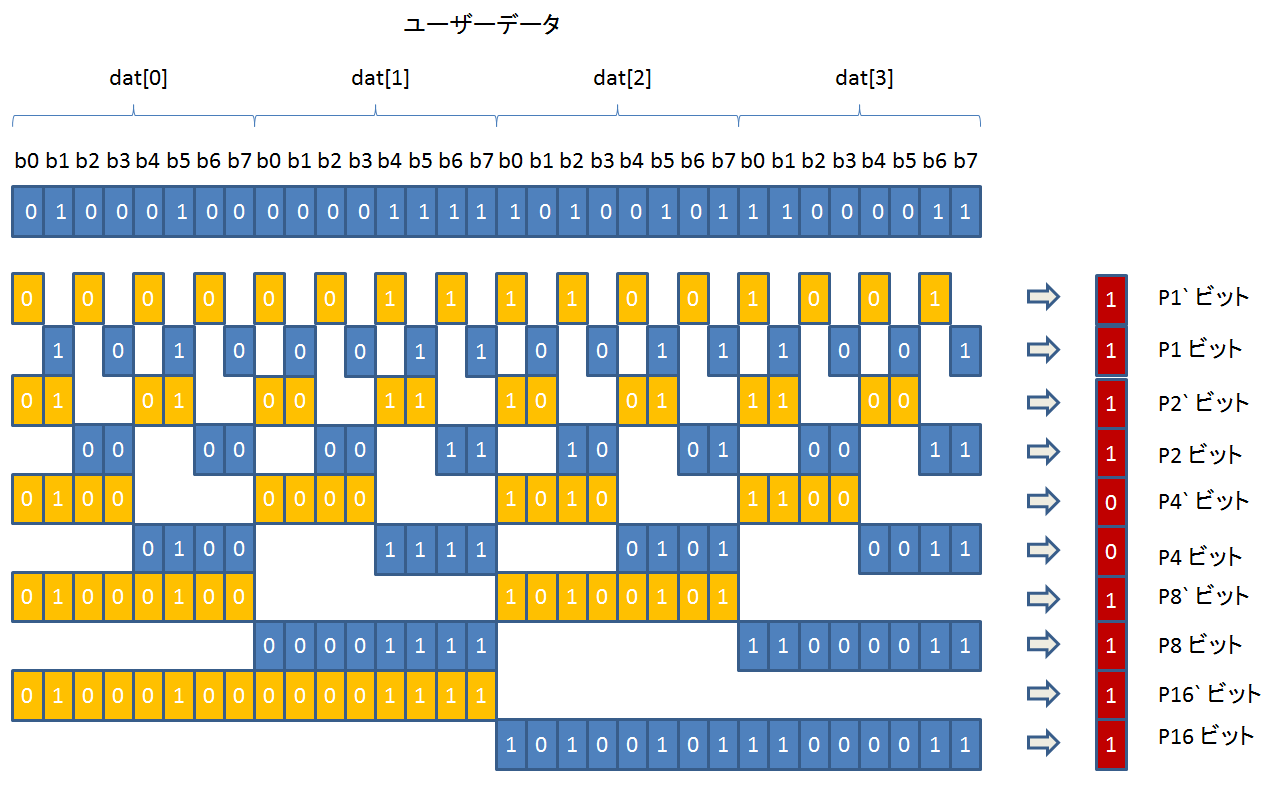
簡単のため、8 ビットデータに対して、6 ビットの ECC データを生成する場合を見てみます。
以下の図のように、6 ビットの ECC データの各ビットは、8 ビットデータのうち 4 ビットを使って、奇数パリティを生成します。
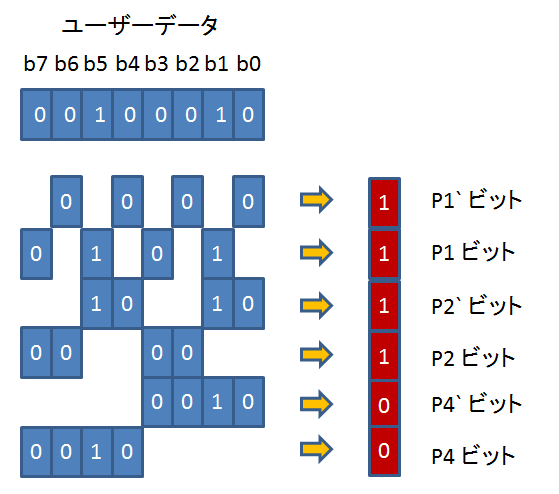
上図のように 8 ビットデータが 0b00100010 だとすると、ECC データは 0b001111 となります。
奇数パリティの計算は、以下のように、XOR と NOT のみで出来ます。
Pi = ~(bw ^ bx ^ by ^ bz)
※例えば、P1 = ~(b7 ^ b5 ^ b3 ^ b1)
b7 - b0 から影響を受ける ECC ビットは、以下の表のようになります。
影響を受けるというのは、そのビットを元にして ECC が計算されている、という意味に取ってください。
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
| P4` | P4` | P4` | P4` | ||||
| P2` | P2` | P2` | P2` | ||||
| P1` | P1` | P1` | P1` | ||||
| P4 | P4 | P4 | P4 | ||||
| P2 | P2 | P2 | P2 | ||||
| P1 | P1 | P1 | P1 |
各列、1, 2, 4 が 1 つずつ揃っていますね。
(Pi と Pi` は違うビットからパリティを生成するので当たり前なのですが。)
よくよく見ると、
a. 影響を受ける P のビット番号の合計 = データのビット番号
b. 影響を受ける P` のビット番号の合計 = データのビット番号の反転
という関係があります。
例えば、b5 を例にとってみると、
a-左辺 影響を受ける P のビット番号の合計 = 5
a-右辺 データのビット番号 = 5
b-左辺 影響を受ける P` のビット番号の合計 = 2
b-右辺 データのビット番号の反転 = ~5 = ~0b101 = 0b010 = 2
となっています。
8 ビットデータの ECC データの生成は、こんな感じで P4, P4`, P2, P2`, P1, P1` から生成します。
ユーザーデータ数が大きくなったら、それに合わせて P/P` が増えていきます。
16 ビットデータならば、P8/P8` を、32 ビットデータならば P8/P8` と P16/P16` を追加すればいいわけですね。
32 ビットデータの場合、Pi/Pi` は、以下のビットを使って計算します。
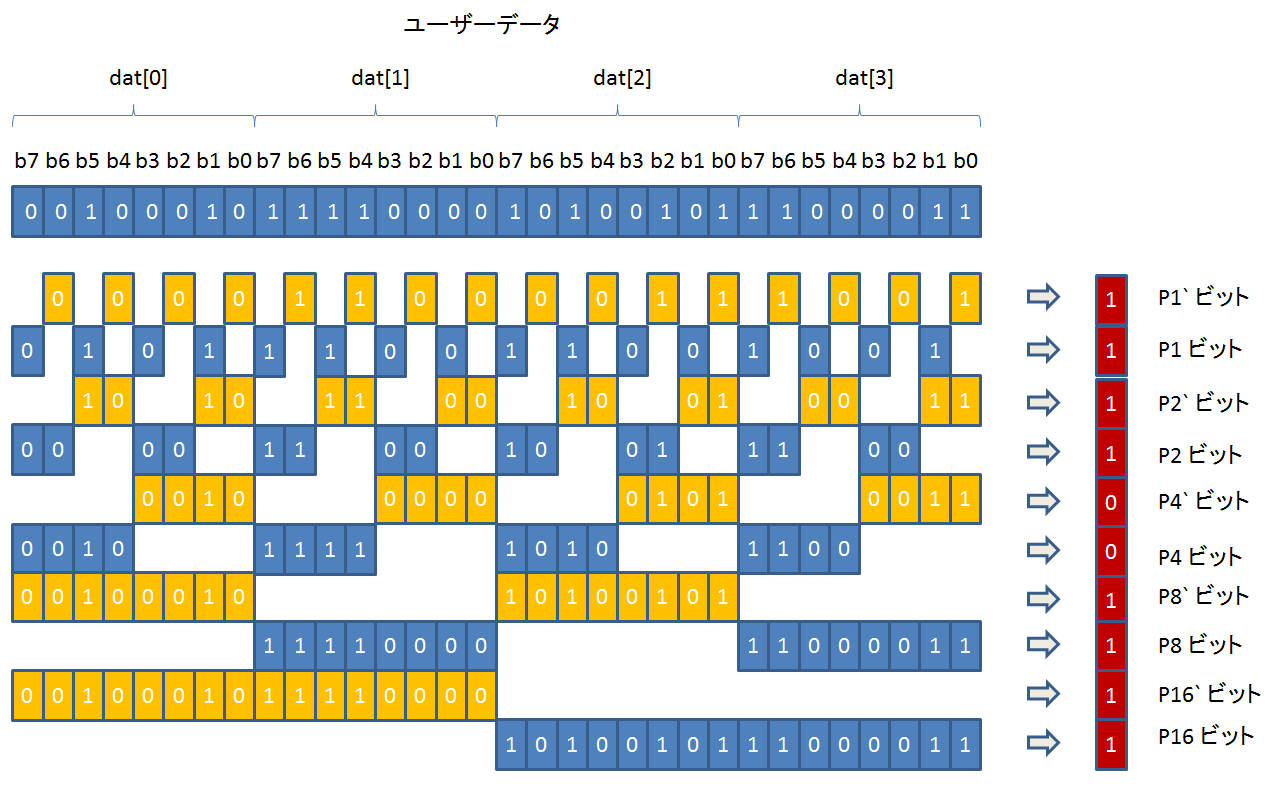
P1/P1`, P2/P2`, P4/P4' に適用されているルールと、P8/P8`, P16/P16` に適用されているルールが異なるように見えませんか?
P4/P4` までは P が一番左にあるのに、P8/P8` 以降は P` が一番左にあります。
これは、配列インデックスは左側が 0 なのに、ビット番号は右側が 0 になっていて、逆順になっているので、そう見えるだけです。
ビット番号を左側が 0 になるように書き換えると、自然に見えます。
さて、それでは ECC データを使って、どうやってエラー訂正するのでしょうか。
先ほどと同じく、8 ビットデータを例に取ります。
具体的に 0b00100010 の場合を見てみましょう。
ECC データは、0b001111 です。
読み出したユーザーデータが 1 ビット反転し、ECC ビットは正しかったとしましょう。
仮に b4 ビットが反転したとします。
この場合、ユーザーデータは 0b00110010 になります。
このユーザーデータから計算して得られる ECC ビットは、0b101010 になります。
一方、読み出し ECC データは 0b001111 です。
計算 ECC データ 0b101010 と読み出し ECC データ 0b001111 を比較すると、ビット 5 (P4), ビット 2 (P2`), ビット 0 (P1`) の計 3 ビットが異なっていることが分かります。
これは、何を意味しているでしょうか。
再度、データビットと ECC ビットの関連表を見てください。
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
| P4` | P4` | P4` | P4` | ||||
| P2` | P2` | P2` | P2` | ||||
| P1` | P1` | P1` | P1` | ||||
| P4 | P4 | P4 | P4 | ||||
| P2 | P2 | P2 | P2 | ||||
| P1 | P1 | P1 | P1 |
b4 が反転すると、P4, P2`, P1` が本来の値から反転します。
それ以外のビット、P4`, P2, P1 は b4 ビットの影響を受けず、計算 ECC ビットと読み出し ECC ビットは一致します。
P4, P2`, P1` のみが異なるパターンは、上の表と照らし合わせると b4 しかないことが分かりますので、b4 が反転したケースであることが特定できます。
ここまで特定できれば、b4 を反転させると、正しい値が得られるということが分かります。
ということで、正しく訂正できます。
今度は、読み出したユーザーデータは正しく、ECC データが 1 ビット反転したケースを考えてみましょう。
先ほどと同じく、0b00100010 の場合を考えます。
再度持ち出すまでもありませんが、ECC データは 0b001111 です。
仮に P1 が反転したとします。
読み出し ECC データは 0b001101 になります。
ユーザーデータは正しいので、計算 ECC は 0b001111 で変わりません。
そうすると、計算 ECC と、読み出し ECC は、ビット 1 (P1) だけが異なることになります。
このケースは、そのものずばり P1 のみが反転して誤っていたということになります。
P1 を反転させれば、正しい値になります(ユーザーデータが化けていたわけではないので、直す必要もありませんが)。
この場合も、正しく訂正できます。
以上のように、ユーザーデータ + ECC データのうち、1 ビットだけ反転したケースは、正しく訂正できます。
2 ビット反転した場合は、誤りがあることだけは検出できますが、訂正はできません。
3 ビット以上反転した場合は、誤りがあることを確実に検出することはできません。
誤りがあったことを検出するか、誤った判断で誤りなしと判断するか、誤った判断でエラー訂正するか、ビットの化け方次第です。
先に、NAND ECC は、ECC データ 22 ビットを 3 バイトに収めていると説明しましたが、xloader の場合、そのフォーマットは以下の図のようになっています。
最後の 2 ビットは、1 固定です。
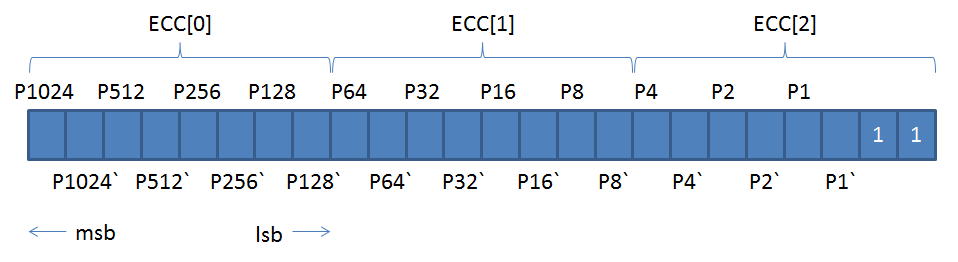
これが、スタンダードなのかどうか分かりませんが・・・。
ECC データ全体は合計で 24 バイトになりますが、この 24 バイトは、xloader では 1 ページの一番最後に配置しています。
再度、先ほどの図です。
これもスタンダードなのか、そうでないのか、不明です・・・。
これで、とりあえず ECC の説明はおしまいです。
・・・
xloader の ECC を扱うコードを見てみましょう。
やってることは上の説明の通りなのですが、これが難解で・・・
データから ECC を生成するコード、ECC によりデータを訂正するコードの両方があります。
まず ECC を生成するコードから見てみましょう。
28: /*
29: * Pre-calculated 256-way 1 byte column parity
30: */
31: static const u_char nand_ecc_precalc_table[] = {
32: 0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, ...
33: 0x65, 0x30, 0x33, 0x66, 0x3c, 0x69, ...
34: 0x66, 0x33, 0x30, 0x65, 0x3f, 0x6a, ...
35: 0x03, 0x56, 0x55, 0x00, 0x5a, 0x0f, ...
36: 0x69, 0x3c, 0x3f, 0x6a, 0x30, 0x65, ...
37: 0x0c, 0x59, 0x5a, 0x0f, 0x55, 0x00, ...
38: 0x0f, 0x5a, 0x59, 0x0c, 0x56, 0x03, ...
39: 0x6a, 0x3f, 0x3c, 0x69, 0x33, 0x66, ...
40: 0x6a, 0x3f, 0x3c, 0x69, 0x33, 0x66, ...
41: 0x0f, 0x5a, 0x59, 0x0c, 0x56, 0x03, ...
42: 0x0c, 0x59, 0x5a, 0x0f, 0x55, 0x00, ...
43: 0x69, 0x3c, 0x3f, 0x6a, 0x30, 0x65, ...
44: 0x03, 0x56, 0x55, 0x00, 0x5a, 0x0f, ...
45: 0x66, 0x33, 0x30, 0x65, 0x3f, 0x6a, ...
46: 0x65, 0x30, 0x33, 0x66, 0x3c, 0x69, ...
47: 0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, ...
48: };
49:
50:
51: /*
52: * Creates non-inverted ECC code from line parity
53: */
54: static void nand_trans_result(u_char reg2, u_char reg3,
55: u_char *ecc_code)
56: {
57: u_char a, b, i, tmp1, tmp2;
58:
59: /* Initialize variables */
60: a = b = 0x80;
61: tmp1 = tmp2 = 0;
62:
63: /* Calculate first ECC byte */
64: for (i = 0; i < 4; i++) {
65: if (reg3 & a) /* LP15,13,11,9 --> ecc_code[0] */
66: tmp1 |= b;
67: b >>= 1;
68: if (reg2 & a) /* LP14,12,10,8 --> ecc_code[0] */
69: tmp1 |= b;
70: b >>= 1;
71: a >>= 1;
72: }
73:
74: /* Calculate second ECC byte */
75: b = 0x80;
76: for (i = 0; i < 4; i++) {
77: if (reg3 & a) /* LP7,5,3,1 --> ecc_code[1] */
78: tmp2 |= b;
79: b >>= 1;
80: if (reg2 & a) /* LP6,4,2,0 --> ecc_code[1] */
81: tmp2 |= b;
82: b >>= 1;
83: a >>= 1;
84: }
85:
86: /* Store two of the ECC bytes */
87: ecc_code[0] = tmp1;
88: ecc_code[1] = tmp2;
89: }
:
130: void nand_calculate_ecc (const u_char *dat, u_char *ecc_code)
131: {
132: u_char idx, reg1, reg2, reg3;
133: int j;
134:
135: /* Initialize variables */
136: reg1 = reg2 = reg3 = 0;
137: ecc_code[0] = ecc_code[1] = ecc_code[2] = 0;
138:
139: /* Build up column parity */
140: for(j = 0; j < 256; j++) {
141:
142: /* Get CP0 - CP5 from table */
143: idx = nand_ecc_precalc_table[dat[j]];
144: reg1 ^= (idx & 0x3f);
145:
146: /* All bit XOR = 1 ? */
147: if (idx & 0x40) {
148: reg3 ^= (u_char) j;
149: reg2 ^= ~((u_char) j);
150: }
151: }
152:
153: /* Create non-inverted ECC code from line parity */
154: nand_trans_result(reg2, reg3, ecc_code);
155:
156: /* Calculate final ECC code */
157: ecc_code[0] = ~ecc_code[0];
158: ecc_code[1] = ~ecc_code[1];
159: ecc_code[2] = ((~reg1) << 2) | 0x03;
160: }
31 行目に、nand_ecc_precalc_table[] 配列が宣言されています。
この配列には、0 - 255 までの 1 バイト値に対して、以下の図のようなビットパターンで XOR を取ったものが格納されています。
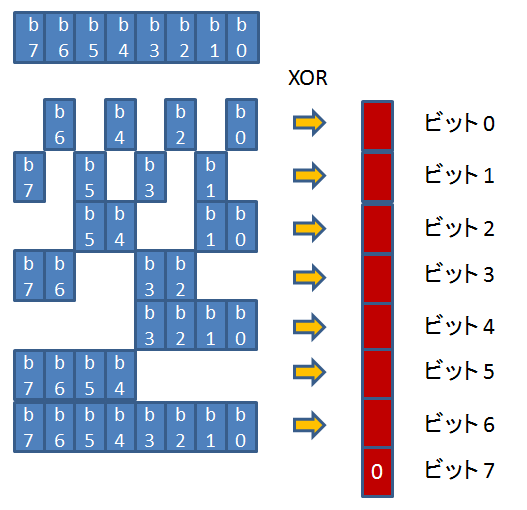
値 i に対して、上記のビットパターンで XOR を取ったものが nand_ecc_precalc_table[i] になっているわけです。
nand_ecc_precalc_table[i] の各ビットは、次のような意味を持ちます。
ビット 0: 値 i から計算した P1` (ただし奇数パリティではなく偶数パリティ、以下同じ)
ビット 1: 値 i から計算した P1
ビット 2: 値 i から計算した P2`
ビット 3: 値 i から計算した P2
ビット 4: 値 i から計算した P4`
ビット 5: 値 i から計算した P4
ビット 6: 値 i のすべてのビットで XOR を取った値
ビット 7: 常に 0
※P4 - P1` の意味が分からなくなってしまったら、ここを再度見てください。
次に、130 行目からの nand_calculate_ecc() 関数を見ていきましょう。
ローカル変数 reg1, reg2, reg3 は、以下のパリティ値を計算するために使用されます:
reg1: P4, P4`, P2, P2`, P1, P1`
reg2: P1024`, P512`, P256`, P128`, P64`, P32`, P16`, P8`
reg3: P1024, P512, P256, P128, P64, P32, P16, P8
139: /* Build up column parity */
140: for(j = 0; j < 256; j++) {
141:
142: /* Get CP0 - CP5 from table */
143: idx = nand_ecc_precalc_table[dat[j]];
144: reg1 ^= (idx & 0x3f);
140 行目は、256 バイトのユーザーデータを、1 バイトずつループを回す、の意です。
143 行目, 144 行目で、nand_ecc_precalc_table[dat[j]] の下位 6 ビットを取得し、その値と reg1 とで XOR を取っています。
idx の下位 6 ビットには、dat[j] から計算した P4, P4`, P2, P2`, P1, P1` の値が入ります。
reg1 には、0 から j - 1 番目までのデータで計算した P4, P4`, P2, P2`, P1, P1` が入っています。
この reg1 に、j 番目のデータの P4, P4`, P2, P2`, P1, P1` を XOR してあげれば、0 から j 番目までのデータで計算した P4, P4`, P2, P2`, P1, P1` が得られます。
これを 256 回ループで回せば、0 から 255 番目までのデータで計算した P4, P4`, P2, P2`, P1, P1` が得られます。
これで P4 - P1` は OK です。
P8/P8` 以降は、ECC を計算するビットが、8 ビット以上の長さで連続しています。
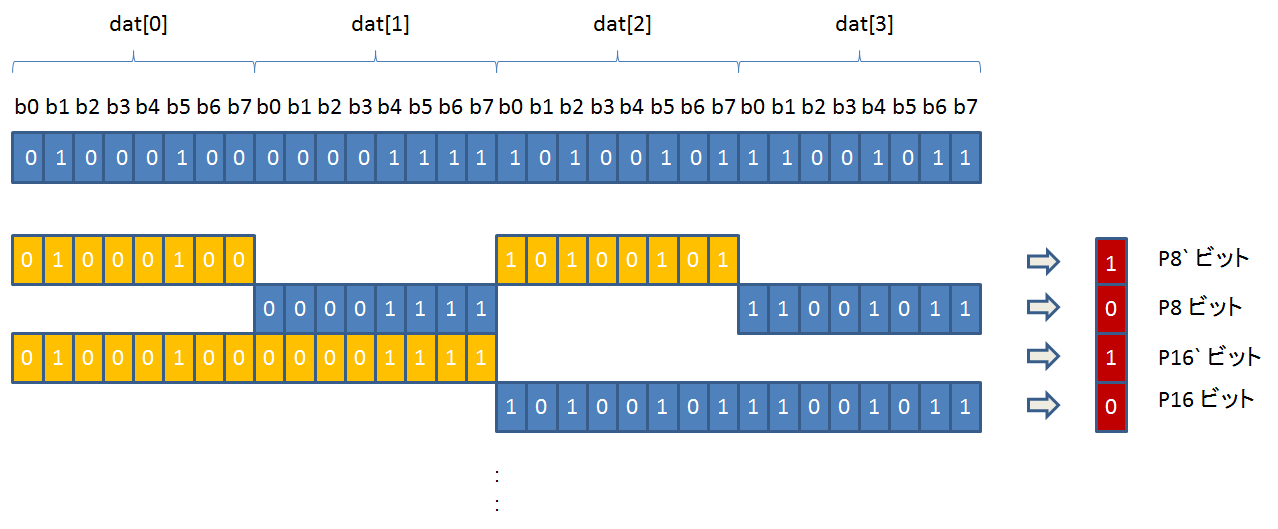
そのため、P8/P8` 以降は、バイト単位の XOR 値を用いて計算できます。
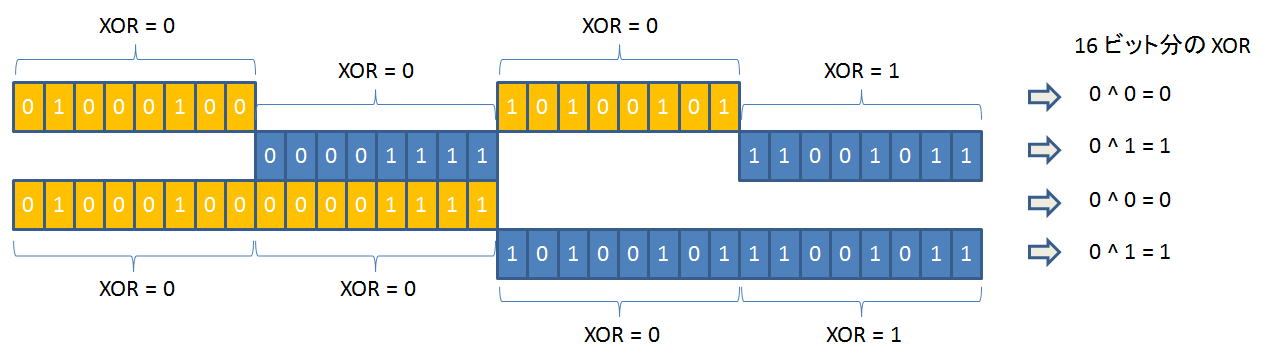
※↑の図と、その一つ上の図では、得られるビットの値が逆になっています。これは、XOR で得られる値は偶数パリティであるが、最終的な ECC ビットは奇数パリティなので、逆になっていると理解してください。
コードでは、P8/P8` 以降は、reg3, reg2 を使って計算します。
139: /* Build up column parity */
140: for(j = 0; j < 256; j++) {
141:
142: /* Get CP0 - CP5 from table */
143: idx = nand_ecc_precalc_table[dat[j]];
144: reg1 ^= (idx & 0x3f);
145:
146: /* All bit XOR = 1 ? */
147: if (idx & 0x40) {
148: reg3 ^= (u_char) j;
149: reg2 ^= ~((u_char) j);
150: }
151: }
idx のビット 6 は、値 dat[j] のすべてのビットで XOR を取った値が入っていることに注意してください。
147 行目の条件文は、「dat[j] のすべてのビットで XOR を取った値が 1」ならば、真になります。
XOR 計算は、0 と XOR を取る場合は値が変わらないので、計算する必要がありません。
1 と XOR を取る場合は値が変わるので、その場合は、P8/P8` 以降に反映させます。
その判定をしているのが、147 行目ということになります。
dat[j] の XOR 値が 1 だった場合、P8/P8` - P1024/P1024` までのうち、どの ECC ビットに反映させるかが問題となります。
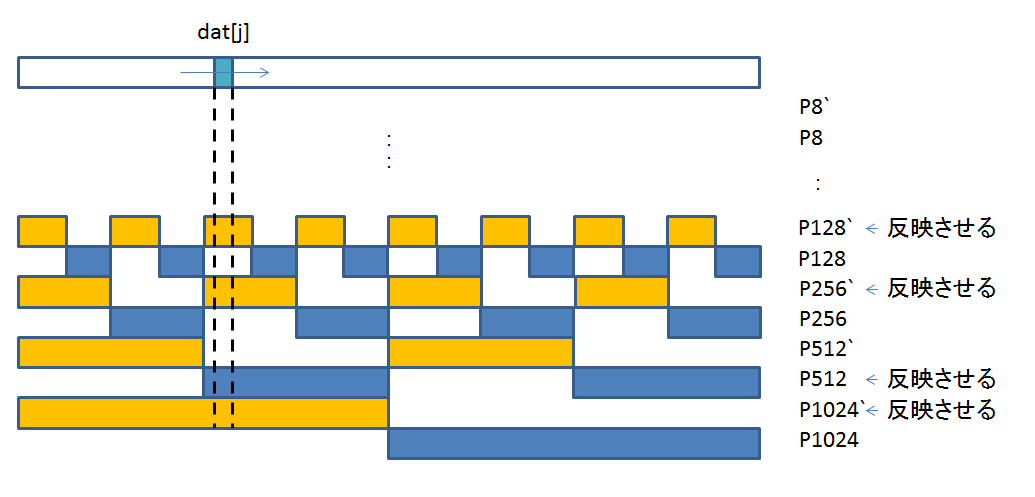
DATA ビットと ECC ビットの関連表をもう一度見てください。
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
| P4` | P4` | P4` | P4` | ||||
| P2` | P2` | P2` | P2` | ||||
| P1` | P1` | P1` | P1` | ||||
| P4 | P4 | P4 | P4 | ||||
| P2 | P2 | P2 | P2 | ||||
| P1 | P1 | P1 | P1 |
これは、b7 - b0 が影響を与える ECC ビットを表す表でした。
この表に関して、
a. 影響を受ける P のビット番号の合計 = データのビット番号
b. 影響を受ける P` のビット番号の合計 = データのビット番号の反転
という法則があるのでした。
これと類似した法則が、dat と P8/P8` - P1024/P1024` との間にも成り立ちます。
簡単にするために、ユーザーデータを 256 バイトの代わりに 8 バイトデータで考えます。
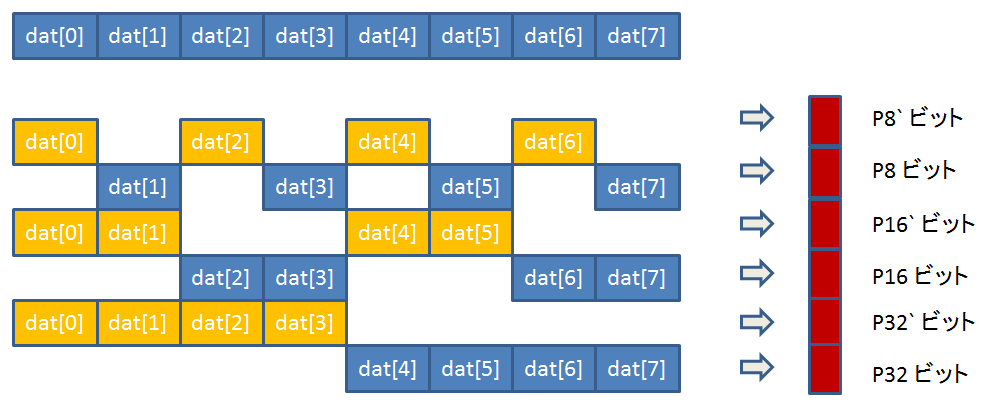
dat が P8, P8`, P16, P16`, P32, P32` のどれに影響を与えるかという関連表を書くと、以下のようになります。
| dat[0] | dat[1] | dat[2] | dat[3] | dat[4] | dat[5] | dat[6] | dat[7] |
| P32 | P32 | P32 | P32 | ||||
| P16 | P16 | P16 | P16 | ||||
| P8 | P8 | P8 | P8 | ||||
| P32` | P32` | P32` | P32` | ||||
| P16` | P16` | P16` | P16` | ||||
| P8` | P8` | P8` | P8` |
今度は、↓のような関係があります。
A. 影響を受ける P のビット番号の合計 = (dat のインデックス) * 8
B. 影響を受ける P` のビット番号の合計 = (dat のインデックスの反転) * 8
(ここでもう一度、影響を受けるというのは、そのデータを元にして ECC が計算されている、という意味に取ってください。)
例えば、dat[2] で試してみると、
A-左辺 影響を受ける P のビット番号の合計 = 16
A-右辺 (dat のインデックス) * 8 = 16
B-左辺 影響を受ける P` のビット番号の合計 = 40
B-右辺 (dat のインデックスの反転) * 8 = ~2 * 8 = ~0b010 * 8 = 0b101 * 8 = 5 * 8 = 40
となって、合ってますね。
・・・というわけで、この法則を使って P8/P8` 以降を計算しているのが 148, 149 行目です。
148: reg3 ^= (u_char) j;
149: reg2 ^= ~((u_char) j);
reg3 の各ビットは、以下のように使われます。
ビット 7: P1024 用
ビット 6: P512 用
ビット 5: P256 用
ビット 4: P128 用
ビット 3: P64 用
ビット 2: P32 用
ビット 1: P16 用
ビット 0: P8 用
同じように、reg2 の各ビットは、以下のように使われます。
ビット 7: P1024` 用
ビット 6: P512` 用
ビット 5: P256` 用
ビット 4: P128` 用
ビット 3: P64` 用
ビット 2: P32` 用
ビット 1: P16` 用
ビット 0: P8` 用
それで、改めて 148, 149 行目を見ると、reg3 は P 用なので、反転せずにそのまま dat のインデックスを使い、reg2 は P` 用なので、反転した dat のインデックスを使っています。
具体的に、j = 2 の場合を見てみましょう。
reg3 には、dat[0], dat[1] から計算された Pi の値が入っています。
reg2 には、同じく dat[0], dat[1] から計算された Pi` の値が入っています。
dat[2] のビットのうち、ECC 計算に使うビットは、
・P16
・P8`, P32`, P64`, P128`, P256`, P512`, P1024` (16 以外全部)
です。
これはつまり、dat[2] の全ビットの XOR 値が 1 ならば (if (idx & 0x40))、 P16 と、P16` 以外のすべての Pi` を、反転させる必要があることを意味します。
reg3 と XOR を取る (u_char) j は、j = 2 の場合は、P16 用のビットだけが立っていることを示す値です。
reg3 には dat[0], dat[1] から計算された Pi の値が入っていますが、(u_char) j (j = 2) との XOR を取った結果、P16 だけが反転します。
P16 以外の Pi は変化しません。
0 との XOR 計算は、元の値を変えませんので。
この結果、dat[0], dat[1], および dat[2] から計算された Pi の値が得られたことになります。
これを 256 回まで繰り返せば、dat[0] から dat[255] までの値から計算された Pi の値が得られます。
reg2 も同様です。
reg2 と XOR を取る (u_char) ~j は、j = 2 の場合は、P16` 用のビットだけが落ち、それ以外のビットはすべて立っていることを示す値です。
reg2 には dat[0], dat[1] から計算された Pi` の値が入っていますが、(u_char)~j (j = 2) との XOR を取った結果、P16` 以外のすべてのビットが反転します。
P16` のビットだけは反転しません。
この結果、dat[0], dat[1], および dat[2] から計算された Pi` の値が得られたことになります。
これを 256 回まで繰り返せば、dat[0] から dat[255] までの値から計算された Pi` の値が得られます。
うーん、すごくよくできていますねー。
・・・ということで、for ループを抜けると、reg1, reg2, reg3 は、以下のようになります:
reg1:
ビット 7: 0
ビット 6: 0
ビット 5: 256 バイトデータで計算された P4 (ただし奇数パリティではなく偶数パリティ、以下同じ)
ビット 4: 256 バイトデータで計算された P4`
ビット 3: 256 バイトデータで計算された P2
ビット 2: 256 バイトデータで計算された P2`
ビット 1: 256 バイトデータで計算された P1
ビット 0: 256 バイトデータで計算された P1`
reg2:
ビット 7: 256 バイトデータで計算された P1024`
ビット 6: 256 バイトデータで計算された P512`
ビット 5: 256 バイトデータで計算された P256`
ビット 4: 256 バイトデータで計算された P128`
ビット 3: 256 バイトデータで計算された P64`
ビット 2: 256 バイトデータで計算された P32`
ビット 1: 256 バイトデータで計算された P16`
ビット 0: 256 バイトデータで計算された P8`
reg3:
ビット 7: 256 バイトデータで計算された P1024
ビット 6: 256 バイトデータで計算された P512
ビット 5: 256 バイトデータで計算された P256
ビット 4: 256 バイトデータで計算された P128
ビット 3: 256 バイトデータで計算された P64
ビット 2: 256 バイトデータで計算された P32
ビット 1: 256 バイトデータで計算された P16
ビット 0: 256 バイトデータで計算された P8
154 行目で nand_trans_result() 関数を呼び出し、reg2 と reg3 から、[P1024, P1024`, P512, P512`, P256, P256`, P128, P128`] および [P64, P64`, P32, P32`, P16, P16`, P8, P8`] を作ります。
153: /* Create non-inverted ECC code from line parity */
154: nand_trans_result(reg2, reg3, ecc_code);
最後、157 - 159 行目で、最終的な ECC データを生成します。
156: /* Calculate final ECC code */
157: ecc_code[0] = ~ecc_code[0];
158: ecc_code[1] = ~ecc_code[1];
159: ecc_code[2] = ((~reg1) << 2) | 0x03;
今まで計算してきた ECC データは、偶数パリティでした。
NAND ECC は奇数パリティなので、ビットを反転させます。
また、ECC データの 3 番目は、P4 がビット7, P1` がビット2 になるようにシフトされ、ビット1 とビット 0 は 1 とならなければいけないので、159 行目はそれもやっています。
これで、ECC 生成ロジックはおしまいです。
お疲れ様でした!
・・・
まだ、ECC 訂正ロジックが残っています。
ECC 訂正ロジックも、説明した通りのことをやっているのですが、こちらもちと手強くて・・・
生成ロジックに比べたら簡単なのですが。
162: /*
163: * Detect and correct a 1 bit error for 256 byte block
164: */
165: int nand_correct_data (u_char *dat, u_char *read_ecc, u_char *calc_ecc)
166: {
167: u_char a, b, c, d1, d2, d3, add, bit, i;
168:
169: /* Do error detection */
170: d1 = calc_ecc[0] ^ read_ecc[0];
171: d2 = calc_ecc[1] ^ read_ecc[1];
172: d3 = calc_ecc[2] ^ read_ecc[2];
173:
174: if ((d1 | d2 | d3) == 0) {
175: /* No errors */
176: return 0;
177: }
178: else {
179: a = (d1 ^ (d1 >> 1)) & 0x55;
180: b = (d2 ^ (d2 >> 1)) & 0x55;
181: c = (d3 ^ (d3 >> 1)) & 0x54;
182:
183: /* Found and will correct single bit error in the data */
184: if ((a == 0x55) && (b == 0x55) && (c == 0x54)) {
185: c = 0x80;
186: add = 0;
187: a = 0x80;
188: for (i=0; i<4; i++) {
189: if (d1 & c)
190: add |= a;
191: c >>= 2;
192: a >>= 1;
193: }
194: c = 0x80;
195: for (i=0; i<4; i++) {
196: if (d2 & c)
197: add |= a;
198: c >>= 2;
199: a >>= 1;
200: }
201: bit = 0;
202: b = 0x04;
203: c = 0x80;
204: for (i=0; i<3; i++) {
205: if (d3 & c)
206: bit |= b;
207: c >>= 2;
208: b >>= 1;
209: }
210: b = 0x01;
211: a = dat[add];
212: a ^= (b << bit);
213: dat[add] = a;
214: return 1;
215: }
216: else {
217: i = 0;
218: while (d1) {
219: if (d1 & 0x01)
220: ++i;
221: d1 >>= 1;
222: }
223: while (d2) {
224: if (d2 & 0x01)
225: ++i;
226: d2 >>= 1;
227: }
228: while (d3) {
229: if (d3 & 0x01)
230: ++i;
231: d3 >>= 1;
232: }
233: if (i == 1) {
234: /* ECC Code Error Correction */
235: read_ecc[0] = calc_ecc[0];
236: read_ecc[1] = calc_ecc[1];
237: read_ecc[2] = calc_ecc[2];
238: return 2;
239: }
240: else {
241: /* Uncorrectable Error */
242: return -1;
243: }
244: }
245: }
246:
247: /* Should never happen */
248: return -1;
249: }
169: /* Do error detection */
170: d1 = calc_ecc[0] ^ read_ecc[0];
171: d2 = calc_ecc[1] ^ read_ecc[1];
172: d3 = calc_ecc[2] ^ read_ecc[2];
170 行目から 173 行目までで、ユーザーデータから計算された ECC データと、ユーザーデータの後に付加されている ECC データの XOR を取っています。
174: if ((d1 | d2 | d3) == 0) {
175: /* No errors */
176: return 0;
177: }
計算 ECC と読み出し ECC がまったく同じなら、XOR は 0 になります。
これは、データがまったく化けていなかったケースですね。
174 行目は、その判定です。
この後は、いずれかのデータが化けたケースです。
179: a = (d1 ^ (d1 >> 1)) & 0x55;
180: b = (d2 ^ (d2 >> 1)) & 0x55;
181: c = (d3 ^ (d3 >> 1)) & 0x54;
182:
183: /* Found and will correct single bit error in the data */
184: if ((a == 0x55) && (b == 0x55) && (c == 0x54)) {
179 - 181 行目で、何やらビット操作をして、その値を使って 184 行目で判定をしていますが、この判定は、ユーザーデータが 1 ビットだけ反転しているケースか、もしくはそれ以外のケースかを判別しています。
なぜ、これでユーザーデータが 1 ビットだけ反転したということが分かるのでしょう?
179 行目の d1 ^ (d1 >> 1) の意味を考えてみましょう。
d1 の各ビットの意味は、次の通りです:
ビット 7: 計算 ECC と読み出し ECC の P1024 が不一致なら 1
ビット 6: 計算 ECC と読み出し ECC の P1024` が不一致なら 1
ビット 5: 計算 ECC と読み出し ECC の P512 が不一致なら 1
ビット 4: 計算 ECC と読み出し ECC の P512` が不一致なら 1
ビット 3: 計算 ECC と読み出し ECC の P256 が不一致なら 1
ビット 2: 計算 ECC と読み出し ECC の P256` が不一致なら 1
ビット 1: 計算 ECC と読み出し ECC の P128 が不一致なら 1
ビット 0: 計算 ECC と読み出し ECC の P128` が不一致なら 1
ユーザーデータが 1 ビットだけ反転しているケースでは、Pi と Pi` のうち、片方が一致し、もう片方が不一致になります。
[ビット 7, ビット 6], [ビット 5, ビット 4], [ビット 3, ビット 2], [ビット 1, ビット 0] の各組において、取りうる値は [1, 0] か [0, 1] だけです。
[1, 1] と [0, 0] はありません。
そうなったとしたら、他の化け方をしているケースです。
[1, 0] もしくは [0, 1] になっているかを判別するには、このビット同士で XOR を取ってみればいいですね。
[1, 0] もしくは [0, 1] ならば XOR 値は 1 になり、[0, 0] か [1, 1] ならば XOR 値は 0 になります。
179 - 181 行目のビット演算は、この XOR 計算をやっています。
この計算で、ビット 6, 4, 2, 0 のがすべて 1 になっているなら (= 0x55)、隣り合っているビット同士は、すべて [1, 0] か [0, 1] かのいずれかであると断定できます。
181 行目が、0x54 との比較になっているのは、ビット 6, 4, 2 だけを見ているからですね。
ECC データの 3 バイト目の下位 2 ビットは 1 固定になっているので、比較から排除しています。
・・・というわけで、171 - 184 行目により、ユーザーデータが 1 ビットだけ反転したケースか、それ以外のケースかが判別できます。
185 行目から 214 行目までが、反転ビットを探して、そのビットを反転させる処理です。
add が、反転ビットが何バイト目なのかを表す変数、bit が、そのバイトの中で何ビット目が反転しているかを表す変数であることに注意すれば、処理の意味は分かります。
a. 影響を受ける P のビット番号の合計 = データのビット番号
A. 影響を受ける P のビット番号の合計 = (dat の番号) * 8
にも注意しながら、見てみてください。
Pi` のビットを飛ばしながら、Pi のビットのみを見ていることが分かると思います。
ユーザーデータを正しく訂正した後、関数は終了です。
217 行目から 238 行目までが、ECC データが 1 ビットだけ反転したかどうかのチェックです。
ECC データが 1 ビットだけ反転した場合は、一つの Pi もしくは Pi` が不一致になり、それ以外の Pi/Pi` は一致になります。
d1, d2, d3 の 1 が立っているビットの合計が 1 であれば、ECC データが 1 ビットだけ反転したケースであると判別でき、ECC データを訂正して終了します。
それ以外のケースでは、訂正不可能なエラーであると判断して、-1 を返します。
・・・
ECC のコードは、理解するのは大変ですが、使う分には簡単です。
前回記事で、nand_program_page() を紹介しましたが、それには ECC 処理が入っていませんでした。
ECC 処理を追加すると、以下のようになります。
362: int nand_program_page(u_char *buf, int len, ulong addr)
363: {
364: int i, j;
365: u_char status = 0;
366: u_char *databuf = (u_char *)0x80000000;
367: int page_off = (int)(addr & (PAGE_SIZE - 1));
368: #ifdef NAND_16BIT
369: u16 *p;
370: page_off *= 2;
371: len *= 2;
372: #else
373: u_char *p;
374: #endif
375:
376: for (i = 0; i < page_off; i++)
377: databuf[i] = 0xff;
378: for (i = page_off, j = 0; i < page_off + len; i++, j++)
379: databuf[i] = buf[j];
380: for (i = page_off + len; i < PAGE_SIZE + OOB_SIZE - ECC_SIZE; i++)
381: databuf[i] = 0xff;
382:
383: #ifdef ECC_CHECK_ENABLE
384: for (i = 0, j = 0; i < ECC_SIZE; i += ECC_STEPS, j += 256)
385: nand_calculate_ecc(&databuf[j], &databuf[PAGE_SIZE + OOB_SIZE - ECC_SIZE + i]);
386: len = PAGE_SIZE + OOB_SIZE - page_off;
387: #endif /* ECC_CHECK_ENABLE */
388:
389: #ifdef NAND_16BIT
390: len /= 2;
391: #endif /* NAND_16BIT */
392:
393: NanD_Command(NAND_CMD_PROGRAM);
394: NanD_Address(ADDR_COLUMN_PAGE, addr);
395:
396: #ifdef NAND_16BIT
397: p = (u16 *)&databuf[page_off];
398: #else
399: p = &databuf[page_off];
400: #endif
401:
402: for (i = 0; i < len; i++, p++) {
403: WRITE_NAND(*p, NAND_ADDRESS);
404: }
405:
406: NanD_Command(NAND_CMD_PROGRAMSTART);
407:
408: while (1) {
409: status = nand_status();
410: serial_printf("[%s] status = 0x%x\n", __FUNCTION__, status);
411: if ((status & 0x60) == 0x60)
412: break;
413: wait_us_polling(1, 1000000);
414: }
415:
416: if (status & 0x01)
417: return 1;
418: else
419: return 0;
420: }
引数で受け取ったデータを書いた後、2048 バイト境界まで、元の値を変更しないように 0xff で埋め、ECC データ領域に ECC データを書き込みます。
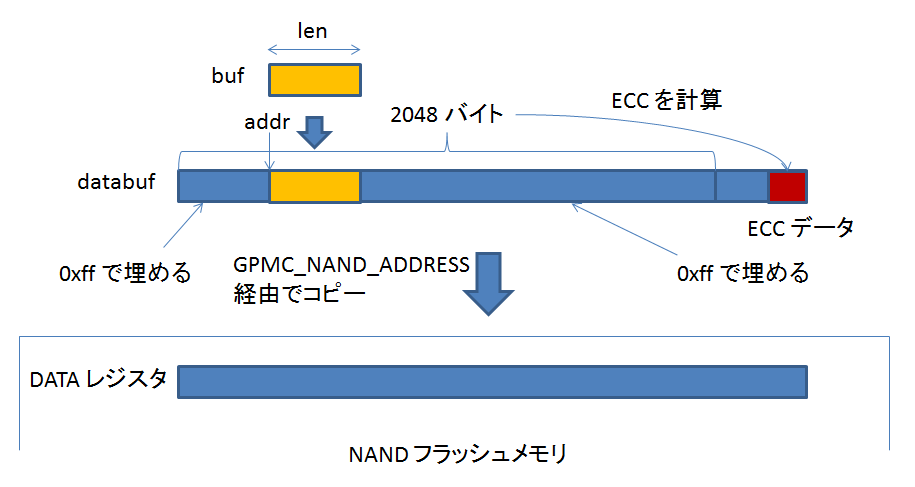
データ訂正関数 nand_correct_data() は、READ PAGE を行う関数に入っています。
READ PAGE 関数では、nand_calculate_ecc() も使っています。
nand_calculate_ecc() は、読み書きで使い、nand_correct_data() は読み出しで使う、ということですね。
beagle さん

-
nice! 5
記事 23
テーマ パソコン・インターネット
プロフィール
ブログを紹介する



https://clck.ru/FkugB - Знакомства Libertyville. Сайт знакомств Libertyville бесплатно, без регистрации, для серьезных отношений.
by ArabekLig (2019-05-01 20:53)
https://loveawake.ru - Знакомства Lamezia Terme. Сайт знакомств Lamezia Terme бесплатно, без регистрации, для серьезных отношений.
by Allencrash (2020-01-10 17:55)
https://loveawake.ru -
by Allencrash (2020-01-13 02:58)
https://loveawake.ru -
by Allencrash (2020-01-17 11:03)
https://loveawake.ru -
by Allencrash (2020-01-20 23:36)
https://loveawake.ru -
by Allencrash (2020-01-24 09:34)
Amoxil Dose For Dogs http://abcialisnews.com - Buy Cialis Cialis Le Moins Cher Immigrer Au Canada <a href=http://abcialisnews.com>п»їcialis</a> 30 Day Cialis 5mg
by Lesprealm (2020-02-05 08:53)
Levitra 10 Mg Costo <a href=http://apcialisle.com/#>п»їcialis</a> Horny Goat Weed <a href=http://apcialisle.com/#>Buy Cialis</a> Buy Tadalis Sx Generic
by Stepvam (2020-03-14 17:11)
Профессиональный монтаж напольных покрытий.Обращайтесь всегда рады вам помочь.
Мы делаем следующие работы
Монтаж напольного плинтуса из массива
Монтаж напольного плинтуса МДФ
Монтаж напольного плинтуса дюрополимер
Монтаж напольного плинтуса ПВХ
Монтаж напольного плинтуса ЛДФ
Монтаж потолочного плинтуса.
Монтаж напольного плинтуса из металла и т.д кроме камня.
Покраска плинтуса.
Монтаж напольных покрытий
Монтаж паркетной доски на подложку.
Монтаж ламината.
Монтаж винилового ламината
Монтаж инжинерной доски
Монтаж моссивной доски (с готовым покрытием)
Монтаж фанеры.
Монтаж галтелий и наличников.
По другим работам уточняйте!
гарантия на все виды работ.
Напилим.про
by napilim.pro (2021-03-28 06:03)